

546: I Have Lots of Thoughts on DeepSeek R1 + Nvidia + OpenAI + Meta + Google + AWS + Microsoft, Mastercard vs Amazon & Apple, and John von Neumann & Bob Dylan
"Who can edit Bob Dylan anyway?"

You insist that there is something a machine cannot do.
If you tell me precisely what it is a machine cannot do, then I can always make a machine which will do just that.
—John von Neumann

🛫⛱️👦🏻🧒🏼👩🏻🏝️🛳️🛬📖📚 I spent the past week offline – I know, how quaint!
I took a family vacation at sea on a cruise ship and decided it would be a good opportunity to go cold turkey and detox from memes and news cycles for a few days.
Life is trade-offs.
The thinking behind picking a cruise was simple: our kids aren’t quite ready for the type of vacation that involves all-day walking tours, stopping along the way at local eateries to try exotic food and bathe in the local culture.
Maybe in a few years we’ll do a ‘cultural foreign expedition type’ trip, but for this one, we just wanted:
A warm place with no snow 🚫❄️
A self-contained environment where the kids could explore, relax, play 🏖️
No need to worry about cooking, cleaning, driving around, logistics, etc. Just relaxing and spending time together.
Personally, all I wanted was to have plenty of time to sit in the shade and read while the kids were having fun 📕
So the cruise won out for the kids’ first trip outside of Canada (they grew up during the pandemic, so not much travel then).
We ended up going on the largest cruise ship in operation right now, the ‘Icon of the Seas’ (Royal Caribbean). It was built in Finland and had its maiden voyage in early 2024.
We picked this ship because it’s particularly kid-friendly:
It has lots of crazy spirallin’ water slides, multiple pools, carousels, rock climbing, basketball courts, escape rooms, arcades, a surfing simulator (never-ending artificial waves! 🌊🏄♀️), mini-golf, etc.
That thing is *gigantic*. When I first saw it, I thought: “that’s a recreational aircraft carrier!”

I had to look it up, of course:
A Nimitz‑class carrier is about 1,100 feet/333 meters long
The Icon is 1,200 feet/365 meters long
But the carrier is much wider because of the flight deck, 250 feet across to 150 feet for the Icon
“A modern cruise ship like Icon of the Seas may displace on the order of 100,000–110,000 tons when fully loaded—a figure that is comparable (in weight) to a Nimitz‑class carrier’s ~100,000 tons full load.”
The Icon has a capacity of 5,500 to 7,500 passengers (depending on how many per room) and 2,200 crew (total: 7,700-9,700).
A Nimitz‑class carrier has approx 5,000-5,200 personnel (a lot more of the space is taken up by planes, weapons, fuel, equipment, etc).
The geographical arbitrage at the root of the cruise industry is interesting. Each employee's name tag includes their country of origin. I saw people from the Philippines, Indonesia, China, India, Romania, Zimbabwe, South Africa, etc.
It’s not an easy job. I was talking to someone who said he’s been working on ships for more than 20 years and was just about to finish a contract and go back home to Indonesia and see his family for the first time in 7 months.
I couldn’t help but think about how it must feel like Groundhog Day for them. For us, it’s our first day on the ship, everything is new. For them, it may be the 30th week when they have to run the same script and relive the same milestones and visit the same islands with a new group.
I found myself fascinated by the ship's 'behind-the-scenes' operations, the hidden areas: massive kitchens where they prepare tens of thousands of meals per day, the employee quarters, the giant laundry, the engine room, the weekly logistics of resupplying food & fuel for such a massive vessel, etc.
There are YouTube channels by cruise employees that allow you to peek behind the curtain, if you’re also curious. It’s an interesting world, a unique bubble culture that blends all kinds of international mores, kind of like the merchant marine.

🙌📕🛒📬 It’s here!
Get your copy of Two Thoughts, the new book by Jim O’Shaughnessy and Vatsal Kaushik, while it’s hot off the presses! I have my copy on my desk, I’m looking at it right now.
The hardcover is an especially beautiful artifact, but the paperback and Kindle are also great.
The audiobook (🎧 ) is special: It not only includes the book’s content, but also exclusive discussions between Jim and Vatsal and Morgan Housel, Rory Sutherland, and Anna Gát!
💚 🥃 🙏☺️ If you’re a free sub, I hope you’ll decide to become a paid supporter in 2025:
🏦 💰 Business & Investing 💳 💴

🤔💭🤖 Let’s Think it Through: DeepSeek Implications for AI Industry, Nvidia, Reasoning Models, OpenAI, and Beyond 📈📉📈🏗️🐜
I picked quite a week to be offline!
When I came back, everything I saw was about DeepSeek.
It seems like the whole world synched up on this one thing for a few days — kind of like a neural synchronization during an epileptic seizure when large groups of neurons begin firing together, creating an abnormal hypersynchronous state.
Nvidia’s stock fell approximately 18% intraday on Monday and the whole tech sector had a mini-panic attack as everyone wondered if this Chinese hedge-fund’s AI lab had obsoleted hundreds of billions of capital expenditure through algorithmic dark magic.
I don’t want to rehash the whole story play-by-play because you’ve lived through it — it was unavoidable last week! — but I want to highlight a few good sources of information to better understand what happened:
🏆 Credit where Credit is Due
First, I have to tip my hat (🎩) to the DeepSeek/High-Flyer team of engineers and to Liang Wenfeng, the founder of both. What they’ve done with a relatively small team and multiple technical constraints (the mother of invention!) is very impressive — almost catching up to the bleeding edge and releasing the results as open weights + papers describing their technical breakthroughs is impressive on many levels.
Clearly, they didn’t do it on a $6m shoestring budget as a side-hobby, as some of the early memes last week claimed. They have invested hundreds of millions into infrastructure (a lot of it being dual-use between the hedge fund and DeepSeek, afaik) and pay very well for top talent. The paper never claimed that the whole model had been developed for $6m anyway, which was widely misunderstood, probably because it was just a much better — and more viral — narrative.
While total costs were much higher than the headlines, that’s not what interests me most. Let’s think about the implications of their innovations for the rest of the industry.
Was Mr. Market right to dump Nvidia last week? If OpenAI was publicly traded, would the stock have crashed, and would it have been justified? 📉
🤖🩻🔍 Quick Look at DeepSeek’s innovations/optimizations 🧪
They found a technique (Multi-Head Latent Attention, or MLA) to reduce memory usage during inference, which is particularly useful for reasoning models like R1 and o1/o3, since they generate a ton of tokens while coming up with an answer, and, by their nature, autoregressive models need to keep all that context in RAM to generate the next token — the more tokens in context, the more memory is used.
They also architected their model as a sparse Mixture-of-Experts with more numerous and smaller sub-models than typical implementations (ie. GPT-4, Mistral 8x7b)). While the total parameter count is 637bn, only 37bn chunks light up during inference, with a sophisticated gating mechanism that efficiently routes inputs to the top 2–4 “experts” per query.
This is contrasted with Meta’s Llama (🦙) models, which are “dense”, meaning that the whole thing “lights up” when queried (this has pros and cons — but I wonder if this isn’t going to be a problem for reasoning models 🤔).
They also leaned more heavily into an AlphaZero-like model of reinforcement learning (RL) that helped the base model learn reasoning through trial-and-error, with emergent skills like chain-of-thought and self-correction.
These approaches reduce both training and inference costs.
Here’s one thing to keep in mind, though: Most of the frontier models are not open, so we don’t know all the tricks and innovations that they’re using to improve training and inference efficiency.
There’s always a risk in comparing what you can see with what you can’t see.
We know that OpenAI, Anthropic, Google, and others have been optimizing their models relentlessly and driving costs down by orders of magnitude over the past two years.
In fact, Google has a Gemini 2.0 Flash reasoning model with similar performance to DeepSeek R1 and an extremely low cost that mostly flew under the radar (because Google somehow can’t seem to get invited to the cool kids’ table when it comes to LLMs — they have strong models but rarely are part of the conversation ¯\_(ツ)_/¯ ).
Some of these “closed” optimizations may be just as impressive as some of DeepSeek’s breakthroughs, but we don’t hear about them because they aren’t published.
Another thing to keep in mind when comparing DeepSeek to others using API costs is that this isn’t apples to apples (🍎vs🍏). It’s reported that OpenAI is making very nice software-like gross margins on its inference, while DeepSeek is suspected to be selling at cost, likely to get as much attention and do as much land grab of users as possible (Strike the iron while it’s hot! 🔥).
What made DeepSeek R1 so special is that it came from China and is open. If Google had released that model it may have made few waves — in fact, it’s kind of what happened with Gemini Flash 2.0 Thinking 😬
🤖👀🇨🇳 Will Success Make DeepSeek Worse?
There’s an argument to be made that what made DeepSeek so successful was that they were under the radar doing their own thing.
This success has put them very much on the radar. Now, the eye of Sauron is on them. 👁️
Will interference by the Chinese government (even if well-intentioned from their POV) cause them to lose what made them so effective and special?
I could imagine all kinds of political requests from up high for them to “help support the national interest and strengthen China’s AI industry by doing XYZ” causing them to lose focus, become more bureaucratic, more careful, and slower.
Maybe the CCP will ask them to use Huawei chips instead of Nvidia. Maybe they’ll ask for more censorship of the model. Maybe political appointees will now sit on board meetings and review every plan and management decision. Maybe they’ll be showered with subsidies and resources — which seems great at first — but it could dilute their high-performance team through rapid expansion and make them revert to the mean, so to speak.
Maybe Liang Wenfeng will step on some toes and become the next Jack Ma 🤔
¯\_(ツ)_/¯
🏎️ Diffusion of this Innovation Should be Fast 📝👀📄📄📄📄
Because DeepSeek’s model is open and released under a very permissive license (MIT) and because papers were published describing their techniques, I expect that others will rapidly catch up and that any advantage that DeepSeek may have right now will erode faster than it would have if they had kept their techniques secret.
In the same way that Meta is helping raise the floor by making excellent models available for free, DeekSeek is making reasoning models more accessible to users, putting pressure on OpenAI to cut its margins on o1 and ship next-gen models faster (o3, Deep research) to maintain a lead, and teaching the whole industry how to become more efficient in training and inference.
🤏 Less is More, but More is Even More 🚀
What happens if these techniques are widely adopted?
Does all this efficiency mean that AI labs don’t need their huge training clusters and inference infrastructure anymore? Was this all a waste?
I saw this narrative float around last week, and while I can’t know the future (🔮), if I had to bet on it, I’d say that any efficiency improvements will be reinvested in MOAR of everything. MOAR training, MOAR parameters, MOAR synthetic data to train, MOAR tokens generated per reasoning session, MOAR room in context windows, whatever.
While it’s true that it’s great to do more with less, just imagine how much more you can do with more.
Do you think that if you offered DeepSeek a 100k GB200 GPU training cluster, that they would say “No thanks, we’re good, we’ve figured out how to do everything with fewer chips”?
OF COURSE they’d take it in a heartbeat, and their models would be better than what they can make with their constrained infrastructure.
My guess is that the rate limiter will remain access to GPUs and energy, not “we don’t know what to do with all this compute now that algorithmic improvements have increased efficiency”.
Let’s say you could snap your fingers and instantly implement all of DeepSeek’s algorithmic innovations into OpenAI’s stack in a way that works and makes sense with their own optimizations and systems. Would they cancel GPU orders and keep doing everything else the same?
I don’t think so.
I suspect they'd:
Run more experiments
Train more models in parallel
Generate more synthetic training data
Train even bigger models, incorporate more video in the training set
Allow their reasoning models to "think" even longer on average
Potentially reduce API prices to restrict competition
Start training projects currently on hold because they don't want to divert resources from core products
In any case, I don’t think that Jensen would see fewer orders from them.
In fact, by making reasoning models more accessible, whatever may be lost on the training side probably doesn’t matter too much because the inference side is likely to see a bend in the curve. When you go from models that generate X tokens on average per query to models that generate multiples of X per query and require large context windows is bound to put some strain on infra regardless of optimizations.
In other words, if you reduce the cost per token, but the end result is that everyone starts generating way more tokens, you probably don’t have an absolute reduction in use.
🔄 Reinvesting Efficiency Improvements
One of the memes last week: Everyone learned about English economist William Stanley Jevons and his Jevons Paradox.
I first heard about it back in 2005 when I was researching hybrid cars (the Toyota Prius was leading that wave) and fuel efficiency improvements in internal combustion engines over time.
Gasoline engines have become tremendously more efficient over time BUT most of those gains have been reinvested into power, safety, comfort, and longer distances driven (ie. if it costs you less per mile, you are likely to drive more miles).
This means that while *all else equal* engines kept improving, the absolute fuel consumption didn’t follow that curve.
Another example for you:
Nvidia’s software engineers constantly optimize their stack to make it perform better.
Occasionally, some framework or domain-specific library gets updated and suddenly a certain type of compute (ie. protein folding or whatever) becomes twice as fast or ten times as fast. There’s a specific instance where Nvidia's optimization of MMseqs2-GPU led to a 22x speedup compared to the original AlphaFold2 implementation. Another: TensorRT-LLM doubled inference performance for Llama 2 70B by leveraging FP8 precision and kernel optimizations 🤯
Do all of these optimizations lead to Nvidia customers buying fewer GPUs and having spare compute? Or do they just find ways to eat up all the new headroom to do even more things — more iterations, more experiments, more projects, etc.
That’s right. While DeepSeek is helping the whole industry optimize parts of its stack, the spirit of what is happening is not too dissimilar. I suspect the result will be the same.
🔮 Prediction about Nvidia Orders Post DeepSeek R1 🤖💰
You want me to be concrete about it?
Ok.
I predict that DeepSeek’s innovations won’t result in fewer GPU sales, and probably will result in more demand for compute because it’s accelerating the deployment of reasoning models to users — OpenAI’s more advanced reasoning models were only for paid users, but now they will be deployed to free users to counter DeepSeek. I suspect that the timeline for ‘Deep research’ was also accelerated to recapture the halo of being the leading AI lab.
🫳💰 AI Value Capture 🏗️🤖💸
Clearly AI is creating a lot of value, but how much will be consumer surplus and how much will be captured — and who will capture it?
There’s so much money and talent pouring into the sector, with many different AI Labs being neck-and-neck at the frontier, that in recent times we’ve seen a commoditization effect on models.
That’s how capitalism works.
Once in a while there’s a jump forward, but fairly rapidly (typically within months) others catch up, or at least get close enough that users who don’t NEED the very bleeding edge probably won’t notice too much difference if someone swapped models in whatever app they use, or if you gave them a blind test in the LLM Arena between two leading models.
I’m sure OpenAI hoped that reasoning models (o1 and o3) would give it an umbrella to take some pricing for a while, but DeepSeek is putting pressure on that and somewhat commoditizing this too…
If the industry remains in this equilibrium, it seems to me like most of the value capture will remain with Nvidia and hyperscalers, aka the providers of compute.
Another group of players that will likely capture a bunch of value are those with strong established distribution channels in the enterprise and with consumers. So that’s probably Microsoft, Google, Meta, etc.
Maybe some players actually have data advantages (Tesla with real-world driving data, some industrial/financial/biotech players with proprietary data), but it remains to be seen how valuable that will be and if once models are created, others can distill them and rapidly catch up.
🔮 One Last Prediction: A ‘Kirkland’ version of OpenAI’s ‘Deep Research’ is Coming
Before I go, here’s one I’m expecting soon: Someone will take DeepSeek’s R1 and create an equivalent of OpenAI’s Deep research tool.
You’ll have the model go off, do a bunch of web research, spend 10-20-30 minutes generating tokens, summarizing them, double-checking stuff, formatting it in a readable format, etc, and then come back with a research report.
I don’t know if it’ll be DeepSeek or someone else that does it first.
Maybe Perplexity? 🤔
But someone will do it and it’ll put pressure on OpenAI’s margins there too 😅
💳 Since its IPO Mastercard has Matched Apple & Amazon 📈🍎🛒🚚📦📦📦
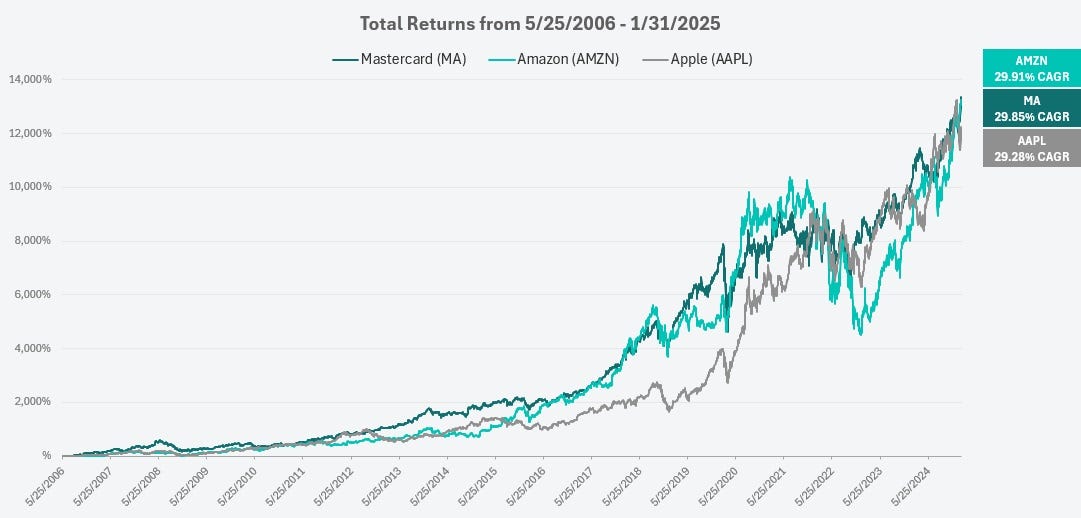
Friend-of-the-show Douglas Ott has a nice writeup about Mastercard.
This graph stood out to me — almost 30% compound annual growth since 2006! Keeping up with Amazon and Apple — two of the best-performing stocks over the past two decades — is no easy feat.
Very impressive. Much of the same applies to Visa, though it IPO’ed later and hasn’t done quite as well — close but no cigar.
It never felt like an underappreciated business to me. In fact, a few years ago Visa and Mastercard were constantly discussed on Fintwit. But I haven’t heard much about them in a while.
Maybe it somehow got too boring in this Mag7 world and Doug is correct when he says:
In the end, it seems Mastercard is an underappreciated business and brand. It saves everyone time and money, but most can’t help but complain about it. It benefits from network effects, but its not Facebook or Instagram. Everyone knows the brand, but no one knows the name of its CEOs. It’s tech, but it’s not in Silicon Valley🧪🔬 Science & Technology 🧬 🔭
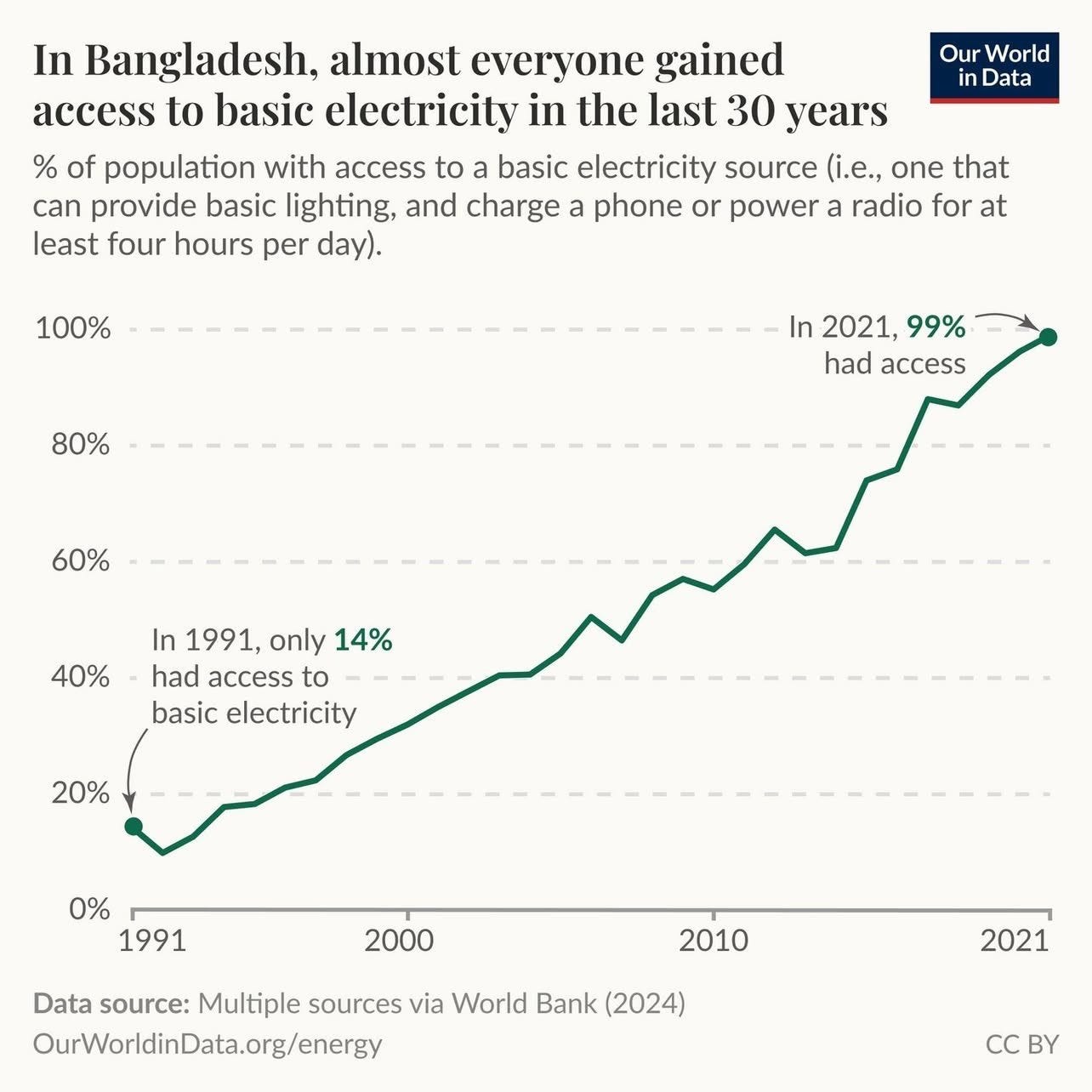
🌏 The Future is Here, It’s Just Not Evenly Distributed 🔌
My friend MBI (🇧🇩🇺🇸) writes:
As I was born in 1991 in Bangladesh, I had the opportunity to experience this first hand. The hot, humid summer months were unforgivable during load shedding.
While growing up, it was typical to experience 3-4 hours of load shedding per day. But even that seemed like a blessing every time I visited my paternal grandparents village which had to wait till early 2010s to even get access to electricity.
In contrast, by 1945, 90% Americans had access to electricity. Sometimes, the “future” takes awfully long to arrive for hundreds of millions (or even billions) of people. We may be in 2025, but rest assured not everyone on the planet is living in the same year!
Those of us fortunate enough to have these magical things tend to take them for granted, but infrastructure should be cherished, celebrated… and constantly improved and made more resilient!
🧫🔬🤖👩🔬 OpenAI’s Protein Design Model — GPT-4b Micro
This one flew under the radar:
OpenAI says it’s getting into the science game too—with a model for engineering proteins.
The work represents OpenAI’s first model focused on biological data and its first public claim that its models can deliver unexpected scientific results. As such, it is a step toward determining whether or not AI can make true discoveries, which some argue is a major test on the pathway to “artificial general intelligence.”
The protein engineering project started a year ago when Retro Biosciences, a longevity research company based in San Francisco, approached OpenAI about working together.
Sam Altman has a $180m investment in Retro Biosciences, so there’s that… 🤔
How do they plan to do that?
GPT-4b micro, the AI model from OpenAI, represents a significant leap in protein engineering for cellular reprogramming. Trained on protein sequences and interaction data, this model can suggest modifications to Yamanaka factors (Oct4, Sox2, Klf4, and c-Myc), proposing bold alterations of up to one-third of a protein's amino acids. The model's capabilities extend beyond mere analysis, as it can dream up entirely new proteins capable of turning regular cells into stem cells.
Preliminary tests have shown promising results, with the modified proteins demonstrating a 50-fold increase in effectiveness for creating stem cells compared to conventional methods [...]
This AI-driven approach could accelerate the development of:
Organ development for transplantation
Cell replacement therapies for degenerative diseases
Targeted treatments for age-related conditions
I sure hope they succeed, because biology appears to be one of the points of highest leverage for AI use in scientific research.
🎨 🎭 The Arts & History 👩🎨 🎥
📘🧑🏻🦱🎸 Two GREAT Books I read on Vacation 📙🤖🇭🇺
I read three books while on vacation. I want to tell you about two of them.
First, there’s MANIAC by Benjamín Labatut.
I wasn’t familiar with that author, but now I want to check out his other works, because this book may be a new favorite of mine. I’ll need to re-read it someday to be sure.
MANIAC is historical fiction centered around John von Neumann and his ideas.
Rather than tackling von Neumann directly — that’s a tall order! — Labatut creates a mosaic of the people who surrounded him throughout his life: Colleagues, rivals, family, and others, to paint an indirect portrait of the man as seen by those closest to him.
The 1930s to 1950s period in the world of physics and mathematics has always fascinated me, so I was already very familiar with many of the cast of characters: Niels Bohr, Richard P. Feynman, Edward Teller, Paul Dirac, Albert Einstein, Alan Turing, Robert Oppenheimer, Kurt Gödel, etc. The only missing piece that could've made it even better would have been Claude Shannon!
The book includes enough familiar stories and anecdotes to make me smile, but enough new to truly delight me.
The writing is excellent, with each chapter adopting a different style to match the voice and perspective of its narrator. Labatut has done his homework. In the Feynman chapter, the style and cadence match the real one and I could hear his voice in my head.
The book itself is a kind of meditation on artificial intelligence and the post-computer world, and where those ideas came from, first as thought experiments. The book shows us the seeds being planted, and ends with a very memorable section about Lee Sedol vs Deepmind’s AlphaGo (there’s a great documentary about it available for free on Youtube, I recommend it), one of the seminal moments in AI (pre-ChatGPT).
The second book is Bob Dylan’s Memoirs (Chronicles Volume 1)
This one is just wonderful! I highlighted so many things, I think I’ll start posting some quotes on Twitter soon.
I love that he wrote it all himself, without an editor.
Who can edit Bob Dylan anyway?
My friend David Senra (🎙️📚) did an episode about this book, it’s probably the place to start to get an idea about whether it’s for you.
The AI section... brilliant! 💡
Those who like Senra's talk on Dylan's Chronicles might like my post on Dylan's idiosyncratic reading, "Bob D. on Thucydides." https://substack.com/home/post/p-91303767