

578: Jensen Huang, Sputnik vs DeepSeek, Meta's GPU Tents, Mark Chen, Grok 4, OpenAI Stargate, Masa, Oracle, Microsoft Struggles, Netflix, and Becoming the Main Character
"the mobility scooter of the mind"

Sometimes men come by the name of genius in the same way that certain insects come by the name of centipede; not because they have a hundred feet, but because most people cannot count above fourteen.
—Georg Christoph Lichtenberg

🚧⚠️🧠🚲🛵 AI presents us with a bifurcation point.
A fork in the road.
It can be the golden age for autodidacts.
It’s now easier than ever to ask questions about anything and everything and to learn from a tireless 24/7 polymathic private tutor.
You could already learn anything pre-AI, but now the barriers to entry are lower and the tools are more powerful than ever. More people will have more leverage.
If you use it right, AI is the best bicycle for the mind ever devised. It allows you to amplify your abilities, get in better cognitive shape, and go much further than you could without it.
But to many others, it will be the mobility scooter of the mind, replacing worthwhile effort, allowing them to get cognitively out-of-shape, lazy. It’s like skipping to the last page of the crime thriller to find out who the killer is, a shortcut that robs the meaning from the outcome.
Derek Thompson put it well:
Writing is not a second thing that happens after thinking. The act of writing is an act of thinking. Writing *is* thinking.
Students, academics, and anyone else who outsources their writing to LLMs will find their screens full of words and their minds emptied of thought.The way that I’ve found to get the most out of AI in a way that strengthens my mind (hopefully!) is to use it extensively during the research phase of anything:
Ask more questions. About everything.
Don’t just send a query and read the response. Iterate, go deeper, go back-and-forth, ask for double-checking, for clarifications, for more detail.
Click source links and make it a game to hunt for errors and hallucinations (they’re there).
Ask for similar things, connections, nearest neighbors, or even opposites. Ask it to play devil’s advocate against an idea.
Ask for recommendations of primers and best places to start on a topic, and then go read those.
This all helps you have a better starting point. You’ll have covered more ground, explored more possibilities, and understand the context better. It’s a way to build a stronger foundation on which to build.
But then you have to do the work yourself.
Your mind has to go through the ideas. You have to feel their shape and weight. It’s the only way to integrate new knowledge and make it your own. It’s the only way to become good at having ideas and at judging their worth.
Like most things, you can only get good with practice, practice, practice.
Once you’ve built something, the AI tools can play a big role as editor/first reader/fact-checker/copyeditor. This polish phase can help make your thoughts cleaner and clearer, but they have to be your thoughts.
Don’t outsource the journey. The destination is meaningless without it.
Even if you fool others by passing off the AI’s output as your own, you’re fooling yourself too, just in a different way. You may feel like you learned something because you still read the words, but chances are, the ideas haven’t stuck, new neural pathways haven’t formed.
A musician who wrote a song knows it in a very different way than a listener who has heard it once 🎸
Pick the path that leads to higher cognitive ground 🆙
🥳🎂🚢⚓🗓️ July 20 marked the 𝟝𝕥𝕙 𝕒𝕟𝕟𝕚𝕧𝕖𝕣𝕤𝕒𝕣𝕪 𝕠𝕗 𝕥𝕙𝕚𝕤 𝕤𝕥𝕖𝕒𝕞𝕓𝕠𝕒𝕥!
It’s funny how that feels like both a really long time and a really short time.
My youngest boy was barely two years old when I clicked “Create an Account” on Substack, and now he can read and write.
If we count podcasts and text interviews, I’ve published over 6️⃣0️⃣0️⃣ Editions.
That feels like a lot!
And yet, there are so many things that I’ve been meaning to write about and haven’t had a chance to yet.
Bottom line: I feel lucky that I get to type stuff on my keyboard and it beams photons into your eyeballs. We both have these words echoing in our brains, separated by time and space. That’s pretty magical.
I appreciate you, and I couldn’t do it without your support! 💚 🥃
I wonder what Edition #1,000 will be about… 🤔
🏦 💰 Business & Investing 💳 💴
🗣️ Interview: Jensen Huang 🇺🇸🇨🇳🏗️🤖🚧
Back in 2021, former Google CEO Eric Schmidt created a think tank called Special Competitive Studies Project. SCSP's CEO is Ylli Bajraktari, the former executive director of the National Security Commission on Artificial Intelligence (NSCAI), and he has a podcast.
I enjoyed his recent interview with Jensen 👆
It gives a window into how he thinks about America’s AI leadership and how he would approach competing with China. If I had to sum up his approach, I’d say it’s focused on running as fast as possible, rather than trying to slow others down. 🏃♂️🚧
Winning by out-competing.
Of course, he’s talking his book, so you should calibrate for that, but he makes some good points.
Personally, over time I’ve become convinced that the U.S. should sell GPUs to China — maybe not the very cutting edge, but relatively close to it — while restricting the sale of cutting-edge semiconductor manufacturing equipment.
This would create a much better dynamic where Nvidia and CUDA get benefits of scale and remain the standard in China (at least for longer). Meanwhile, export controls are much more likely to be successful when they target a relatively small number of specialized pieces of equipment rather than millions of GPUs that are more easily smuggled or accessed remotely.
🚀 🛰️ ‘Sputnik vs. DeepSeek Moment’ + The Rise of Zero-Sum Thinking
This segues nicely into these two pieces by Alex Tabarrok.
I don’t agree with every single framing and detail, but they’re good food for thought on how to approach competition with adversaries and how non-zero-sum vs zero-sum thinking leads you in different directions:
In 1957, the Soviet Union launched Sputnik triggering a national reckoning in the United States. […]
The response was swift and ambitious. NSF funding tripled in a year and increased by a factor of more than ten by the end of the decade. The National Defense Education Act overhauled universities and created new student loan programs for foreign language students and engineers. High schools redesigned curricula around the “new math.” Homework doubled. NASA and ARPA (later DARPA) were created in 1958. NASA’s budget rocketed upwards to nearly 5% of all federal spending and R&D spending overall increased to well over 10% of federal spending. Immigration rules were liberalized (perhaps not in direct response to Sputnik but as part of the ethos of the time). Foreign talent was attracted. Tariff barriers continued to fall and the US engaged with international organizations and promoted globalization..
The U.S. answered Sputnik with bold competition not an aggrieved whine that America had been ripped off and abused.
What is the U.S. doing today?
America’s response to rising scientific competition from China—symbolized by DeepSeek’s R1 matching OpenAI’s o1—has been very different. The DeepSeek Moment has been met not with resolve and competition but with anxiety and retreat.
Trump has proposed slashing the NIH budget by nearly 40% and NSF by 56%. The universities have been attacked, creating chaos for scientific funding. International collaboration is being strangled by red tape. Foreign scientists are leaving or staying away. Tariffs have hit highs not seen since the Great Depression and the US has moved away from the international order.
What is at the root of this?
In my view, the best explanation for the starkly different responses to the Sputnik and DeepSeek moments is the rise of zero-sum thinking—the belief that one group’s gain must come at another’s expense.
Reflexivity can take over, and it can become self-fulfilling, which is very dangerous:
The looming danger is thus the zero-sum trap: the more people believe that wealth, status, and well-being are zero-sum, the more they back policies that make the world zero-sum.
Restricting trade, blocking immigration, and slashing science funding don’t grow the pie.
Zero-sum thinking leads to zero-sum policies, which produce zero-sum outcomes—making the zero sum worldview a self-fulfilling prophecy.
The specifics today shouldn’t be the same as yesterday. But the kind of thinking may need to be the same.
⛺ When Time is of the Essence: Meta is Building AI Data-Centers in… Tents?! 🎪

You know what this reminds me of?
When Tesla was in the middle of ‘production hell’ back in 2018, as they were ramping up manufacturing for the Model 3, they built an assembly line under a giant tent in the parking lot of the Fremont plant in just three weeks.
They were ridiculed for it at first (remember TSLAQ?), but in the end, it helped them move faster.
It looks like Zuck is adopting that playbook, maybe inspired by seeing xAI spin up a giant training cluster (Colossus) in just 122 days.
“I wanted them to not just take four years to build these concrete buildings," Zuckerberg said. "So we pioneered this new method where we’re basically building these weatherproof tents and building up the networks and the GPU clusters inside them in order to build them faster.”As SemiAnalysis reports:
Zuck threw his entire Datacenter playbook into the trash and is now building multi-billion-dollar GPU clusters in “Tents”! [...]
This design isn’t about beauty or redundancy. It’s about getting compute online fast! From prefabricated power and cooling modules to ultra-light structures, speed is of the essence as there is no backup generation (ie no diesel generators in sight).
They’re also doing their own power generation with gas turbines at the Ohio ‘Prometheus' super cluster that is under construction:
when the local power grid couldn’t keep up, Meta went full Elon mode. With help from Williams, they’re building two 200MW on-site natural gas plants
Add this to the talent war, and it’s clear that Zuckerberg is going *all out* to try to catch up and, he hopes, lead the pack. It’ll be fascinating to see if it works, or if despite all this talent and compute, some other ingredient is still missing to make all this cohere into great AI products.
💰 OpenAI’s Mark Chen, the Billion Dollar Man 💰
On the topic of the talent war, it’s interesting that OpenAI’s chief research officer, Mark Chen, may have planted the seed of that idea in Zuck’s head (which he may now regret):
In the spring, Zuckerberg approached OpenAI’s chief research officer, Mark Chen, for a casual catch-up and ended up asking him for advice on how to improve his company’s generative-AI organization. Given how much money Meta was already spending on hardware and computing power to train AI—more than 100 times what it was spending on humans—Chen suggested that Zuckerberg might want to invest more in talent [...]
Zuckerberg asked Chen if he would consider joining Meta—and what it would take to bring him aboard.
A couple hundred million dollars? A billion?
Chen demurred, saying he was happy at OpenAI. But the conversation helped plant the seeds of an idea. (Source)
A billion dollars.
Labor might just be the new capital.
🥉 Grok 4 Ranks 3rd on LLM Arena’s Leaderboard (for text)
Speaking of missing ingredients:
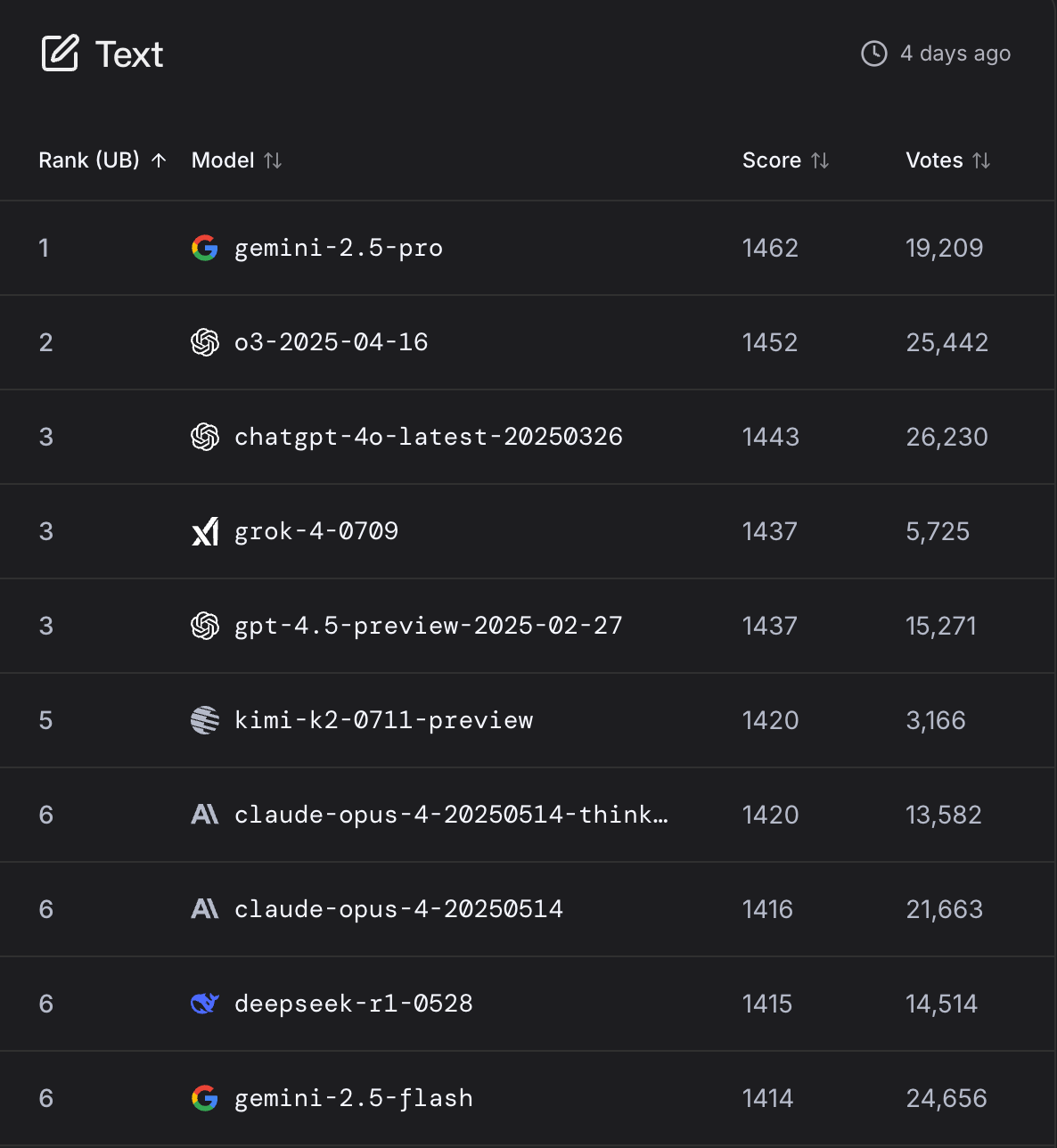
Grok 4 is currently tied for 3rd place on LLM Arena's text Leaderboard, neck-and-neck with the venerable GPT-4o (from March 2025! Though it has had some updates, as documented in release notes…).
It still hasn’t caught up with Gemini 2.5 Pro (🥇) and OpenAI’s o3 (🥈), at least in this benchmark. And it doesn’t make the top 10 on the coding board 🤔
On the one hand, Grok 4 did great on many of the most difficult benchmarks and probably is superior when it comes to the most complex tasks.
But on the other, LLM Arena does blind ELO ranking of models for everyday queries and tasks, which is probably a lot closer to how 98% of people actually use these models.
It’s one thing to have a model that can solve PhD math problems, but if most users don’t find it better than older, dumber models, it may be hard to get people to switch.
In fact, I'm already seeing a lot fewer mentions of Grok 4. It already seems to be fading from the zeitgeist… *checks watch* ⌚ a whole 2 weeks after it was released. That’s a lot of billions of dollars and a lot of all-nighters for not much time in the spotlight 😬
Maybe if xAI can pull ahead with Grok 5 because they have a higher cadence than others — kind of like how Nvidia compressed GPU development cycles from 24 to 18 months back in the 2010s — maybe that can convert into more adoption (outside of people asking it to explain Tweets). But keeping up and beating the other big labs is going to be difficult with Meta going berserk and OpenAI rapidly aggregating a billion+ users.
The hope for xAI is to find a niche, much like how Anthropic has decided to go all-in on programming and agentic workflows. I’m not sure what that niche could be, though. Maybe robotics to tie in with Musk’s other ventures? 🦾
🏗️⚠️ OpenAI’s Stargate is off to a slow start (Masa & Altman not on the same page?) ⏳
Something’s not right here:
Six months after Japanese billionaire Masayoshi Son stood shoulder to shoulder with Sam Altman and President Trump to announce the Stargate project, the newly formed company charged with making it happen has yet to complete a single deal for a data center.
Son’s SoftBank and Altman’s OpenAI, which jointly lead Stargate, have been at odds over crucial terms of the partnership, including where to build the sites, according to people familiar with the matter.
This could leave a window for Zuck to zip by 🤔
While the companies pledged at the January announcement to invest $100 billion “immediately,” the project is now setting the more modest goal of building a small data center by the end of this year, likely in Ohio, the people said.
Sam Altman isn’t just twiddling his thumbs waiting for Masa. He’s making a bunch of other deals for compute.
The recent partnerships with Google GCP, Oracle, and CoreWeave are probably part of that. Taken together, they represent nearly as much compute as Stargate promised to deliver this year.
The latest deal with Oracle is HUGE:
OpenAI and Oracle announced they will develop 4.5 gigawatts of additional US data center capacity in an expanded partnership, furthering a massive plan to power artificial intelligence workloads.
OpenAI has yet to name the data center sites it will codevelop with Oracle, but states including Texas, Michigan, Wisconsin and Wyoming are under consideration. Together with its facility being built in Abilene, Texas, the company said it will have more than 5 gigawatts total in capacity, running on more than 2 million chips for AI work. [...]
While OpenAI labeled the data center expansion with Oracle as part of its Stargate project, SoftBank isn’t financing any of the new capacity (Source)
Softbank invested $30bn in OpenAI, but that investment won’t be worth as much as it could be if they can’t also help provide it the massive compute it needs to stay ahead of the competition (Stargate said it would invest half a trillion bucks by 2029).
🧪🔬 Science & Technology 🧬 🔭
🇨🇳📦📦📦🏷️ Nvidia has limited stocks of H20 GPUs for China and is not making more (for now)
Get them while supplies last:
The AI chip giant has told its customers it has only limited stocks of the H20 chips [...] And right now, Nvidia doesn’t plan to restart production.
Why?
These supply chains don’t turn on a dime, and things move so fast that the H20 is already getting old…
The U.S. government’s April ban on sales of the H20 chips forced Nvidia to void customer orders and cancel manufacturing capacity it had booked at [TSMC], which makes the chips, according to two people with direct knowledge of the order cancellation.
Reversing those moves won’t be easy. TSMC’s facilities are running at full capacity, and the company has shifted its production lines used for the H20 to other chips for other customers (Source)
For now, Nvidia will only fill orders until it uses up the existing stock of H20s.
They had started to create a Chinese version of their Blackwell chips, but as things stand, it wouldn’t be permitted in China. I wouldn’t be surprised if Jensen is lobbying the US government to allow it, as otherwise, that void will be filled by Huawei, further accelerating its rise.
🤖🪛😅🧰 Microsoft’s In-House AI Chip Effort is Struggling
All hyperscalers would love to reduce their dependence on Nvidia, or at least have good alternatives to negotiate better pricing on GPUs. But that’s not an easy task.
Microsoft began developing its first AI chip in 2019 and announced the chip—dubbed Maia 100—in 2023. [...]
But behind the scenes, Microsoft has mainly relied on the Maia 100 for internal testing as opposed to real-world usage. The chip isn’t powering any of its AI services [...]
Following the release of Maia 100 in 2024, Microsoft launched an aggressive strategy to build three successor chips—code-named Braga, Braga-R and Clea—with plans to deploy them in its data centers in 2025, 2026 and 2027, respectively
It's worth noting that these are inference chips, not training chips.
Designing semiconductors is one of the hardest things humans do, and Nvidia is a fast-moving target. If you run into trouble and have some delays, by the time your chip comes out, it may not even be competitive anymore, even if you factor in not having to pay Nvidia’s margins.
Braga, is facing a delay of at least six months, pushing its mass production from 2025 to 2026, said three of the people involved in the effort. When it finally goes into mass production next year, it’s expected to fall well short of the performance of Nvidia’s flagship Blackwell chip, released in late 2024 [...]
Microsoft’s AI chips won’t come close to competing with Nvidia’s offerings until at least Maia 300, code-named Clea, which is based on an entirely new chip design compared with Braga
That’s if Clea isn’t late too! Or if, in the meantime, Nvidia doesn’t come up with a new architectural innovation that takes a while to catch up with.
If you come at the king, you better not miss! 👑
What about Google? Its TPU efforts have been the most successful of any hyperscaler, and they are widely used by the company for both training and inference.
But there are still some challenges:
Google has faced other kinds of problems. Last year, Google began collaborating with Taiwan’s MediaTek on the design of its next-generation TPUs. But the partnership suffered a setback: Key members of MediaTek’s team responsible for the TPU’s networking technology, a key part of AI processing that allows multiple chips to work together in unison, left to join Nvidia (Source)
Like with AI, talent is a bottleneck when it comes to cutting-edge silicon design.
📺 It Begins: Netflix Used Generative AI to Cut Costs on a TV Show’s Visual Effects 🎨🤖
Netflix announced it had used generative AI for a special effects sequence and it’s causing a bunch of controversy in the industry.
I looked for the specific sequence online, and as far as I can tell, it lasts barely a second or two and isn’t that big a deal, especially since the rest of the show has a ton of traditional SFX.
But the seal has been broken.
Ted Sarandos explains that the tech is allowing the show to do things that it wouldn’t have the budget for otherwise, expanding storytelling options:
The generative AI used in The Eternaut helped its production team to complete a sequence showing the collapse of a building in Buenos Aires 10 times faster than if they had used traditional special effects tools, he said.
"The cost of it would just wouldn't have been feasible for a show in that budget.
"That sequence actually is the very first [generative] AI final footage to appear on screen in a Netflix original series or film. So the creators were thrilled with the result," said Mr Sarandos. (Source)
I expect a pretty big backlash on the use of AI in films and TV shows, especially since we’ll probably go through a cycle similar to the original CGI SFX cycle where people think they hate all of it, but they just hate bad CGI…
It takes a while for artists and directors to learn how to use the new techniques well and for the tech to mature.
Today, there’s a lot of CGI in almost everything, and when it’s well done (replacing skies, buildings, extending horizons, adding vehicles on the road, etc), most viewers don’t even notice.
But like plastic surgery, it’s the bad ones that jump out at you, and it’s easy to assume that they’re all like that.
🎨 🎭 The Arts & History 👩🎨 🎥

🗣️📖 Podcast: Becoming the Main Character 🧙♂️⚔️🛡️🍸
In recent months, BTMC has become one of my favorite new podcasts. I had the pleasure of getting to know its creator, Jameson Olsen, and even collaborating with him on some projects (more on this later!).
I encourage you to check out BTMC. Picture David Senra’s Founders, but for fiction rather than biographies. There’s a good variety of stories covered, from The Great Gatsby to Dune.
It’s a bit like listening to a hybrid between an audiobook and a podcast (a podbook? 🤔).
It works as pure entertainment, but there’s also a lot of analysis and dot-connecting that helps me learn more about these stories specifically, and about storytelling more broadly.
And it isn’t just for books you’ve already read. It’s also a great way to discover and explore stories that you’re interested in but just never got around to reading.
We're going to discover the world's greatest stories and the important lessons they hold. Each episode will take you on a journey, transforming how you see life through literature's most powerful narratives.
Hamlet will teach you why you shouldn't put off making that big move. Jo March exemplifies committing to your business idea when no one believes in you. Captain Ahab’s struggle with Moby Dick is a warning to not let future relationships be ruined by the memories of your exes.
Fiction for your non-fiction life.
Tune in, be changed.I’ve been listening to his Lord of the Rings epic series, and I’m almost finished with Two Towers. He even does voices! Highly recommended, check it out.
As always, great stuff. I appreciated your take on research funding and competition with China. It holds a lot of truth. However, one point that is worthy of mention is that a lot of R&D agencies in the US government have become bloated and no longer use much of the investments in them to do R&D. The cuts to these agencies, as I see it, are largely being used to re-focus them. As you highlight though, American society has to re-focus on competition also, and that is an even greater hurdle when dealing with a hungrier competitor. Previous empires have fallen when things were too good for them for too long. It is hard to turn very large ships like the nation of the US, especially when tools like AI can be used to make life easier instead of learning and self-improvement easier.
Can't wait to check out BTMC. Just finishing Return of the King and the LoTR sounds like a great place to start!