

346: Generative AI + Advertising, AWS Growth, China & USA Decoupling, GlobalFoundries, FBI, Satellites, and Amadeus
"Either you win or you learn, you never lose."

Don't be stopped by the "if you can't define it and measure it, I don't have to pay attention to it" ploy.
No one can define or measure justice, democracy, security, freedom, truth, or love. But if no one speaks up for them, if systems aren't designed to produce them, and point toward their presence or absence, they will cease to exist.
―Donella H. Meadows, Thinking in Systems
♟My 8yo son used to be a bit of a sore loser when he was younger, which is normal at a certain age (though many people never grow out of it, tbh).
He’s much better at it now. In fact, he’s a more gracious winner too.
One thing that may have helped is this thing I taught him, and that he now often says unprompted (a good sign he’s internalized it):
Either you win or you learn, you never lose.I think I got this phrasing from Jocko’s Warrior Kid books, but however you say it, it’s the central idea behind having a growth mindset as opposed to a fixed mindset.
How you approach adversity makes a huge difference in how much you’ll seek out deliberate practice and learning. If you believe that you can keep improving and get better vs if you implicitly believe that however good you are at something is “just the way things are” and won’t change.
🥕🌽 🐈 🐩 Something that too few people realize: Pretty much all crops are genetically modified. Same for all domesticated animals (dogs and cats didn’t just appear naturally, they’re *human creations*).
We’ve been at it for thousands of years, and through selective breeding and cross-pollination, we’ve largely replaced natural selection for a large number of species and chosen the phenotypes that we like and created a human-guided selective pressure to amplify these genetic traits.
Pre-agriculture/ancestral carrots and corn and potatoes and wheat weren’t anything like what we’re eating today (they were tiny), or even what our grandparents were eating (before Watson and Cricks figured out what DNA was like 🧬).
We’ve also taken the ancestors of dogs and housecats and many other species and reshaped them, sometimes wildly (compare a Chihuahua or a Dachshund to a wolf 🐺).
ie. Why are kittens and puppies so cute to humans? Well, if you have humans favoring the cutest animals from each litter and they all breed with each other for thousands of generations, you get pretty damn cute offspring!
It’s true that modern tools allow much more control and precision, but they’re not an altogether new thing, so when some people pretend that there “GMOs” over here and “non-GMO” over there, they’re lacking context.
We should focus on what truly matters — is a thing beneficial, healthy, ethical, harmonious with its environment, etc — rather than whether is it “natural”, which is a pretty meaningless concept that can be used to mean almost anything (usually as marketing for some product someone wants to sell you), and to reject significant innovation and preserve terrible situations.
Let’s fix the problems with modern agriculture — and there are plenty of real problems — but keep the good.
🦠🔗…🔗🧓🏻👴🏻🤰🏻👶🏻 When you’re feeling a bit down, or like the adversity is too much, remember that you come from an unbroken line of ancestors that go all the way back to the first unicellular and pre-cellular life-forms! (likely RNA-based)
That’s *a lot* of individuals that had to find a way to power through *a lot* of challenges.
💚 🥃 The show must go on, but it can only do so thanks to paid supporters like you!
A Word From Our Sponsor: ⭐️ Tegus ⭐️

What makes a great investor isn’t pedigree or diplomas 🎓, it’s quality thinking and information 🧠
Tegus can’t provide the thinking for you, but on the information front, they’ve got you covered! 📚
With 25,000+ primary source expert calls covering almost any industry or company you may want to learn about, and the ability to conduct your own calls with experts, if you so choose, at a much lower cost than you’ll find elsewhere (70% lower than the average cost of ˜$400), this is the service to turbo-charge the depth and breadth of your knowledge 📈
⭐️ Get your FREE trial at Tegus.co/Liberty ⭐️
🏦 💰 Liberty Capital 💳 💴
🤖 Using generative AI to create an endless flood of customized/targeted advertising & social media posts 🤔😬
It’s clear that we’re on the cusp of a big wave of digital advertising created, and likely customized, using generative AI tools (for images, text, audio, and video).
Some uses of this may be fairly benign, like using the context around an ad to try to improve targeting.
f.ex. If you’re showing an ad on a Crossfit blog, maybe the ad can be customized to better match the content, while the ‘same’ ad campaign could have different graphics on a blog about cycling. A human-made ad campaign may not have different versions of the ad to match every fitness sub-community, but a ‘dynamic’ AI-assisted ad potentially could.
Ok, that’s not too bad. But…
Tools already exist that allow marketers to generate social media posts, “SEO” blog posts, and all kinds of other stuff with minimal effort.
It used to be fairly easy for anyone with a good BS detector to know which reviews were real and which were probably fake on sites like Amazon, but soon enough, it’ll be close to impossible. Comments on Youtube videos, user film reviews on IMDB, discussion forum posts…
Pretty soon everything could be part of a multi-platform mechanized-astroturfing marketing campaign to “create buzz” around some product or media.
Billy (@William_g_ray) writes on Twitter:
In 20 years, people will view content created before 2021 as pure and untainted by GPT. They will mine it in the same way that pre-WWII steel is salvaged from shipwrecks for Geiger counters because they aren't tainted by nuclear fallout.
Search results probably tainted already.While I don’t think the steel analogy is quite correct anymore, the general idea has some merit.
Over time, won’t we create a kind of feedback loop where more and more of the large language models are trained on internet content that was itself generated by large language models..? 🔁 😬
It’s easy to think that we’ll simply have counter-measures — let’s make some AI models that can detect content generated by AI! — but this isn’t easy to do for fundamental reasons.
Any model that is capable of detecting something created by an AI contains in itself the requisite information to make a model that is capable of fooling the detector.
Is it possible that the detection side will always stay ahead of the deception side?
It seems to me like the incentives and rewards are bigger on the deception side than the detection one, so it may be very difficult to always stay one step ahead.
What about the ethical considerations of having marketing firms pump out millions of social media posts and blog articles with fictional authors about things that never happened (testimonials of customers using a product and being really satisfied with it, elaborate stories from people living the van life that in the end only exist to market some product that is mentioned in the story, etc).
There’s probably going to be plenty of ‘long cons’ where fake people post for months or years on social media and forums to build up a real-looking account with a reputation, but they’re actually just AIs trying to market some product (drop it in conversation once every 100 posts, nobody will suspect a thing).
Also, won’t it become progressively harder for the human editors of Wikipedia to protect the site against attacks from the countless groups who are trying to get their point of view into a reference source? They can even create fake third-party references that they then link, and fact-checkers may have a hard time untangling it all…
Someday, fake things may be more convincingly documented than real things!
AWS Growth Rate Over Time (FX-neutral)
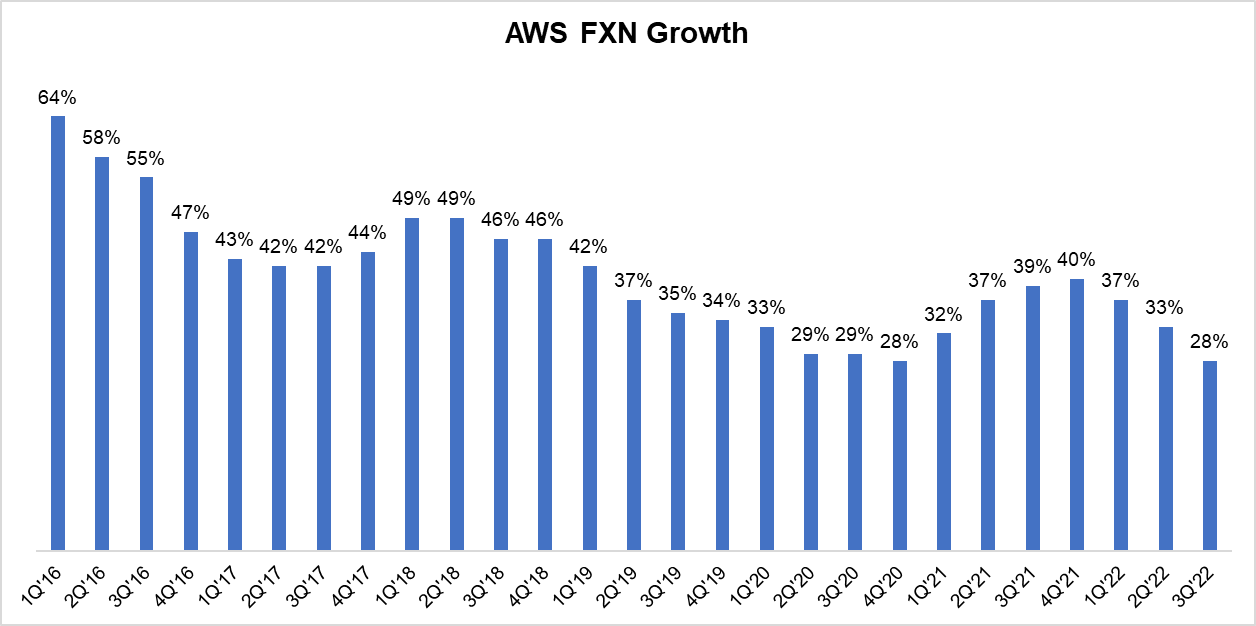
My friend MBI (💎🐕) wrote an overview of Amazon’s Q3 results and included this graph.
This growth should be kept in the context of an $82bn run rate with a backlog of $104bn (+57% YoY) 🤯 AMZN 0.00%↑
🔌 GlobalFoundries to become an electric utility in Vermont to lower its electricity bill ⚡️
Chip foundries use a lot of power.
As I wrote about in edition #321, TSMC uses 1/8th of Taiwan’s electricity and the new ASML EUV machines are even more power-hungry, using about 1 megawatt per machine (10x more than the previous generation).
GlobalFoundries isn’t TSMC and isn’t doing EUV, but it still needs a lot of power — so why not cut the middlemen?
[Vermont] State regulators have cleared the way for GlobalFoundries, the Essex Junction semiconductor manufacturer, to set up its own electric utility — allowing the company to buy most of its power directly from ISO New England, the regional grid operator, rather than from Green Mountain Power. [...]
GlobalFoundries is Green Mountain Power’s biggest customer. To offset the loss, GlobalFoundries plans to continue buying electricity from Green Mountain Power over a four-year transition period, and will also pay the electric utility a “transition” fee of $15.6 million. (Source)
Not too surprising to see them do this, considering they pay almost 45% more per kWh in Vermont than they do at their Fishkill plant in New York.
GF’s Vermont fab uses 381.2 million kilowatt-hours per year, or about 8% of Vermont’s electricity.
Via supporter Luke C. (in the private Discord for supporters) GFS 0.00%↑ TSM 0.00%↑
🇺🇸💔🇨🇳 China & USA: The Great Decoupling
I’m no expert on China, geopolitics, or macroeconomics, but the changing world-order is worrying.
Noah Smith (🐇) has a good piece about the tectonic change that has been gaining momentum lately:
I have no idea if he’s right or not, or maybe missing important nuances. And of course, this unpredictable, complex adaptive system that is the world will throw us more curve balls. But he does make some convincing arguments.
I’m a big fan of win-win, non-zero-sum, cooperative games that create abundance and allow as many people as possible to live fulfilling lives.
Seeing us headed in a direction that likely means more conflict and more lose-lose, zero-sum games is quite sad.
Related:

This may be a good proxy for both transparency and economic health.
Real-world example of an information cascade, Crossfit Edition 🇧🇷🏃🏻♀️🏃🏾🏃♂️
Information cascades occur when external information obtained from previous participants in an event overrides one's own private signal, irrespective of the correctness of the former over the latter.
(you may have to click on the tweet above to see the embedded video from a security camera)
🧪🔬 Liberty Labs 🧬 🔭

🌎 Low Earth Orbit Visualization 🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰🛰
There’s a lot of stuff in orbit — this interactive visualization is a great way to explore the skies and get a sense of what we’ve sent up there.
In the search field you can look for specific orbital objects. I suggest “Starlink” to see the current constellation.
There’s also a slider where you can increase the speed of the simulation — put it to 1000 to see the glorious celestial ballet that is ongoing above our heads 24/7!
If you’re wondering what the red sections are:
LEOlabs operates its own radar systems that point upwards-ish. The "beams" you see are the fields of view of their radars. When an object crosses that field of view going at orbital speeds, LEOlabs tracks it and uses the partial trajectory information to figure out the orbit of the object. From there, it can potentially associate that object with existing objects in its own and other databases (the US Space Force, which operates its own radars, is one of the best-known).Report on microscopic hair analysis used as evidence by the FBI in criminal investigations 💇🏻♂️🔬👮🏻♂️🚔
Twenty-six of 28 FBI agent/analysts provided either testimony with erroneous statements or submitted laboratory reports with erroneous statements. The review focuses on cases worked prior to 2000, when mitochondrial DNA testing on hair became routine at the FBI.
26 out of 28 is 92%!
“These findings confirm that FBI microscopic hair analysts committed widespread, systematic error, grossly exaggerating the significance of their data under oath with the consequence of unfairly bolstering the prosecutions’ case,” said Peter Neufeld, Co-Director of the Innocence Project, which is affiliated with Cardozo School of Law. “While the FBI and DOJ are to be commended for bringing these errors to light and notifying many of the people adversely affected, this epic miscarriage of justice calls for a rigorous review to determine how this started almost four decades ago and why it took so long to come to light.
If you haven’t seen the documentary series ‘The Innocence Files’, it’s worth checking out (I wrote about it in edition #19) to help calibrate yourself on how weak, unscientific evidence can often put innocents behind bars and keep being used for years and years even after reasonable doubt has been raised about it’s effectiveness (here’s a piece about bitemark analysis).
The government identified nearly 3,000 cases in which FBI examiners may have submitted reports or testified in trials using microscopic hair analysis. As of March 2015, the FBI had reviewed approximately 500 cases. (Source)
So that’s FBI. But hasn’t similar evidence been used it lots more non-FBI cases pre-2000? What a SNAFU…
🎨 🎭 Liberty Studio 👩🎨 🎥

🎭 🎬 Amadeus (1984) 🎶 🎻
On Friday, I watched the film ‘Amadeus’ (1984) for the 3rd time. I enjoyed it as much, if not more than the previous times. Always a sign of a good movie when that happens.
There’s much to like here. The music is, of course, immortal, but the writing, the performances, the cinematography, the period costumes and the production! It’s a timeless piece that could’ve come out this year rather than almost 40 years ago (except for the fact that we rarely make films like this anymore…).
If you haven’t seen it, I highly recommend it (I’ve only seen the theatrical cut. There’s also an extended director’s cut that apparently changes a few plot points. I can’t vouch for it).
And if you have seen it, I recommend this hour-long video about how the film was made. If that’s too much for you, at least check out the last 10 minutes. They’re about the amazing scene where Salieri transcribes the requiem for Mozart.
That CrossFit video 😂
On the GMO bit, sounds like you've been reading the excellent "guns germs steel" by Jared Diamond