

335: Google vs Amazon Capital Allocation, WTF is Levelized Cost of Energy, Nvidia vs China, Canadian Oil, AI-Assisted Doctors, and Bruce Willis Deepfake Rights
"Seems *very* valuable to me"

I try to be very careful about who I steal from. Only steal from the best! —David Milch, interview
🤔 Substack has a new “pull quote” format 👆 I think I like it better for the intro quote, but I’m not sure. What do you think?
🔋🪫 ⌨️ 🖥🖱 All the way back in the Mesoarchean era of edition #57, I wrote about why I think anyone who has a desktop computer should get a UPS (I know almost everyone only has a laptop now, but I figure the ratio of weirdos with desktops is probably higher around here).
Not a United Parcel Service, but an Uninterruptible Power Supply — basically, a big power bar with a battery built-in, so that if there’s a power failure or a power surge, whatever’s plugged into it is protected and doesn’t go dark as you’re typing an important idea...
Well, my UPS was getting old, and the last time we had an extended power failure, I didn’t even have time to properly shut down my computer before it lost power. 😬
Clearly, the battery was knock, knock, knockin’ on heaven’s door, as Dylan would say (don’t say GNR, please!).
So for the first time, I went on Amazon and ordered a replacement battery, checked a Youtube video and downloaded a users’ manual PDF, and replaced the battery myself.
It was surprisingly easy.
It probably varies by model, but the biggest challenge was making sure not to touch both terminals at the same time (I wore bright yellow rubber gloves, because I’m a safety-conscious dork without real electrician security gear). Then one screw, and we’re back in business (after letting the new battery fully charge).
Much less expensive than a whole new UPS and should be good for years.
🦾🤖🦾🤖🦾🤖 What a small, inter-connected world!
I’ve been following an AI rabbit hole lately (well, for 15 years, but with varying levels of intensity), including playing a lot with generative models like Stable Diffusion.
Now I learn that my friend and supporter of this steamboat Jim O’Shaughnessy (💚 🥃) is now the executive chairman of Stability AI, the company that created Stable Diffusion! 🤯 (and they’re working on a lot more — I can’t wait to see what’s next!)
💚 🥃 🦉 If you feel like you’re getting value from this newsletter, it would mean the world to me if you became a supporter to help me to keep writing it.
If you think that you’re not making a difference by subbing, that’s incorrect. Less than 3% of readers are supporters (so far — you can help change that), so each one of you joining this elite group makes a big difference.
I like free stuff as much as the next person, but when I like something, I also want it to continue and be sustainable:
A Word From Our Sponsor: ⭐️ Tegus ⭐️

What makes a great investor isn’t pedigree or diplomas 🎓, it’s quality thinking and information 🧠
Tegus can’t provide the thinking for you, but on the information front, they’ve got you covered! 📚
With 25,000+ primary source expert calls covering almost any industry or company you may want to learn about, and the ability to conduct your own calls with experts, if you so choose, at a much lower cost than you’ll find elsewhere (70% lower than the average cost of ˜$400), this is the service to turbo-charge the depth and breadth of your knowledge 📈
⭐️ Get your FREE trial at Tegus.co/Liberty ⭐️
🏦 💰 Liberty Capital 💳 💴

How Google and Amazon capital allocation differs 👩🔬💰💸
Friend-of-the-show Byrne Hobart (💚💚💚💚💚 🥃):
I think this is a rough description of how Google and Amazon capital allocation differs.
These can both be viable strategies!
The unseen cost of launching lots of small stuff is that some things only work at scale. The cost of Google's approach, that some things fail at scale, is harder to see. And yes, exceptions on both sides, but this seems to be the tendency.
It makes some intuitive sense to me.
That yellow line probably has a visible bump somewhere for the Fire Phone, but it wasn’t a big deal in the grand scheme of things — in fact, as Amazon has gotten so much bigger since then, I’m surprised that the size of their visible R&D mistakes doesn’t seem to have increased too much (you can argue the capex overbuild during the pandemic was mistake, but it’s a different kind, IMO).
I wonder if the size of Google’s failures (‘failure’ isn’t meant to be something negative in this context — when you try ambitious things, most will fail) keeps going up over time or if we’ve seen peak ‘science experiment’ era for the company and it’s headed down from here 🤔
(how much of that approach comes from the founders, and as they step further back, what is the half-life of their preferences within Google’s culture?) GOOG 0.00%↑ AMZN 0.00%↑
Meanwhile everybody else:

🤔💡😮 WTF is ‘Levelized Cost of Energy’ and why does it matter?
Matt Loszak explains something *very* important (full thread here, highlights below):
Millions of people mistakenly believe that Solar is now our cheapest option for powering the grid.
What's misleading them?
A sneaky metric known as LCOE.
Levelized Cost of Energy, or LCOE, is the total cost of a project, divided by the total energy that it produces in its lifetime.
If you build a field of low-cost solar panels that produce a lot of energy over their lifetime, it's a low LCOE and a great investment, right?
What LCOE ignores, is the cost of unreliability.
While it might selfishly be a good investment for a solar developer, it could be a terrible investment for the grid, and society at large.This last part is the crux: It’s very possible to make investments that make a ton of sense *at the project level* but that don’t make sense when you look at things *at the grid level*.
Matt makes an analogy: two internet ISPs, one is cheaper than the other, but only works during the day, and sometimes when it’s cloudy download speeds can drop by 80-90%.
Like with batteries for solar, he makes the analogy that you could mitigate that problem at the ISP with storage (buy lots of hard drives, download stuff during the day, cache content, etc), but all this extra storage also has costs that should be factored in.
But the biggest problem is the unpredictability.
You can’t be sure how much storage you need, because sometimes the clouds only come for a few hours, and sometimes they may stick around for a week or two (or three!).
So if you have only a little bit of storage, its utilization will be really high so the ROI on it is amazing. But you’ll also run out of storage fairly frequently and have to deal with having no access to what you need (internet/electricity).
If you build a lot of storage, you almost never run out of it, but during most of the time this extra storage will be idle because there can be long periods in between the weeks-of-clouds, so the utilization and ROI on it are very low.
It’s a bit of a catch-22.
Matt continues:
Oil and gas companies love renewables.
Today, renewables are always backed 1:1 by oil-and-gas based generators, to fill gaps.
In the future, solar purists propose mega storage, and overbuilding (extra panels) as the solution.
These extra costs aren't factored into LCOE.
When the cost of unreliability is considered, solar no longer looks like a silver bullet.Matt goes deeper in the math to figure which mix of power sources may work best.
I think too few people look beyond the headline numbers on things (wow, solar costs 4 cents per kWh and we just added XYZ GW of it! We can stop worrying about the future of the grid…).
Even capacity numbers on solar and wind projects are often taken at face value, when actual production is more in the 25-35% range.
You may pay more for a nuclear power plant, but you also GET MORE. It’s just that a lot of what you get isn’t easy to put a price on… until you really need it. How many nuclear power plants could’ve been built/refurbished for the societal costs of Europe’s energy crisis right now (with a lot more to come this winter, and over coming years, because it won’t be over quickly)?
To repurpose a phrase: Energy is like oxygen — it’s when you don’t have enough…
I mean, what's the value of not having wild swings with the weather? Of not having to pray for a mild winter? Of not being dependent on Putin for gas? Of not having large industries that can’t easily stop-and-start having to possibly permanently shut down because energy supply is too uncertain and expensive?
Seems *very* valuable to me, even though the value isn’t always reflected in the average cost per kWh or in LCOE. /end rant
⚾️ ‘Nvidia Backlash and the China Conundrum’ 🏀

I’ve been enjoying Ben Thompson (💚 🥃 🎩) and Andrew Sharp’s new podcast. I’ll highlight this episode because I think it touches on a lot of interesting things (US tech vs China, Nvidia, TSMC, AI, etc):
I’m looking forward to seeing how the pod evolves over time, but solid start! 🏇 NVDA 0.00%↑
Canadian Oil Imports as % Total U.S. Oil Imports 🇨🇦🛢🛢🛢

OPEC oil imports to the U.S. went from 80% of imports in the mid-1970s to about 15% today. During that time, Canada steadily rose to become around 60% (partly because absolute size of imports went down). Source.
🧪🔬 Liberty Labs 🧬 🔭
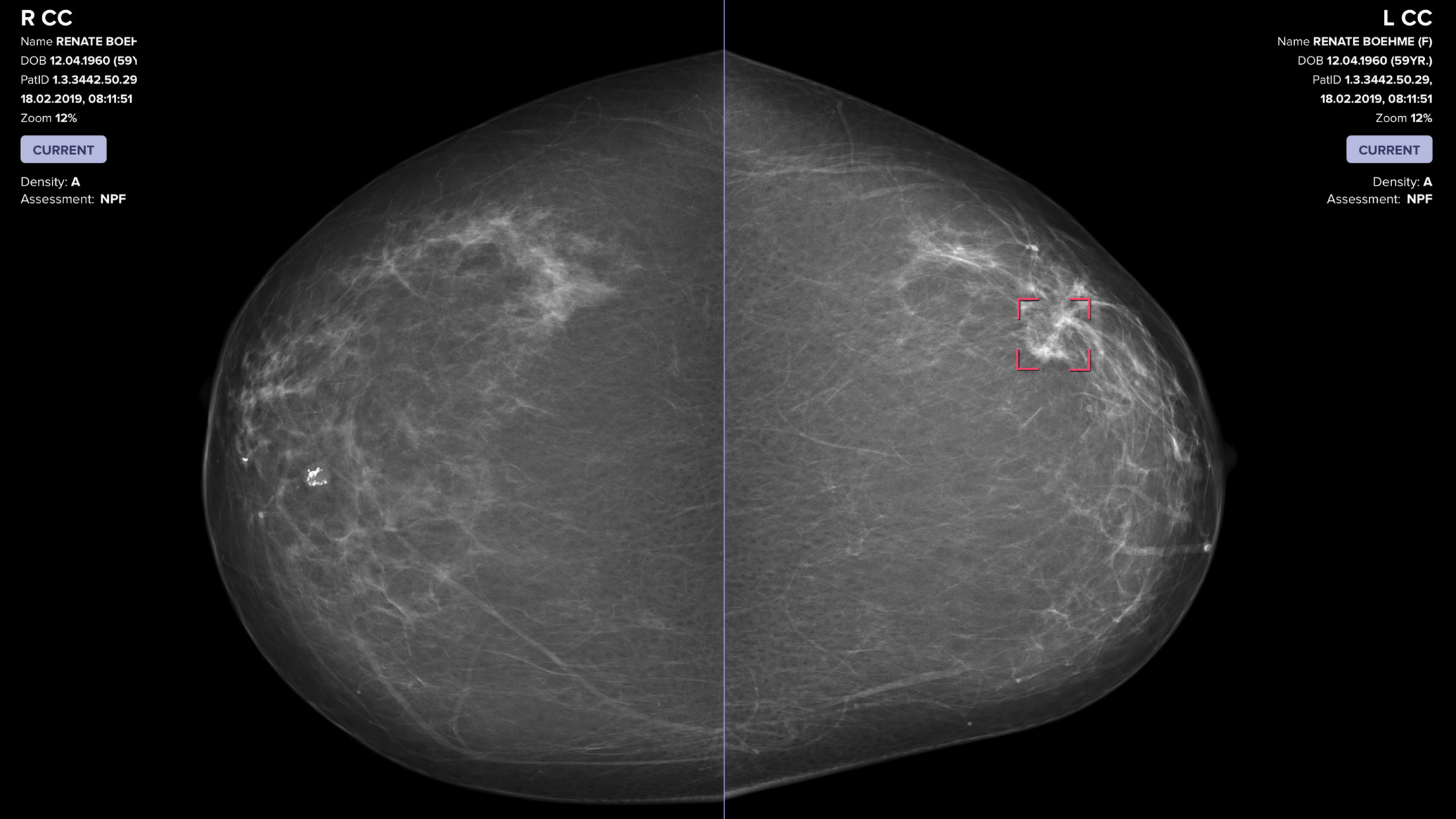
The era of AI-assisted medical diagnosis 🩻🤖👩🏻⚕️
“It might be a while before AI replaces doctors, but doctors using AI will replace doctors that don’t quicker than we think”
Some highlights from a couple pieces shared by Michael Dempsey:
AI Matches Doctors in Screening for Tuberculosis
Apart from COVID-19, tuberculosis (TB) is the leading cause of death by an infectious disease worldwide, despite being largely preventable and treatable. While the World Health Organization (WHO) recommends using chest X-rays to help identify likely cases of TB, many health-care centers lack adequate radiologists to interpret these X-rays.
In a study published on 6 September in the journal Radiology, researchers at Google along with colleagues from India, South Africa, and Zambia showed that their deep-learning algorithm could identify cases of TB from chest X-rays as well as radiologists could.
Here’s something very interesting about it:
The algorithm sorts the images into three categories: normal, TB, or abnormal but not TB. As a result it could potentially help even patients who might not have TB but still require medical care. (Source)
This model was trained on 165,000 chest X-ray images from 22,000 patients. Knowing how capabilities tend to scale with data, I wonder what a model trained on 1 million X-rays may be able to do — when does it get much better than the average radiologist?
A second piece:
Radiologists assisted by an AI screen for breast cancer more successfully than they do when they work alone, according to new research. That same AI also produces more accurate results in the hands of a radiologist than it does when operating solo.
What’s interesting is that there’s already plenty of historical data laying around that can be used to train these models:
To train the neural network, Vara fed the AI data from over 367,000 mammograms—including radiologists’ notes, original assessments, and information on whether the patient ultimately had cancer—to learn how to place these scans into one of three buckets: “confident normal,” “not confident” (in which no prediction is given), and “confident cancer.”
OpenAI’s new open-source language model for transcriptions and translations 🤖🗣📝
A bunch of human transcribers and translators just moved one step closer to updating their resumés (or leveraging this tool to do way more work than they could before…).
Whisper is an automatic speech recognition (ASR) system trained on 680,000 hours of multilingual and multitask supervised data collected from the web.
We show that the use of such a large and diverse dataset leads to improved robustness to accents, background noise and technical language. Moreover, it enables transcription in multiple languages, as well as translation from those languages into English.
We are open-sourcing models and inference code to serve as a foundation for building useful applications and for further research on robust speech processing.
The demos are impressive, showing what the model can do on audio with a lot of background noise, echo, accented speakers, transcribing and translating at the same time…
I’m certainly looking forward to transcripts of podcasts and earnings calls to be more accurate and have fewer “WTF did he really say here?” moments!
🎨 🎭 Liberty Studio 👩🎨 🎥
Butch Cassidy & the Sundance Kid — That oughta do it 🤠 💥
My friend SB was over, and it randomly came up that he hasn’t seen the film Butch Cassidy and the Sundance Kid.
I showed him this scene, and that moment (you’ll know when you see it) had him laughing hysterically. Hopefully you enjoy it too!
🎥 🎬 🤖 Bruce Willis sells ‘deepfake rights’ to allow digital twin on screen
Back in edition #333, I wrote about James Earl Jones selling the rights to his Darth Vader voice performance to be generated using AI.
That was just the beginning:
Bruce Willis has become the first Hollywood star to sell his rights to allow a “digital twin” of himself to be created for use on screen.
Using deepfake technology, the actor appeared in a phone advert without ever being on set, after his face was digitally transplanted onto another performer.
Willis allowed US firm Deepcake, which makes “digital twins”, to use his face.
The Russian telecom ad isn’t very ambitious with the tech and — to me anyway — it’s still in the uncanny valley. But there’s no doubt of where things are going (especially after the last few years, with Admiral Tarkov brought back from the dead, Al Pacino and Robert DeNiro made younger in the Irishman, etc).
In Willis’ case, there’s the added tragedy of his aphasia diagnosis, which cut short his career (and probably pushed him to take almost any role during the last part of it because he knew he soon couldn’t work).
Imagining the perfected version of this technology does make me wonder about some of the great art that can be done with it, but also the nefarious uses.
It’s truly an arms race, because as deepfakes get better, the tech to detect deepfakes also needs to get better — but this can’t continue forever, there’s an upper bound — once things are basically indistinguishable from just a regular video of a person, where do you go from there?

I'm sure you've seen this, but thought this was an interesting article on the usefulness of hydrogen
https://noahpinion.substack.com/p/i-come-bringing-good-news-about-hydrogen
The era of AI-assisted medical diagnosis- 😀👏👏😁🙏👍💐