

525: OpenAI’s o1-Mini, Intel Survival, Daniel Yergin, Mark Zuckerberg, Apple's 1994 Digital Camera, SpaceX, Spy Cameras, and Doom
"It’s almost like he’s going through my bookshelf"

Many problems are minor when you solve them right away, but grow into an enormous conflict when you let them linger.
As a rule of thumb, fix it now.
—James Clear
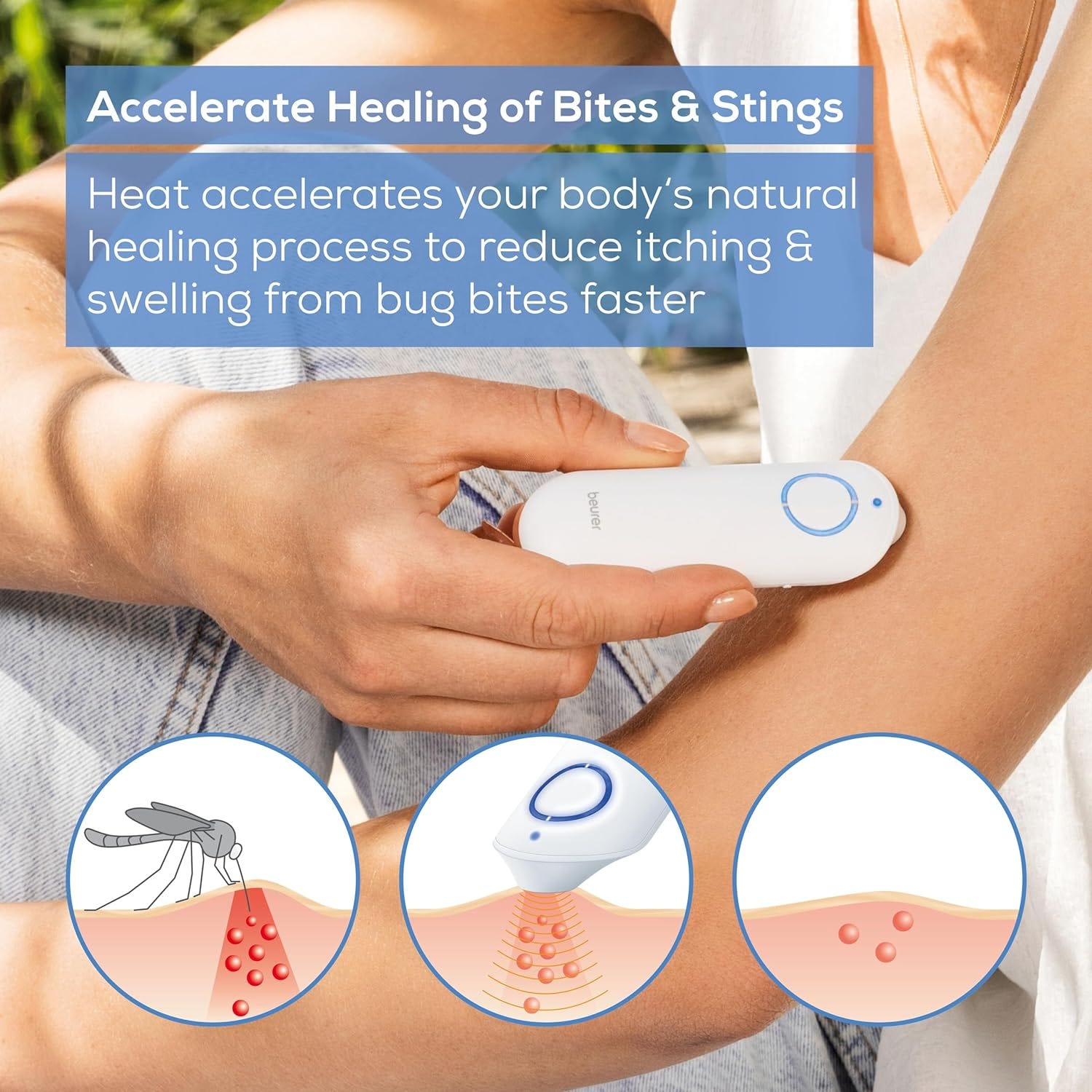
😫🦟 😲 Wait, this exists?!
I just learned about electric insect bite treatment devices…
I HATE mosquitoes.
I mean, I know nobody loves them, but I’m pretty sure I’m an outlier in how much I hate them. They seem to be drawn to me like I’m their equivalent of filet mignon, and I’m probably allergic because once bitten, I get severely inflamed for a week+ and it’s very painful and itchy.
Until Patrick Collison tweeted about them, I had no idea that there were devices that could provide some relief. It would sound too good to be true if I hadn’t seen many skeptical people share their positive experiences.
They work by applying heat for a few seconds to the affected area.
One study: "Mosquito bite-induced itch was reduced by 57% within the first minute and by 81% 5–10 min after treatment, and the overall reduction in itch and pain was more pronounced than in the control group."Here’s a PubMed paper on how they may work, but it doesn’t seem to be well understood.
I’ll buy one and report my experience.
If you’ve tried these things, please let me know if it works for you.
🦟🗺️🧭 Speaking of blood-sucking parasites, what I want is the equivalent of a weather map but for mosquitoes.
I want to select a point on a map and be able to see if there are mosquitoes there — and how many — or get a forecast of whether there will be mosquitoes later in the day.
That would be so useful. I have no idea how that could be accomplished — maybe some kind of automated drone surveys of areas where people are likely to be to build statistical models that can also be fed data about rainfall, wind, humidity, and other factors that can influence the life cycle of bugs 🤔
🏄♂️🧠 Quick update on the balance board: I’m still loving it and the whole family is getting better at it.
The learning curve isn’t too bad. Within a week I went from having to hold on to a chair and having trouble balancing for five seconds to being able to stand on it for about a minute without any support.
I’ve started doing bodyweight squats on it. They’re still shaky, but it’s a start!
🛀💭📖🎧 I wonder how many fewer books would be read worldwide if the Kindle e-ink reader had never been invented?
Same for the combo of audiobooks and wireless headphones like the AirPods.
🏦 💰 Business & Investing 💳 💴

🍓🤖 Small but Smart: OpenAI’s o1-Mini 🤖🍓
Here’s a fascinating follow-up to Edition #524’s riff on the new era for AI compute inference.
OpenAI has released a smaller model based on Strawberry, and interestingly, it performs as well or better than its larger sibling. How can that be? Smaller models tend to be dumber than big ones..?
It turns out that o1-mini is even better than o1-preview in math, according to developers who have been evaluating and sharing examples. And it is generally on par in most other ways, including "hard prompts," or particularly complex requests, according to the latest Lmsys leaderboard, which ranks o1-mini in third place behind o1-preview and the company’s prior flagship model, GPT-4o.
OpenAI itself has said o1-mini may perform better than its big brother in coding tasks too
One reason for o1-mini’s relatively mighty performance is that OpenAI allows customers to use more tokens—words or fragments of words—when asking it questions, compared to o1-preview. That’s because o1-mini’s smaller size means it processes information more efficiently and more cheaply, according to the implications of a post by one of its employees.
In fact, we’re told o1-mini processes tokens three times faster than o1-preview.
Because of that, OpenAI is letting o1-mini think longer than o1-preview, and that move is helping to prove what the company says is the best part of its reasoning models: more thinking time equals better answers, otherwise known as log-linear compute scaling.
It’s a nice real-world demonstration that with chain-of-thought/complex reasoning models, throwing more inference at them really does lead to better results.
In other words, the larger o1 model should do even better than the smaller one if given equal time, but that’s so much more expensive. It turns out that you can achieve similar “intelligence” just by letting the smaller model run through more tokens (which are faster and cheaper).
This is very bullish for inference demand going forward!
