

524: New Era for Inference Compute, Jensen on Nvidia's Two Waves, Wifi, iPhone vs Microsoft, 4th Agricultural Revolution, Perplexity, and Dune
"this magical tech we take for granted"

Only the mediocre are always at their best.
—Jean Giraudoux
🥫🍟🌮🥕🥦🥖 Nutritional labels present an interesting design challenge. They have to convey information to EVERYONE — from trained nutritionists to people who have no idea what a calorie is.
It’s a hard problem, but I think there’s a no-brainer improvement, at least for the labels in Canada and the U.S., which are the ones I’m familiar with.
It’s very simple:
Nutritional labels should show both absolute numbers AND percentages of the total
Not “% of daily value” because that’s not very useful — does a child and a bodybuilder have the same “daily requirement”? Do 100-pound office worker women and 250-pound construction worker men have the same requirements? A teenager and a 90-year-old?
It’s ridiculous.
But something that has ONLY UPSIDE is doing the math for people.
Portion sizes vary and almost nobody will take the time to figure out what 13 grams of protein out of a portion of 235 grams means.
But if it said “13 grams of protein (5.5% of portion)” that would be super useful. Over time, you could learn which foods have 20-30% protein and which have almost none.
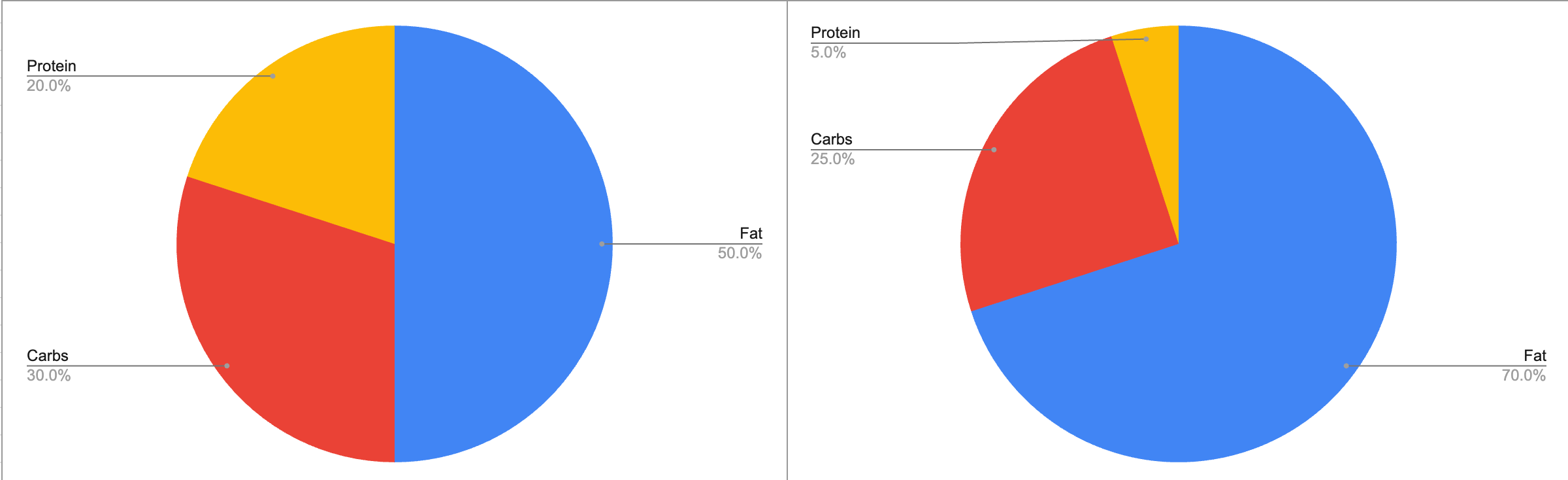
The next level of improvement would be adding a pie chart showing the breakdown of macronutrients 🥧
This would show people how much carbs, fats, and proteins are in this thing they’re considering eating. I’m undecided on whether it’s better to base the pie chart on weight or calories, but whatever we pick, people can start calibrating to it and learn what the colors mean and which slice sizes are high and low.
This information needs to be *glanceable*! 👀
Mental arithmetic shouldn’t be part of it.
🏎️ 📶📲💻🔥 It’s really impressive how much Wi-Fi has improved over the past 25 years. We don’t hear much about it — CPUs, GPUs, RAM, storage and internet bandwidth get more attention — but it’s worth taking a moment to marvel at the innovation in a very difficult problem space (a complex mix of physics + signal processing + information theory + cryptography + backward compatibility + interference management + the messiness of the real-world):
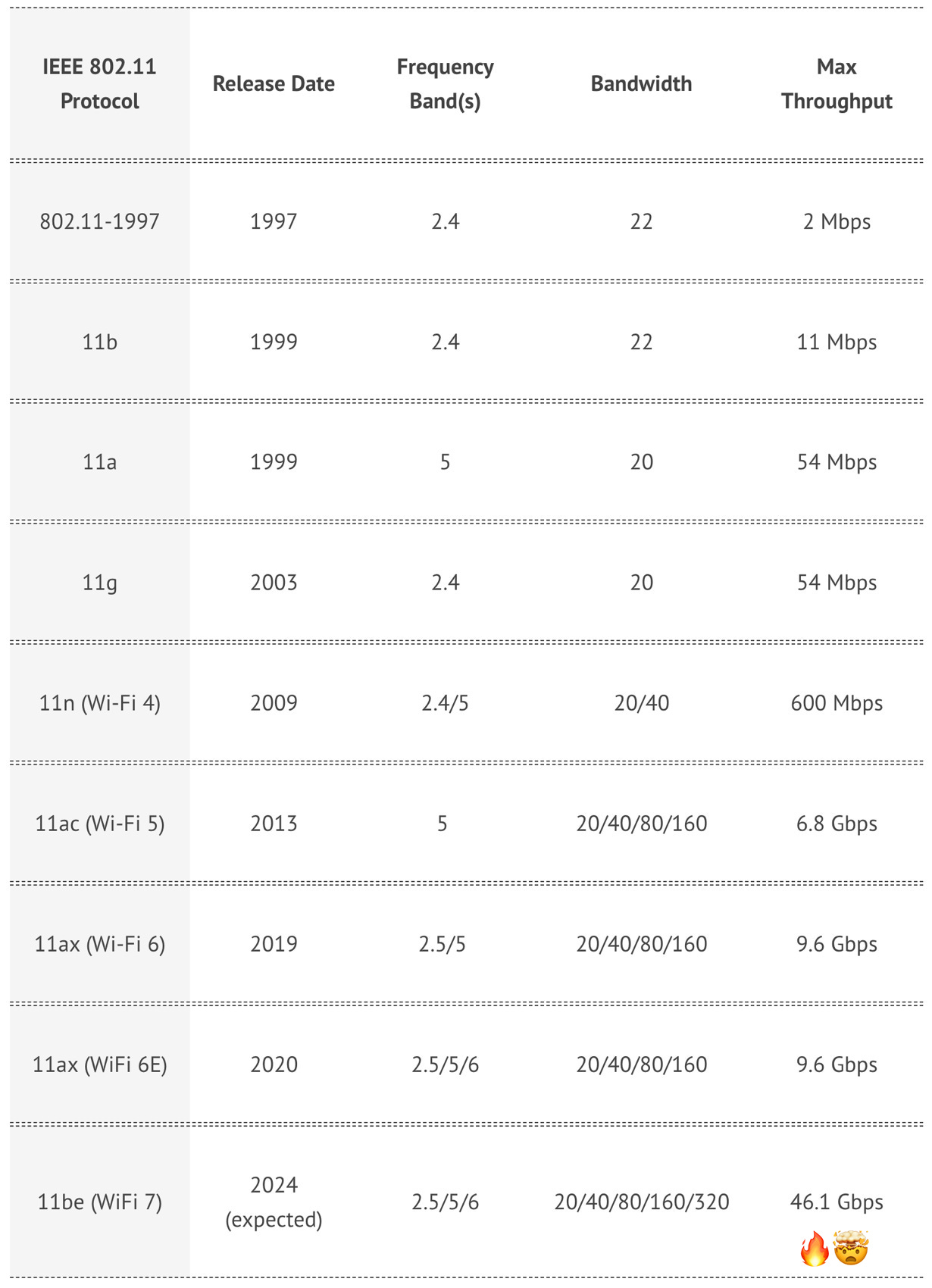
From a *theoretical* 2 megabits/second throughput in 1997 to 46,100 megabits/second in 2024!
Not quite Moore’s Law at its peak, but very impressive and society as a whole benefits tremendously.
It’s a good reminder that from one point on the curve, it can be hard to see very far ahead. It would’ve been easy in 1999 or 2009 to think that “it’s all just radio waves and pulses and a certain point we will tap out because how many bits can you realistically send over a fixed amount of spectrum? We’re already pushing as much as we can, how much further can we go?”
Yet, as with cellular networks (LTE, 5G), we’ve found all kinds of tricks to pack ever more bits and send them to ever more concurrent devices.
And speed isn’t the only thing. Latency has improved, range and stability have gotten better, security has significantly strengthened, efficiency has increased, etc. It all adds up to this magical tech we take for granted.
🏦 💰 Liberty Capital 💳 💴
🍓🤖🤖 Entering a New Era for Inference Compute 🤖🤖 📈
There are multiple factors influencing AI inference compute requirements, and where the balance of these factors will end up is an important unanswered question.
After spending more time with OpenAI’s o1 (aka Strawberry) model and using Perplexity multiple times a day, I can’t help but feel like inference compute needs are going to explode. The most useful new models go through more steps and spend more time “thinking”.
When you asked a question to the original ChatGPT, it spent approximately the same amount of time on every token generated.
But given the direction things are heading, it’ll be common to have models that, when asked one thing, generate multiple sub-queries, perform online searches, analyze the results (text & images), and then spend additional time “thinking” things through and generating step-by-step reasoning, before condensing all that into a relatively short answer.
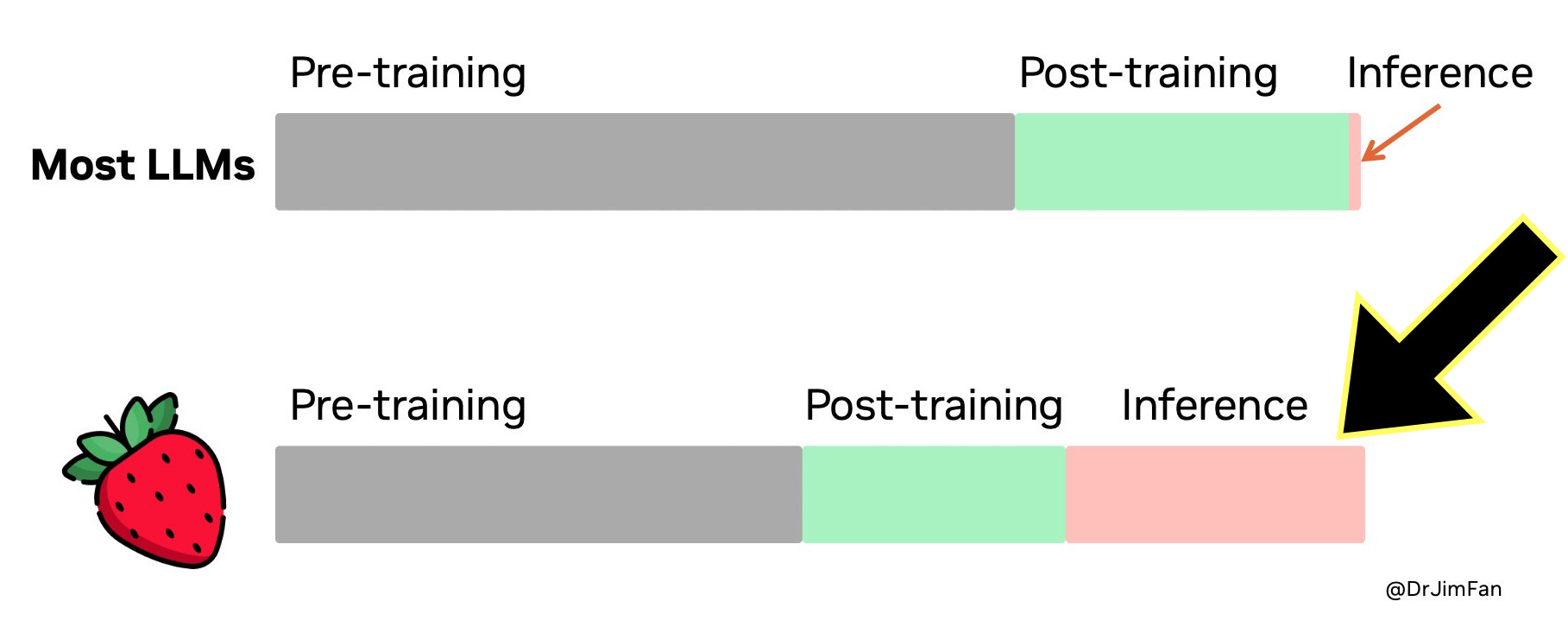
As an aside, this reasoning can also be useful for training, as Jim Fan points out:
You don't need a huge model to perform reasoning. Lots of parameters are dedicated to memorizing facts, in order to perform well in benchmarks like trivia QA. It is possible to factor out reasoning from knowledge, i.e. a small "reasoning core" that knows how to call tools like browser and code verifier. Pre-training compute may be decreased.
A huge amount of compute is shifted to serving inference instead of pre/post-training. LLMs are text-based simulators. By rolling out many possible strategies and scenarios in the simulator, the model will eventually converge to good solutions. [...]
Strawberry easily becomes a data flywheel. If the answer is correct, the entire search trace becomes a mini dataset of training examples, which contain both positive and negative rewards.
Cue the M.C. Escher hands…
In Edition #523, I suggested that o1 — still a terrible name — should have a dial to allow users to ask the model to think longer about certain questions. Of course, compute isn’t free, so API fees should reflect consumption accordingly. But if a problem is very important, I’d have no problem asking the model to work on it for an hour or a day or a week (as long as it’s shown that this increases the quality of the answer and isn’t just the model spinning its wheels).
That’s *a lot* more inference compute, even if much of this processing is hidden from the user and does not result in more visible output tokens.
There’s a phase shift. We’re going from a world where:
More inference compute = faster 🏎️
to
More inference compute = better 🧠💭
On the other hand, there are many algorithmic improvements and techniques that can help keep inference costs down. We’re becoming better at making smaller models that perform well through quantization, pruning, knowledge distillation, and other methods. A big chunk of queries are going to small and mid-sized models — like GPT-4o Mini and Claude 3.5 Sonnet, for example — rather than the biggest and most inference-hungry versions.
But from my vantage point, it seems like these optimizations can only do so much and the next generation of models on the horizon will give another big boost to inference needs because scaling laws require them to be much bigger than the GPT-4 class of models. Combine that with Strawberry/Perplexity-style multi-step reasoning and Retrieval-Augmented Generation (RAG), and inference needs could accelerate again from an already high rate of growth.
🌊🏄♂️🔥😎 The Two Trillion-Dollar Waves Nvidia is Surfing, According to Jensen 🤖🤖🚀
Some highlights from a recent talk by Jensen Huang:
There are two things that are happening at the same time, and it gets conflated and it's helpful to [break them] apart.
So the first thing, let's start with the condition where there's no AI at all. Well, in a world where there's no AI at all, general-purpose computing has run out of steam still. And so we know that Dennard scaling for all the people in the room that enjoy semiconductor physics. Dennard scaling and Meat Conway shrinking of transistor scaling of transistors and Denard scaling of a ISO power increased performance or ISO cost increasing performance.
Those days are over. And so we're not going to see CPUs, general-purpose computers that are going to be twice as fast every year ever again. We'll be lucky if we see it twice as fast every 10 years. The Moore's Law, remember back in the old days, Moore's Law was 10x every 5 years, 100 times every 10 years. So all we have to do is just wait for the CPUs to get faster.
And as the world's data centers continue to process more information, CPUs got twice as fast every single year. And so we didn't see computation inflation. But now that's ended. We're seeing computation inflation. And so the thing that we have to do is we have to accelerate everything we can.
We forget this because AI and transformer models get all the headlines, but there are all kinds of other very large workloads everywhere, and many of them can also be accelerated using GPUs.
If you're doing SQL processing, accelerate that. If you're doing any kind of data processing at all, accelerate that. If you're doing -- if you're creating an Internet company and you're you have a recommender system, absolutely accelerate it, and they're now fully accelerated. This a few years ago was all running on CPU, but now the world's largest data processing engine, which is a system, it's all accelerated now. And so if you have a recommender systems, if you have search systems, any large-scale processing of any large amounts of data, you got to just accelerate that.
And so the first thing that's going to happen is the world's trillion dollars of general-purpose data centers are going to get modernized into accelerated computing. That's going to happen no matter what. That's going to happen no matter what. And the reason for that is as I just come Moore's Law is over. And so -- the first dynamic you're going to see is the densification of computers.
IT is BIG! I just recently wrote about Matt Garman (AWS’ CEO) talking about how only 10-20% of workloads had been moved to the cloud.
How many of those workloads have been transitioned to any kind of acceleration/GPUs? Probably not that many…
These giant data centers are super inefficient because it's filled with air, and air is a lousy conductor. And so what we want to do is take that few, call it, 500, 100, 200-megawatt data center, which is sprawling and you densify it into a really, really small data center.
And so if you look at one of our server racks, NVIDIA server racks look expensive, and it could be a couple of million dollars per rack, but it replaces thousands of nodes.
The amazing thing is just the cables of connecting old general purpose computing systems cost more than replacing all of those and densifying into one rack. The benefit of densifying also is now that you've densified that you can look to cool it because it's hard to liquid cool a data center that's very large, but you can liquid cool a data center that's very small.
And so the first thing that we're doing is accelerating -- modernizing data centers, accelerating it, densifying it, making it more energy efficient. You save money, you save power, you say -- it's much more efficient. That's the first -- if we just focused on that, that's the next 10 years. We'll just accelerate that.
Full salesman mode here. The more you buy, the more you save! 😎
Now of course, there's a second dynamic because of NVIDIA's accelerated computing brought such enormous cost reductions to computing, it's like in the last 10 years instead of Moore's Law being 100x, we scaled computing by 1 millionx in the last 10 years.
And so the question is, what would you do different if your plane traveled a million times faster? What would you do different? And so all of a sudden, people said, "Hey, listen, why don't we just use computers to write software. Instead of us trying to figure out what the features are, instead of us trying to figure out what the algorithms are. We're just -- all the data -- all the predictive data to the computer and let us figure out what the algorithm is, machine learning, generative AI.”
Machines that write software using lots of data.
That’s the revolution right there.
And so we did it in such large scale on so many different data domains that now computers understand not just how to process the data, but the meaning of the data. And because it understands multiple modalities at the same time, it can translate data. And so we can go from English to images, images to English, English to proteins, proteins to chemicals. And so because it understood all of the data at one time, they can now do all this translation, we call generative AI.
Small amount of text into a large amount of text and so on and so forth, we're now in this computer revolution. And now what's amazing is — so the first trillion of data centers is going to get accelerated. And [we] invented this new type of software called generative AI. This generative AI is not just the tool, but it's a skill. And so this is an interesting thing.
This is why a new industry has been created. And the reason for that is if you look at the whole IT industry up until now, we've been making instruments and tools that people use. For the very first time, we're going to create skills that augment people. And so that's why people think that AI is going to expand beyond the $1 trillion of data centers in the IT and into the world of skills.
What he’s saying it reminds me a bit of what people have been saying about ride-sharing (like Uber and Lyft). At first, they were compared to the existing taxi industry, but over time people realized that they had expanded the market and could be bigger than the past industry.
It feels like at first, many thought that this AI stuff was just another IT technology, but over the past couple years, we’ve started to realize that it’s expanding the market greatly into all kinds of other areas.
🕸️ “99% of the value is captured by the consumers” 💸
In Edition #523, I wrote about how brutal capitalism could be, making it very hard to capture the value created by innovation.
Roon wrote this, which I think is a good illustration of the phenomenon:
‘The average price of a Big Mac meal, which includes fries and a drink, is $9.29.’
for two Big Mac meals a month you get access to ridiculously powerful machine intelligence, capable of high tier programming, phd level knowledge
people don’t talk about this absurdity enough
what openai/anthropic/google do is about as good as hanging out the product for free. 99% of the value is captured by the consumers
an understated fact about technological revolutions and capitalism generally
to me, this is an act of incredible benevolence, the positive impact of which won’t be appreciated for a long time. morally speaking, technology is still underratedMost users don’t even pay anything to access LLMs.
They may not get the best frontier models, but this is still a huge amount of value compared to not having these tools.
A world that encourages and fosters innovation benefits us all.
📱 Apple's iPhone revenue is more than *all* of Microsoft's revenue 💰💰💰💰💰💰
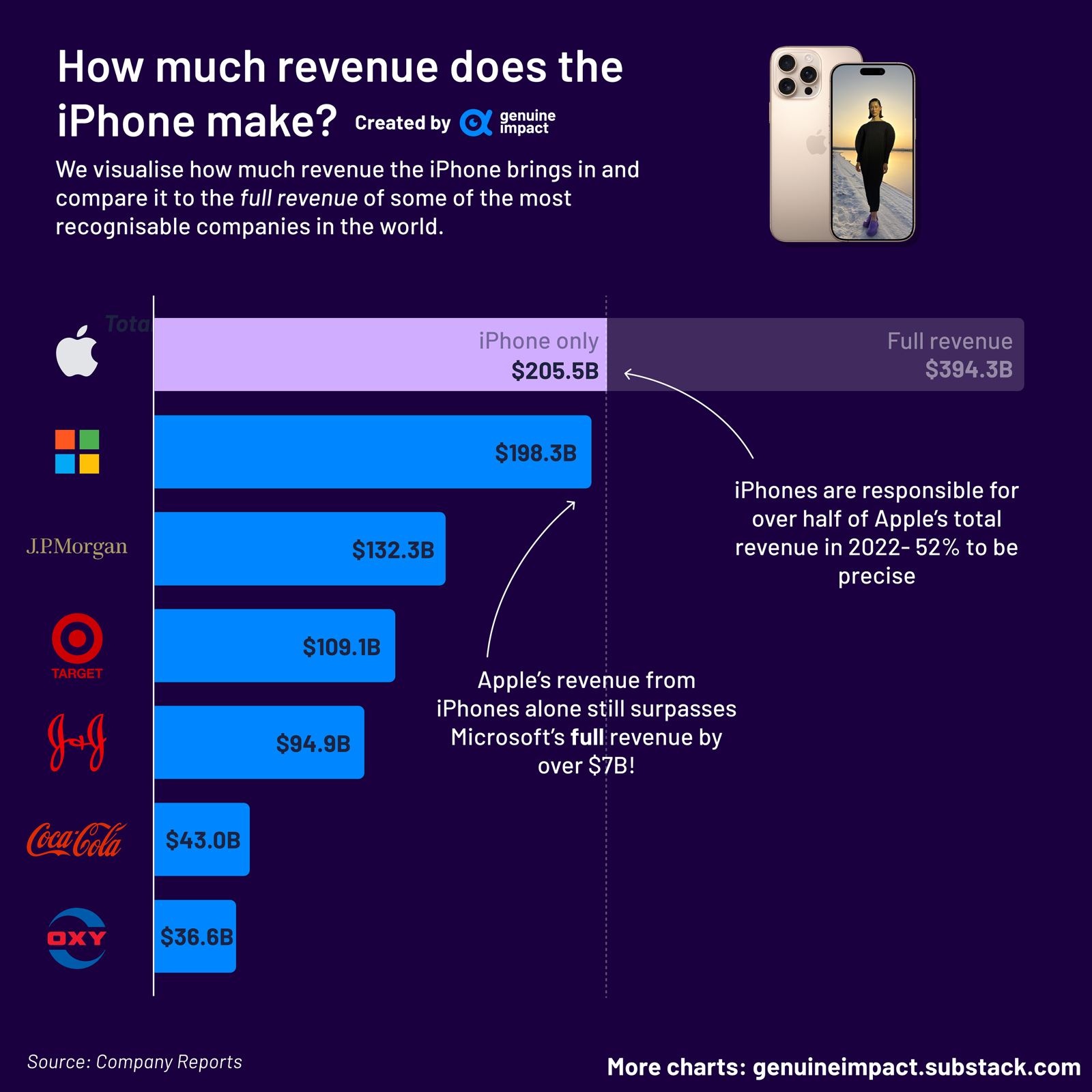
Sometimes I forget the scale of the iPhone as a product. It’s just ridiculous.
And the chart above undersells it, because most of Apple’s service revenue — not counted above — only exists because of the iPhone.
🧪🔬 Liberty Labs 🧬 🔭

🐦 Perplexity has entered its "Fail Whale" era 🐋
If you were around during the early days of Twitter, you saw the ‘Fail Whale’ often enough that it’s burned into your brain.
The service had such good product-market fit that it couldn’t keep up with demand.
I’ve started seeing Perplexity’s equivalent error page more often lately.
It sucks for me and other users, but it’s probably a good sign for them. They have plenty of funding and are largely built on cloud infrastructure, which makes scaling easier, and yet they still can’t keep up with demand.
They’re one of my favorite AI-enabled products. I use them multiple times every day. I hope they keep building their vision independently and aren’t acquired by some Big Tech that absorbs them into the blob and makes their product disappear.
My only recommendation to them if they’re going to be capacity-constrained for a bit is to get a better error page. Theirs is boring. They need some clever joke or animal or something. It’s a branding opportunity.
The 4th Agricultural Revolution (Robotics, AI, Lasers, Data Analytics, etc) 🥕🌾🚜👨🌾🤖
Shooting weeds with lasers will never not be cool!
So cool, and most people have no idea it’s happening!
👸🏼🥚🥚 Termine Queens can live 30-50 Years, Lay 1000 Eggs per Day — Oldest Known Colony is 34,000 Years old
TIL:
The [Termite] queens can be particularly long-lived for insects, with some reportedly living as long as 30 or 50 years.
The queen only lays 10–20 eggs in the very early stages of the colony, but lays as many as 1,000 a day when the colony is several years old.[79] At maturity, a primary queen has a great capacity to lay eggs. In some species, the mature queen has a greatly distended abdomen and may produce 40,000 eggs a day.The oldest known active termite colony is about 34,000 years old! 😳
"Recent radiocarbon dating has revealed that these mounds are far older than any previously known, with some dating as far back as 34,000 years—that's older than the iconic cave paintings in Europe and even older than the Last Glacial Maximum, when vast ice sheets covered much of the northern hemisphere."
The mounds are still inhabited by termites, and the radiocarbon dating of the organic carbon within these mounds has shown ages ranging from 13,000 to 19,000 years, while the carbonate dates back up to 34,000 years. This make the Buffels River mounds the oldest active termite mounds to be dated so far with both organic and inorganic carbon. The previous oldest inhabited mounds from different species from Brazil are 4000 years old.🎨 🎭 Liberty Studio 👩🎨 🎥
🎥🪱 Everything Great About Dune + Dune Music Sketchbooks 🎶
I’ve been listening to Hans Zimmer’s Dune Sketchbooks (part 1 and 2).
He really went all out making music for these films — there’s an anecdote about how after Part 1 came out but before they were green-lit for part 2, Zimmer was still sending music ideas to Villeneuve because he just couldn’t stop. While the official soundtracks are great, I recently discovered those ‘Sketchbooks’ albums which contain longer explorations of the musical ideas used in the film.
It felt both familiar and new, and I quite enjoyed them — I recommend you check them out of you liked the Dune music.
I’ve also enjoyed the series of videos above, pointing out all kinds of cool things in those films (here’s the follow-up video for Dune: Part 2). DON’T WATCH IF YOU HAVEN’T SEEN THEM! (but if so, what are you doing? Watch them ASAP!)
I agree with you about the nutritional labels. However, getting governments and companies to agree on a new standard is not likely. How about just creating a custom prompt for GPT or Perplexity? Point your camera at the package and it generates a custom nutritional chart just like you want. It could even interface with your nutritional/health system to highlight specific nutrients or generate "goodness" ratings based on your personal profile. Sounds like an app to me. And it could be done in a weekend. :)