

403: Anti-Dystopian Credo, GPT-4 vs Google Bard, Gordon Moore, ARM's Massive Price Hike, Nintendo, Semiconductors and Classical Music
"There’s nothing passive about Moore’s Law."

Behind the mountains there are more mountains.
—Haïtian proverb

🔮💭👍 There’s an idea that I keep dancing around and coming back to in my writings and podcasts lately:
Anti-dystopian
Although I’m naturally optimistic, I’m not utopian. In fact, I can’t help but see the risks and dangers of many things.
But I also strongly believe that as individuals and as a civilization, we’re limited by vision, not by talent.
Whatever we build starts out with a dream of what it could be, so we need more positive dream generators. More visionaries who can make people excited about something and want to work together to turn vision into reality.
What makes this hard is that fear is the strongest human emotion.
It’s a lot easier to spin up a negative or even dystopian vision than a positive one, because most people are predisposed to believe it.
Cynicism usually sounds smarter than optimism, but almost everything gets built by optimists. If everyone believes the world is going to crap, it’ll probably be a self-fulfilling prophecy.
The problems we’re facing are obvious and their solutions aren’t — or at least they’re hard, because if they were obvious and easy, we wouldn’t have those problems in the first place. 🔄
Fear tends to lead to a passive posture.
While trying to sell utopia may be a bit too much given the inherently chaotic nature of our world and the imperfections of humanity, being anti-dystopian and trying to forge a future we truly desire and want to live in holds immense value.

🪦🐜 Gordon Moore has died. He was 94. He co-founded Intel in 1968 after leaving Fairchild Semiconductor. If you’ve heard of “Moore’s Law” — and who hasn’t? — that was coined by him.
Reflecting on his life, there are probably few people who ever saw their predictions be quite so right — and well, to be fair, it wasn't just a prediction, it was also a target and a guide, so he helped make it happen.
There’s nothing passive about Moore’s Law.
Now that we are living through a new dawn for AI just as the traditional Moore’s Law has been running out of steam, I can’t help but wonder if in the same way that Moore’s Law gave us the power needed for AI, if AI tools won’t give us the power to extend Moore’s Law by solving some of the problems that are making it so difficult to keep improving the price/performance of semiconductors at the kind of pace that we used to. 🤔
From a HN comment:
I once got the opportunity to ask Gordon Moore a question, 'what is the equivalent of Moore’s Law for software?' His response: 'The number of bugs doubles every year'. Great man.Friend-of-the-show and supporter (💚 🥃 ) Doug O’Laughlin has a very nice tribute to Moore. Here’s a highlight:
Opting into Moore’s law was a choice, an internal compass to push the world forward. And by giving the world a broad roadmap to improve upon, companies could make bold bets on an advancing world.
🛞 Life Pro-Tip: Before getting into a car, always look at the tires.
It’s *much* better to spot that something is wrong before you drive away…
This is also a good lesson on applied probabilities: Something being random doesn’t mean that the instances will be evenly spaced out. I had zero flat tires in 15+ years of driving, then I had 3 flat tires within about a year. ¯\_(ツ)_/¯
(not that I’m saying flat tires are really random. f.ex. if there’s more construction in your area, you’ll have higher odds of nails and screws on the road, etc. Just making a general point…)
💚 🥃 This is a special Free Edition. I just wanted a few of the ideas in this one to spread more widely. Have a good week!
🏦 💰 Liberty Capital 💳 💴
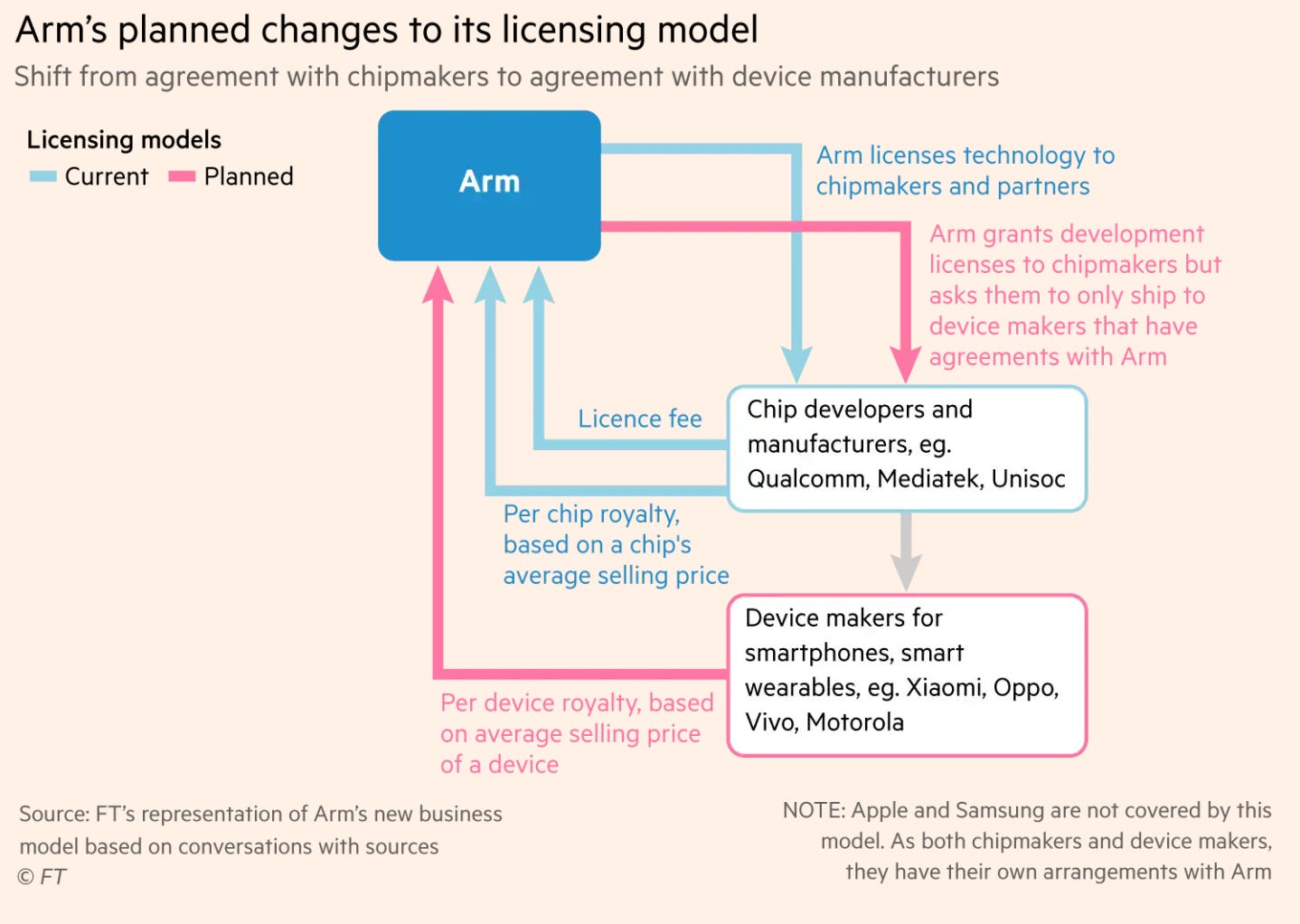
🇬🇧🐜 ARM Set to Boost Chip License Prices Dramatically
Good thing ARM customers pressured regulators to block the Nvidia acquisition because they were afraid of what may happen… 👀😅
Arm is seeking to raise prices for its chip designs as the SoftBank-owned group aims to boost revenues ahead of a hotly anticipated initial public offering in New York this year. [...]
Arm planned to stop charging chipmakers royalties for using its designs based on a chip’s value and instead charge device makers based on the value of the device. This should mean the company earns several times more for each design it sells, as the average smartphone is vastly more expensive than a chip.
This sounds like Qualcomm’s strategy of extracting rent based on the price of the whole device, which never felt right to me.
It appears unjust to insist on a share of the overall profit, even for parts of the product you haven't contributed to (which is another reason why I’m not a big fan of Apple and Google's exorbitant App Store fees).
By pushing too aggressively, ARM risks paving the way for RISC-V open-architecture chips to emerge from below as the new low-power standard ISA.
It may have happened over time anyway, but as long as ARM chips are cheap and perform well, there’s little incentive to invest substantial R&D into adopting a new architecture. However, if Apple is compelled to pay royalties proportional to the average price of every Mac, iPhone, and iPad sold, they might begin exploring alternative options more seriously.
“Arm is going to customers and saying ‘We would like to get paid more money for broadly the same thing’,” said one former senior employee who left the company last year. “What SoftBank is doing at the moment is testing the market value of the monopoly that Arm has.” [...]
Arm has also become more aggressive in pushing price increases within its existing sales model for royalties and licences over the past year, particularly for customers making chips for smartphones, where it has a dominant market position, according to people with knowledge of the recent moves. [...]
“The [royalty] amount will be at least several times higher than what Arm gets now,” said an executive from a leading Chinese smartphone maker which has so far refused to back the proposed plan. “We are told that they hope such changes could start from 2024.” (Source)
It seems to me like Nvidia could *never* have gotten away with doing something like that, but who knows ¯\_(ツ)_/¯
🙊🔑 Precious mistakes — Mistake Judo 🥋
There are many ways to look back on your mistakes. Some are more productive than others.
I try to make some lemonade out of those lemons to avoid bigger mistakes later.
While at the time the mistake may have seemed like purely a loss, over the long arc of time, it may have a net positive value if you play your cards right.
Of course, this doesn’t mean that you should make mistakes on purpose just to learn — it’s still best to learn from other people’s mistakes, which is why you should study history and the lives of those who did things.
However, since missteps are inevitable in life, it's crucial to extract as much value from them as possible, squeeze every bit of learning that you can, and imprint on them as much as possible (write them down, review these notes periodically, talk about your mistakes with friends & colleagues or publicly, etc).
It’s like mistake judo: transform setbacks into opportunities for growth
LLM: “Language” just means “patterns” + “Inference in everything” 🤖🔎🌎
You keep using that word. I do not think it means what you think it means….
We have recently become very familiar with the term “Large Language Model”, but I think most people aren’t thinking of the use of the word “language” in quite the correct way.
It’s true that these models are mostly trained on human language, and human language is the majority of their output. But there’s nothing in the technology that says the training has to be done on human language, or that the output has to be.
We’re already seeing that with the way the models can write computer code in various languages (Python, JavaScript, Perl, C++, whatever), but many other things can fit this broad definition of “language”, which essentially boils down to the patterns in the data.
Here’s a highlight from a recent excellent interview that Ben Thompson (💚 🥃 🎩) did with Nvidia CEO Jensen Huang:
When I was explaining the transformers, these large language models, it’s first learning the language of humans, but it’s going to learn the language of everything, everything that has structure. So what has structure? Well, it turns out the physical world has structure, that’s why we’re symmetric, that’s why when I see the front of Ben, I have a feeling about the back of Ben.
Ben: You had an extensive bit on physics a couple of GTCs ago I think that was trying to make this point, but now people get it.
JH: Yeah, and there’s a language to proteins, there’s a language to chemicals, and if we can understand the language and represent it in computer science, imagine the scale at which we can move, we can understand, and we can generate. We can understand proteins and the functions that are associated with them, and we can generate new proteins with new properties and functions.
From the same interview, there’s a different thing I’d like to highlight about “inference everywhere”:
JH: Inference will be the way software is operated in the future. Inference is simply a piece of software that was written by a computer instead of a piece of software that was written by a human and every computer will just run inference someday. Every computer will be a generative AI someday. Why look up an answer if you already know the answer? Every question that you ask me, if I have to go look it up or go find a bunch of friends and caucus and then come back and give you the answer, that takes a lot more energy than what’s already in my brain, and just call it 25 watts. I’m sitting here producing answers all day long —
Ben: Producing answers for the last hour, which I appreciate!
JH: Right, so this is completely generative AI. Generative AI is the most energy-conserving way to do computing, there’s no question about that. And of course the question is when can we do that on a large scale? Well, Ben, back in the old days, in order to run OpenGL, it started out in the data center in a Reality Engine, and then it was $100,000 – $150,000 workstation and now you’ve run OpenGL on a phone. The same exact thing is going to happen with inference.
Today, large language models, the largest ones requires A100 HGX to run, so that’s a couple of hundred thousand dollars. But how long would it be before we can have smaller versions of that, and quite performant versions of that running on cell phones? No more than ten years. We’re going to run inferences literally everywhere of all different sizes. Distributed computing is very cost-effective, it’s not going to go away. However, in the future, you’ll do some inference on the phone, you’ll do some inference on your PC, but you’ll always have the backup, you’ll always be connected to a cloud model which is much more capable as a backup to the smaller version on the device and so I have a lot of confidence that today’s computing model is going to remain.
Sounds like Apple’s silicon advantage may help them in that world 🍎💻📱🤖
AI: B2C vs B2B 🤔
I like this tweet by Jeremiah Lowin:
In B2C, AI is all about “small to big”: given a relatively simple prompt, generate an image, essay, code, etc.
In B2B, AI is all about “big to small”: given a vast amount of proprietary data/knowledge, distill relevant and actionable insights.
Require very different approaches.I think I had a fuzzy view that it was the case, but this clarified it for me.
🇯🇵🕹️ Acquired: Nintendo (the early years) 📈📉💣📈
What a great episode from two master storytellers at the top of their game!
Don’t go into it expecting to hear about Mario and Zelda from the start, though!
Nintendo was founded in 1889, so there’s plenty of history to cover, and it really helps to understand the context in which it grew into the special company that we know today (the boom-bust cycle of early arcade and console gaming is incredible!).
I love how Ben and David (💚 🥃) take their time and provide a ton of great context in the first segment, tying together many past episodes (Atari! Steve Jobs!).
That’s a real strength of having been doing Acquired for that long: episodes aren’t just about one thing, they’re part of a richer tapestry that they’ve been weaving for a while, and it’s these connections and callbacks that help us better understand these histories.
Anyway, enough of me blabbing, check it out:
I can’t wait for part 2 on the more recent history of Nintendo.
🧩 Interview: Primer on semiconductor industry, ASML, TSMC, is Moore’s Law dead?, Nvidia, etc. 🐜
Really fun conversation between supporters and friends-of-the-show Shomik and Doug (💚💚 🥃 🥃) :
It’s an excellent primer/overview of the space and adjacent fields (ie. the software ecosystems around the hardware, semicap stuff that helps build the fabs, etc).
If you’re new to the space, it’ll give you an idea of how the pieces fit together before you dive deeper. 🧩
✈️ ‘Which countries are the most visited?’ 🧳

🧪🔬 Liberty Labs 🧬 🔭

Jupiter spins really fast!
I didn’t know this bit of astronomy trivia, and you may find it interesting too:
It only takes Jupiter 9h and 55 minutes to complete a rotation on its axis compared to the Earth’s 23 hours, 56 minutes, and 4 seconds (not exactly 24 hours —that’s why we have extra days on leap years every 4 years).
But Jupiter is much bigger than Earth, with a radius 11 times wider and a volume 1300 times bigger, so at the equator, its rotational velocity is 12.6 km/s (45,000 km/h; 27,961 mph) compared to only 0.4651 km/s (1674.4 km/h; 1040.4 mph) for Earth.
Google Bard vs BingGPT
I haven’t had a chance to try Google Bard myself as it’s not yet available in Canada, but prof. Ethan Mollick who has been on a real tear experimenting with AI tools for the past few months has shared his first impression:
Lets start with the disappointing model first. That would be Google’s long-awaited Bard. I have had access for 24 hours, but so far it is… not great. It it seems to both hallucinate (make up information) more than other AIs and provide worse initial answers. Take a look at the comparison between Google’s Bard and Microsoft’s Bing AI (based on GPT-4, as we learned last week, more on this in a minute), answering the prompt: Read the PDF of New Modes of Learning Enabled by AI Chatbots: Three Methods and Assignments and perform a draft critique of it. Bard, which Google says is supplemented by searches, gets everything wrong. Bing gives a solid and even thoughtful-feeling critique, and provides sources (though these can be hit or miss, and Bing still hallucinates, just less often)
Again, Bard was just released, so I may not have figured out the secrets of working with it yet. But Bard also fails at generating ideas, at poetry, at helping learn and explain things, at finding interesting connections, etc. I can’t find a use case for this tool yet, it feels incredibly far behind ChatGPT and its competitors. I am not sure why Bard is so mediocre. Google has a lot of talent and many models, so maybe this is just the start.
I can’t confirm this, I haven’t used it myself, but it certainly feels like there are a lot of “fuzzy” characteristics of these models that aren’t as easy to compare as quantitative metrics like the number of parameters.
Prof Mollick also looked at GPT-4, Midjourney V5, and Microsoft’s Copilot announcements.
He concludes:
Even if AI technology did not advance past today, it would be enough for transformation. GPT-4 is more than capable of automating, or assisting with, vast amounts of highly-skilled work without any additional upgrades or improvements. Programmers, analysts, marketing writers, and many other jobs will find huge benefits to working with AI, and huge risks if they do not learn to use these tools. We will need to rethink testing and certification, with AI already able to pass many of our most-challenging tests. Education will need to evolve. A lot is going to change, and these tools are still improving.
Some of the risks of highly-capable AIs is becoming clear. OpenAI released a white paper showing how GPT-4 was capable of some dangerous acts, from giving accurate advice on money laundering to writing threatening messages to people, if it wasn’t stopped by the system’s internal guardrails. GPT-4 was even able to develop, and order online, chemicals that it built to matched the properties of known compounds. And better image generation makes fakes easy - you really can’t trust any photo or video anymore. [...]
Things are not slowing down. If we had hoped for a breather to absorb all of this new technology, it isn’t going to happen
🎨 🎭 Liberty Studio 👩🎨 🎥
‘Six Recent Studies Show an Unexpected Increase in Classical Music Listening’ 🎻🎼📈
Something is going on, and while we don’t quite understand it yet, Classical music seems to be getting more popular in the past 12-18 months, which is great because there’s so much good stuff there and it’s a shame that so few people explore it.
What’s going on here?
Maybe that old orchestral and operatic music now sounds fresh to ears raised on electronic sounds. Maybe the dominance of four-chord compositions has created a hunger for four-movement compositions. Maybe young people view getting dressed up for a night at the opera hall as a kind of cosplay event. Or maybe the pandemic had some impact on music consumption.
And it’s true, the pandemic did cause a major increase in the purchase of musical instruments. People got serious about music—so much so that they wanted to play it themselves. Perhaps it changed listening habits too.
But whatever the reasons, the impact is clear. Starting about 12-18 months ago, something shifted in music consumption patterns. [...]
the success of classical musicians on social media should come as no surprise. With just a quick search, I found many young classical musicians with 100,000 or more followers on Instagram.
"Why look up an answer if you already know the answer? Every question that you ask me, if I have to go look it up or go find a bunch of friends and caucus and then come back and give you the answer, that takes a lot more energy than what’s already in my brain, and just call it 25 watts. I’m sitting here producing answers all day long .."
Man, Jensen is on Fire 🔥🔥 hells yeah 🤘