

549: Morris Chang, TSMC & Broadcom to Swallow Intel?, xAI Grok 3, OpenAI o3 Brute Force or Breakthrough, Microsoft + Anduril, Google's Jeff Dean, and Shōgun
“I'm not even supposed to be here today!"

Things that have never happened before happen all the time.
—Scott Douglas Sagan

✈️🚫❄️ If you’ve seen the film ‘Clerks’ by Kevin Smith, you know that one of the recurring lines is Dante saying:
“I'm not even supposed to be here today!"
That's exactly how I feel right now.
At the time this gets published, I’m *supposed* to be on a plane returning from a fun trip in the USA. But alas…
❄❄❄❄ Snow deleted my plans ❄❄❄❄
Because of a winter storm, I spent all weekend rebooking flights only to have them canceled a few hours later. I ended up pushing my trip to early Monday, after the storm — I was going to wake up at 3:30 AM to go to the airport! — but that flight got canceled too.
The experience got me thinking about the sheer complexity of airline logistics and what is required to coordinate this massive just-in-time system.
Even after a storm passes, you see a bullwhip effect rippling through the system for a while. Cancel hundreds of flights, and your pilots and crews are out of position. Thousands of travelers try to rebook at the same time, and every other flight gets full. Like dominoes, more flights get canceled because they don't have crews, and things cascade further out…
I don’t envy the people tasked with clearing up that mess and rebooting the whole system to a more normal flow pattern.
In any case, I was super bummed out to be stuck here and missing out on spending a few days with Jim (💚 🥃 🎩) and my OSV friends. When we get together, there are always wonderful conversations and creative brainstorming — my favorite things!
There will be other opportunities for us to see each other in the coming months, but it always sucks when the rug gets pulled from under you at the last minute — again and again, I rebooked my flight 4 times — after weeks of looking forward to it.

The glass-half-full way to look at it is that at least I wasn’t on this 👆 plane 😬
👩🏻🍼👶👦🏻👧🏻👨💁♀️👴🏻🧓🏻 Today's light reading: Just pondering the human condition, keeping it light and fluffy… ¯\_(ツ)_/¯
Mortality and Temporality: The awareness of death and the finite nature of human life is a central part of the experience of life.
Meaning and Purpose: We grapple with questions about the meaning of life. What is our purpose? What is our place in the universe?
Suffering and Joy: We feel a wide range of emotions. From joy and love to pain, loss, and suffering.
Relationships and Isolation: We form relationships, but also experience loneliness and isolation. We’re both individuals and social beings.
Freedom and Responsibility: Free will — or at least the subjective perception of it — and the responsibility that comes with making choices.
Limitations and Potential: We are both limited by our physical and mental capabilities and yet capable of great achievements and creativity. We are finite beings with infinite aspirations.
The Search for Knowledge and Understanding: We have a drive to learn, explore, and understand the world around us. We seek certainty in a fundamentally uncertain world.
💚 🥃 🙏☺️ If you’re a free sub, I hope you’ll decide to become a paid supporter in 2025:
🏦 💰 Business & Investing 💳 💴
🗣️🐜🇹🇼 Interview: TSMC Founder Morris Chang 📺🎧
Morris Chang is a pivotal figure in the semiconductor industry and deserves far more recognition in the West — maybe there’s an alternative timeline where Texas Instruments named him CEO and he stayed in the US, but TSMC may not exist in that alternate dimension… — and I’m glad that Ben and David (💚 🥃) from Acquired did this extended interview with him.
It’s great stuff. Here’s an anecdote about when TSMC’s CEO-at-the-time (not Morris) fired some employees and protestors showed up at Morris’ house:
They appeared again, some of the protestors. About 25 of them decided to spend the night, sleepover in the little park that’s about a block away from my home. My wife literally didn’t sleep that night. She would wake up and went over to that window to take a look to see what was going on.
Then very early the next morning, six o’clock the next morning, my wife got up. She took one of the bodyguards and went to a neighborhood market, got the Chinese style breakfast or Chinese fried bread… buns, soybean milk, and take enough of the breakfast, enough for 25–30 people, back to the park. and distribute them to the protestors.
They were thankful, and they actually decided to not go to the president’s palace, president’s mansion. They told my wife that they would not do that that day. All this precipitated my taking back the CEO job.
Cialdini would be proud!
🐜🍖🇹🇼🇺🇸 Broadcom and TSMC Could Split Intel’s Carcass
Speaking of TSMC…
While Intel isn’t dead, the vultures sure are circling.
Intel’s rivals Taiwan Semiconductor Manufacturing Co. and Broadcom are each eyeing potential deals that would break the American chip-making icon in two.
Broadcom has been closely examining Intel’s chip-design and marketing business, according to people familiar with the matter. It has informally discussed with its advisers making a bid but would likely only do so if it finds a partner for Intel’s manufacturing business, the people said.
Nothing has been submitted to Intel, the people cautioned, and Broadcom could decide not to seek a deal.
Separately, TSMC has studied controlling some or all of Intel’s chip plants, potentially as part of an investor consortium or other structure, according to people familiar with the discussions.
It’s worth noting that Broadcom and TSMC aren’t working together (yet?), but there’s clear complementarity in their interests.
However, TSMC can’t take over Intel’s manufacturing arm outright:
Any deal involving TSMC and other investors taking control of Intel’s factories would require signoff from the U.S. government. The Chips Act of 2022 established a $53 billion grant program for domestic chip-making, and Intel was the largest recipient of funding under it, getting up to $7.9 billion to support new factories in Ohio, Arizona and other locations in the U.S. As part of that deal, Intel was required to maintain a majority share of its factories if they were spun off into a new entity, the company said in a regulatory filing.
It’s reported that this joint venture idea was suggested to TSMC by the White House.
This raises questions about the implications for Taiwan if such a deal went through. I would expect that it would include technology transfer to Intel 🤔
If Intel’s manufacturing base could be revitalized by TSMC management and IP and turned into a competitive leading-edge foundry that makes large quantities of chips for third parties — not just Intel — would it weaken Taiwan’s “silicon shield” enough that it would make invasion by China more likely?
One could envision a path that would try to maintain some of the shield by creating what I'll call Schrödinger's Deterrent — simultaneously weakening and strengthening commitments through different mechanisms. Taiwan's strategy appears to be:
Maintain cutting-edge R&D in Taiwan ("Crown Jewels")
Use US manufacturing as political insurance
Become further embedded in US defense industrial base via Intel partnership
Maybe this approach could moderately increase US defensive likelihood by making Taiwan:
Keep technical expertise concentration in Taiwan
Stay deeply integrated in supply chains
Feel more "American" in political perception (through a large manufacturing base in the US, employing thousands of Americans, etc)
But I don’t know, it’s a bit of a stretch… 🤔
🏎️🤖 xAI Releases Grok 3 — Can Elon Musk Win the Race? 🐇
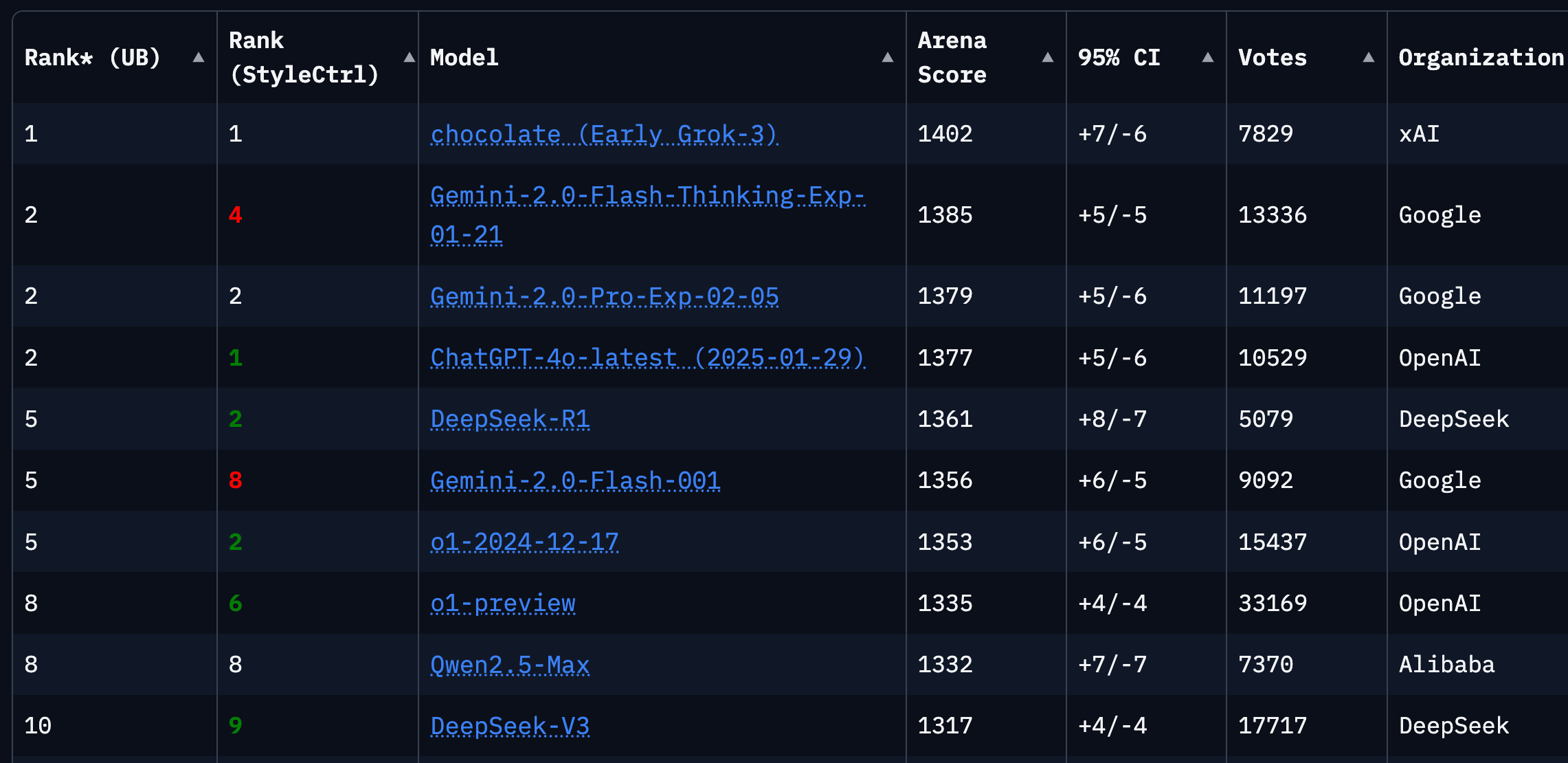
There’s a lot happening in AI these days, as you know. I don’t want to bombard you with every detail, but some developments are too important — or too uncertain, a fork in the road ⑂ — to ignore and are worth highlighting.
One of these is whether xAI and Grok can come from behind and become an important player at the frontier. They’ve been moving fast and, for now, seem to have caught up with the leaders:
Pre-training of Grok 3 was completed in early January, although the xAI team said training was ongoing. […]
The model was developed in two stages: initially, 122 days of synchronous training was done on 100,000 GPUs, followed by 92 days of scaling up to 200,000 GPUs.
“It took us 122 days to get the first 100K GPUs up and running, which was a monumental effort. We believe it’s the largest fully connected H100 cluster of its kind. But we didn’t stop there. We decided to double the cluster size to 200K,”
xAI also plans to open-source Grok-2 once Grok-3 is mature.
As you can see from the screenshot above, Grok 3 took the #1 spot on the LLM Arena Leaderboard — where blind comparison of outputs between random models determines rankings based on user preferences. Grok is the first to cross 1400, dethroning Gemini 2 Flash Thinking.
My early experience with Grok 3 has been limited to 45 minutes, but so far I'm impressed by both the quality of the results AND the speed of the model. I’m looking forward to playing more with Grok 3 to see if I like the “flavor” of the model and if it is obviously smarter than other models at the kind of things I do. Benchmarks are useful, but at the end of the day, what matters is finding a model that fits your style and tasks the best. That personal fit factor might explain why Claude Sonnet 3.5 has so many fans.
xAI is in talks to raise $10 billion at a $75 billion valuation, so clearly expectations are high. 💰💰💰💰💰💰🔮🚀
Success will ultimately depend on two factors: whether the velocity of progress can exceed other frontier labs AND whether they can figure out the distribution. OpenAI has built a consumer brand while Anthropic hasn’t, and the difference in usage is stark.
xAI’s main distribution channel is Twitter/X, but is that enough? Once in a while, I’ll click on the Grok button next to a tweet, but that’s probably less than 1% of my total LLM usage.
If xAI can pull far enough ahead of others, it may meet the activation energy required for users to change their habits and switch. But Grok 3’s time at the top could be short-lived. Coming soon are GPT-4.5 and Anthropic’s new hybrid model with reasoning capabilities. Meta’s Llama 4 is also training on a very large cluster and is expected sometime this year, and Google has been doing very good work lately too. Then there’s GPT-5 on the horizon…
Could Grok get lost in an increasingly crowded and commoditized field and, due to weaker distribution, stay second-tier behind OpenAI, Google, and Meta?
Additional Points on Grok 3
There's some irony in the fact that Elon Musk has been attacking OpenAI for being closed, yet Grok 3's reasoning mode also hides some of its chain of thought output. It’s also worth noting that Musk only talks about opening up the old, Grok 2 model, and not his leading model. That makes them less open than Meta and DeepSeek.
Andrej Karpathy, a very respected name in the field and former head of Tesla’s AI efforts, wrote a review of Grok 3. He’s impressed:
As far as a quick vibe check over ~2 hours this morning, Grok 3 + Thinking feels somewhere around the state of the art territory of OpenAI's strongest models (o1-pro, $200/month), and slightly better than DeepSeek-R1 and Gemini 2.0 Flash Thinking. Which is quite incredible considering that the team started from scratch ~1 year ago, this timescale to state of the art territory is unprecedented.Grok 3 will also include DeepSearch (yes, everyone's using similar names - it's getting confusing), a tool similar to OpenAI and Perplexity’s ‘Deep Research’. I can use reasoning to process more complex queries into a research plan, look for online sources, and then generate a report. It’ll be interesting to compare to others, and whether anyone can remain differentiated or if this tool rapidly becomes a commodity too.
🥽🦅🇺🇸 Microsoft Partners with Anduril to Deliver the U.S. Army’s $22bn AR Headset Program 💰💰💰💰
Anduril is on a roll:
Microsoft Corp. and Anduril Industries today announced an expanded partnership to drive the next phase of the U.S. Army’s Integrated Visual Augmentation System (IVAS) program. Through this partnership agreement, and pending Department of Defense approval, Anduril will assume oversight of production, future development of hardware and software, and delivery timelines.
This agreement also establishes Microsoft Azure as Anduril’s preferred hyperscale cloud for all workloads related to IVAS and Anduril AI technologies.
This is a natural fit for Palmer Luckey who, before co-founding Anduril, founded Oculus, the VR headset startup that was later acquired by Facebook/Meta.
🧪🔬 Science & Technology 🧬 🔭

Brute Force or Breakthrough? Unpacking OpenAI’s o3 Progress (Log Scales and Big Inference Bills) ✋🏎️
Toby Ord has written a very interesting piece putting OpenAI’s impressive progress with o3 in context. He throws a bit of cold water on some of the excitement of the past few weeks.
To summarize his argument: Yes, o3 did great on very difficult benchmarks, but it accomplished this mostly through brute force. Compute over breakthrough, a very costly crown 👑💰💸
If you look at the graph above, what may be easy to overlook is that the X-axis is a log scale. o3-high performed great but used thousands of times more compute than even o1-high, which is already way more computationally intensive than GPT-4o.
Here are a few highlights from the post:
Improving model performance by scaling up inference compute is the next big thing in frontier AI. But the charts being used to trumpet this new paradigm can be misleading. While they initially appear to show steady scaling and impressive performance for models like o1 and o3, they really show poor scaling (characteristic of brute force) and little evidence of improvement between o1 and o3.
On the X-axis log scale:
We often see charts where the y-axis is on a log scale — these help fit the dramatic exponential progress a field is making onto a single chart without the data points bursting through the top of the frame. [...]
But in these new charts for inference scaling it is the x-axis that’s a on log scale. Here the linear appearance of the data trend is overstating how impressive the scaling is. What we really have is a disappointing logarithmic increase in capabilities as more compute is thrown at the problem. Or, put another way, the compute (and thus the financial costs and energy use) need to go up exponentially in order to keep making constant progress. These costs are rocketing up so much that the expenses of these models would be bursting off the side of the page if not for the helpful log scale.
Brute force vs brilliance and 🍎 vs 🍊:
An exponential increase in costs is the characteristic signature of brute force. It is how costs often rise when you just try the most basic approach to a problem over and over again. That doesn’t mean that o1 or o3 are brute force — sometimes even refined solutions have exponential costs. But it isn’t a good thing. [...]
The message most people seem to have taken from it is that the o3 results (in yellow) are much better than the o1 results (e.g. that the shift to o3 has solved the benchmark or has reached human performance).
But this isn’t clear. The systems are never tested at the same level of inference cost, so this chart doesn’t allow any like-for-like comparisons.
While the yellow dots are higher, they are also a lot further to right. It doesn’t look like that much but remember that this is a logarithmic x-axis. The ‘low’ compute version of o3 is using more than 10 times as much inference compute as the low compute version of o1, and the high compute version of o3 is using more than 1,000 times as much. It is costing about $3,000 to perform a task you can get an untrained person to solve for $3.
Reasoning models leaning on test-time compute are still the future, and OpenAI says all models post-GPT-4.5 will integrate reasoning.
When "strawberry" (🍓) was first announced, I wrote about wanting models to have a dial or level that you could use to tell the model “Ok, this one is *really* important, think about it for as long as you need, I don’t care if it takes a week” so that you could dial in the level of inference (and hopefully intelligence).
That looks like it’s happening!
But for the level of intelligence demonstrated by o3-high in the ARC-AGI benchmarks to diffuse out to everyone, it’ll take a lot of cost optimizations, likely through a mix of faster hardware (Jensen’s always working on that) and algorithmic/architectural breakthroughs (more on that below).
How long that will take is anyone’s guess, but the story isn’t quite as simple as “just a few months after o1 came out, o3 is WAY better and a huge breakthrough”.
🗣️🗣️ Interview: Google’s Jeff Dean & Noam Shazeer (Transformer co-creator, and I don’t mean the 1980s TV show…) 🤖🔍
Great interview by friend-of-the-show Dwarkesh Patel:
The second half is particularly compelling. They dive into model architecture (how to get even more modular, continuous training, etc) and discuss the implications for inference needs and scaling data-center buildouts.
Here are some highlights:
Dwarkesh Patel: One thing I've heard you talk a lot about is continual learning, the idea that you could just have a model which improves over time rather than having to start from scratch. Is there any fundamental impediment to that? Because theoretically, you should just be able to keep fine-tuning a model. What does that future look like to you?
Jeff Dean: Yeah, I've been thinking about this more and more. I've been a big fan of models that are sparse because I think you want different parts of the model to be good at different things. We have our Gemini 1.5 Pro model, and other models are mixture-of-experts style models where you now have parts of the model that are activated for some token and parts that are not activated at all because you've decided this is a math-oriented thing, and this part's good at math, and this part's good at understanding cat images. So, that gives you this ability to have a much more capable model that's still quite efficient at inference time because it has very large capacity, but you activate a small part of it. [...]
one limitation of what we're doing today is it's still a very regular structure where each of the experts is the same size. The paths merge back together very fast.[...]
I think we should probably have a more organic structure in these things. I also would like it if the pieces of those model of the model could be developed a little bit independently. [...]
I think it would be really great if we could have a small set of people who care about a particular [thing] go off and create really good training data, train a modular piece of a model that we can then hook up to a larger model that improves its capability
That makes a lot of sense and would allow faster iteration on models AND for weaknesses of a particular model to be addressed much faster (ie. just focus on creating a module/expert that is actually good at that thing and plug it in).
Here’s an interesting bit on distillation used inside of a mixture of experts model to scale up and down as you need more intelligence vs cheaper/faster inference:
Jeff Dean: I do think distillation is a really useful tool because it enables you to transform a model in its current model architecture form into a different form. Often, you use it to take a really capable but large and unwieldy model and distill it into a smaller one that maybe you want to serve with really good, fast latency inference characteristics.
But I think you can also view this as something that's happening at the module level. Maybe there'd be a continual process where you have each module, and it has a few different representations of itself. It has a really big one. It's got a much smaller one that is continually distilling into the small version.
And then the small version, once that's finished, you sort of delete the big one and you add a bunch more parameter capacity. Now, start to learn all the things that the distilled small one doesn't know by training it on more data, and then you kind of repeat that process. If you have that kind of running a thousand different places in your modular model in the background, that seems like it would work reasonably well. [...]
you can have multiple versions. Oh, this is an easy math problem, so I'm going to route it to the really tiny math distilled thing. Oh, this one's really hard…
There’s more good stuff in there, I recommend you check out the whole thing, or at least the second half if the model architecture part is what most interests you.
👋
🥛💪 High-Protein Milk

You may already know about this, but if not, high-protein milk is a pretty painless way to potentially get decent health benefits over time.
Milk is a fairly regional thing, so you’ll have to look up your local brands, but my local version has 18 grams of protein per cup instead of approximately 9 grams of protein per cup for regular milk.
It costs a couple of bucks more, but considering how important it is to get enough protein for maintaining and growing muscle mass — and how important muscle mass is to overall health and longevity — this is a no-brainer.
A decent heuristic for adults is to aim for about 1 gram of protein per day per pound of lean body mass. I don’t always get there, but it’s pretty easy to make a whey protein smoothie using this milk that gets me 40-50 grams of protein in one go.
This is doubleplus good if you have kids/teenagers, as their growth requires even more protein and calcium per unit of body weight, especially if they are very physically active.
🎨 🎭 The Arts & History 👩🎨 🎥
🎌 ‘Shōgun’ (2024) 🏯 — A Masterclass in Historical Drama
🚨 The video above 👆 compares the 2024 TV series to the 1980 TV series and includes tons of spoilers. Only watch if you’ve seen Shōgun. 🚨
🚨 My review below👇 has very very mild spoilers, I’ve written it for someone who hasn’t seen the show 🚨
I finally watched Shōgun, a show that's been on my watchlist since it came out because so many people whose taste I trust recommended it. And I’m glad to say that it lived up to those high expectations!
Right from the first episode, I was very impressed. The production is firing on all cylinders with its exceptional writing, acting, cinematography, music, costumes, environments, and sets. Although the depth of Japanese culture from that era was at times disorienting for someone not already familiar with it, it’s a good thing. The 'strangers in a strange land' aspect added to the intrigue 👍
The torture scene in the pilot was almost too much for me. As I get older, my tolerance for such scenes on screen has diminished. I’m glad I had heard that not every episode was like that, because I may have bounced off at that point otherwise.
Episode two was phenomenal, taking a slower burn approach compared to the first, but it was more enjoyable in many ways. Some scenes were just incredible, like the one with the map. The intricate machinations and high-stakes strategies of the characters were just opaque enough to be intriguing yet legible enough to follow along.
Anna Sawai, who plays Mariko, can do a lot with just a glance. Toranaga's portrayal by Hiroyuki Sanada was also very magnetic, radiating quiet intelligence. Sanada is also a producer on the show, and they did it right by having Japanese experts on the time period help design everything (sets, costumes, movements, dialogue, ceremonial details, etc).
I love a show where the action is so well done, but the quiet dialogue moments are equally powerful, making the characters feel alive and real. The whole world feels immersive and lived-in.
A small but notable detail: the depiction of arrows in this show is particularly effective. They look realistic and scary.
I loved the scene where the two ship pilots are trash-talking with a sub-text of showing respect among enemies.
It's amusing to see how bureaucratic Japan was at the time, with a protocol for everything, even for plotting an enemy's demise. Using bureaucracy as a weapon is elevated to an art form here!
Episode 9, 'Crimson Sky,' was one of the strongest episodes of TV I've seen in years.
Mariko is such an interesting and unique character, with Anna Sawai playing her so well that she steals the scene every time she's on screen. So much happens under the surface as she struggles to maintain her composure. It's no surprise that both Anna Sawai and the director of photography won Emmys for this episode, highlighting the exceptional quality of their work. I’m glad she got such a good showcase.
To me, Shōgun is a masterclass in historical drama. It's a show that respects its audience and doesn’t hand-hold it too much, keeping things nuanced, and taking enough left-turns to keep the audience guessing. I can confidently say that it is one of the finest television produced in recent years and I highly recommend it.
I’m hooked and added the James Clavell novel to my ‘to read’ list in Margins. I may also watch the 1980 version at some point (I hear it’s quite good, but I don’t know how well it has aged and for viewers without nostalgia for having seen it back then).
One thought I've had recently around AI is that if we move toward a Chatbot-style interface with the Web, far fewer requests will be made to third-party websites. This will negatively impact some cloud services, and companies like Cloudflare, Akami, any traffic-based company really. I had been thinking of AI as purely additive to infrastructure, but with further thought that may not be the case. .
It could be wholly anecdotal, but the options for air travel seem to have just gotten shitter. I have three international airports within reasonable driving distance, and I rarely find a flight with a reasonable departure, arrival or layover times.
Leaving for the airport at 3 or 4 in the morning to catch a flight, having a 3 or 4 hour layover, and spending 16+ hours traveling for a 2 or 3 hour flight is pretty exhausting.
On a positive note, at least security in many airports has gotten faster, and you no longer have to strip down or piecemeal out every electronic device into totes. However, that's like only having to each one shit sandwich after being made to eat two.