

594: Innovation at Scale, AMD Paying OpenAI to be Customer, Dylan Patel on AI Buildout, Buffett Letters, U.S. Defense Flaws, TSMC, Building Ghosts, and The Town
"Great work has a way of convincing most skeptics."

Do not become a mere recorder of facts, but try and penetrate the mystery of their origin.
—Ivan Pavlov
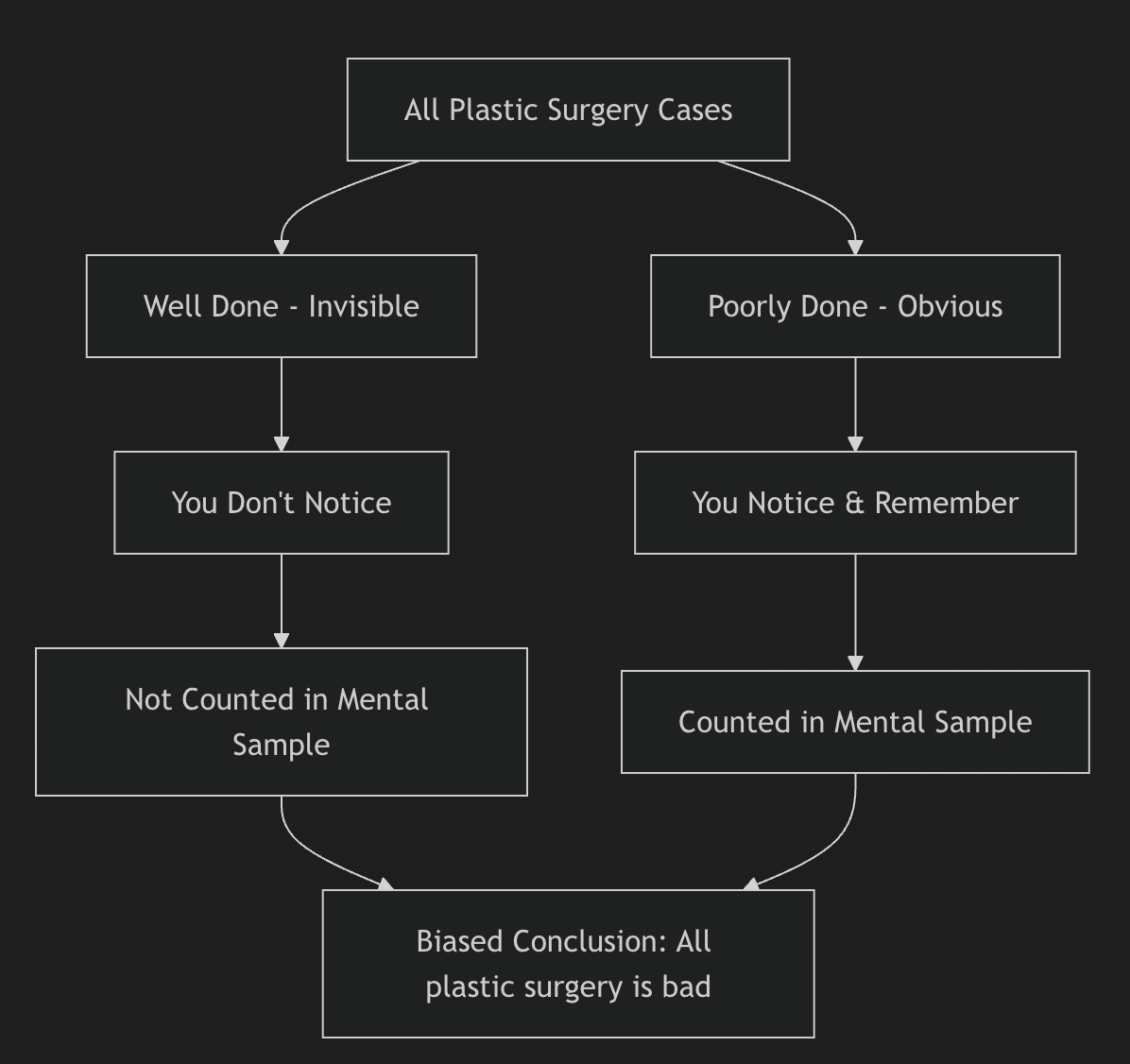
🛀💭🎨🤖🎥🍿📝📖🎭 There’s a phenomenon I’ll call the ‘Plastic Surgery Effect’.
This isn’t about plastic surgery, but it’s a good way to explain it, and once you’re aware of it, you see it everywhere 👀
The common version of this goes something like:
“All plastic surgery looks unnatural, I can always tell when someone’s had work done” or “plastic surgery always makes people look fake.”
The problem, of course, is that they’ve only noticed the bad outcomes.
The same thing happens with computer-generated special effects in films and TV. Most ‘I hate CGI’ complaints are really ‘I hate bad CGI.’
I’m always reminded of watching a ‘making of’ for the HBO miniseries ‘John Adams’ (I rarely ever hear about it anymore, but it’s *great*, check it out). They showed how they digitally added all kinds of things to many, many scenes to recreate the late 1700s (set extensions, digital mattes, etc). And I realized that watching the show, I had never noticed or even thought about what was done practically and what was CGI.
I was just engrossed in the story and immersed in the world the show created.
When you do it well, it’s the result that matters. When it sucks, you start looking for things to blame (the tools, the people, the parent corporation, whatever).
Bad Marvel feels weightless and like a video game. Villeneuve’s Dune may use as much CGI in many shots, but they feel tangible and grounded in reality. Ultimately, it comes down to taste and judgment, making the right artistic choices and using the tools well.
The same thing happened when music recording, editing, and distribution went from analog to digital. For decades, musicians and engineers perfected the art of analog recording, so they were really good at it. When digital tools came out, they did sound worse. But this didn’t mean that “digital” itself couldn’t be good, just that it wasn’t there yet. The tools had to mature for a while, and people had to relearn workflows and break old habits to get good results.
I believe we’ll see the same evolution with AI.
People who think they “hate AI” really just hate *bad* AI. As the tools improve and creators master them, we’re going to see much more high-quality AI-assisted stuff. There will still be a deluge of slop, just like most things created by humans are very bad, but the *absolute number* of good things will rise.
Great work has a way of convincing most skeptics.
When something is really good, the tools fade away.
If the next Breaking Bad happens to be made with the help of a lot of AI, it won’t matter to most people who are enjoying it (some people have a religious fervor about it and nothing will convince them, but most people aren’t in that camp).
🔎📫💚 🥃 Exploration-as-a-service: your next favorite thing is out there, you just haven’t found it yet 👇
🏦 💰 Business & Investing 💳 💴
🍎🌎 OpenAI & Apple: Innovating at SCALE ⛰️
Innovation is always hard, but innovating for a large fraction of the planet’s population all at once is hardest. 🌎
If Apple wants to put something in the iPhone, it needs to be able to make hundreds of millions of it. If there’s a new cutting-edge screen technology that seems promising (microLED or electroluminescent quantum dots (EL-QD) or folding screens or whatever), it may not be possible to make enough of them to meet demand.
But a competitor that only ships a million phones may be able to pull it off.
From the outside, it may look like the bigger player is behind, but they’re constrained in what they can do by their own scale. Scale compounds both constraints AND advantages.
I’ve been keeping an eye on how OpenAI may be a victim of this dynamic too.
So far, they’ve been excellent at figuring out ways to stay on the cutting edge despite their scale, and I can’t think of much that a smaller player has been able to do that they can’t.
For a while, they limited reasoning models (o1, o3) to paid users, but after DeepSeek R1, they found a way to make it work for its 800m free users (with GPT-5’s model router). Midjourney has long offered great image generation for its relatively small paid user base, but OpenAI has found a way to provide a cutting-edge image gen model to free users (paid users have higher limits, but there are so many free users that their combined usage is likely higher while generating no direct revenue).
After the first version of Sora kind of disappeared from the zeitgeist and got passed by other models like Veo 3, I thought that maybe video was going to be OpenAI’s Achilles’ heel, both because they were trying to compete with the owners of YouTube (all that juicy training data) and because they were already saturating their inference capacity with just text and images… but somehow, some way, they appear to be pulling it off with Sora 2, scaling rapidly and giving even free users a relatively generous amount of videos per day.
OpenAI execs have often said that they are constrained by compute, and could release more products and models if they had more of it, but compared to the competition, it hasn’t stopped them from staying on the cutting-edge so far.
We’ll see if/when that changes 🤔
🗣️ Interview: Dylan Patel of SemiAnalysis on the ‘Trillion-Dollar AI Buildout’ 🏗️🏗️🏗️🚧👷🔌⚡︎🏭👨🏭
I really enjoyed this interview of friend-of-the-show Dylan Patel (💚 🥃) by Patrick O’Shaughnessy (🍀).
Here are a few highlights. First, on scaling laws:
one could think of it as diminishing returns, because if you go from $50 billion of spend to $500 billion of spend and only move up one tier of model capabilities, in absence of major algorithmic improvements, that’s a problem. I’m holding those improvements off to the side for now. But that iterative performance improvement in the model-it’s like a 6-year-old versus a 13- year-old. The amount of work you can get a 13-year-old to do is actually quite valuable relative to a 6-year-old. The same applies to a college intern versus someone who graduated and has even one year of work experience. While it may be an order of magnitude more compute, the amount of value is dramatically different. [...]
if you had unlimited high schoolers that refreshed so they didn’t build knowledge-versus college students versus 25- to 30-year- olds-the value of the business you can build, even though incrementally it’s just five years between each, is a drastic value change.
On the rapidly falling cost per unit of intelligence:
the cost to serve a model quality of GPT-3 is like 2,000 times cheaper now. And GPT-4, same thing. People freaked out about DeepSeek because it was 500–600 times cheaper. GPT-OSS came out and that’s even cheaper than that for roughly the same quality.
Actually, I would argue the GPT open-source model is a little better than GPT-4 OG because it can do tool calling. Anyways, the cost of these things tanks rapidly with algorithmic improvement—not necessarily models getting bigger. [...]
OpenAI had this tremendous problem with GPT-4. GPT-4 Turbo was smaller than 4, and 4o was smaller than 4 Turbo.
What OpenAI basically did was make the model as small as possible while keeping roughly the same quality or slightly better. So 4 to 4 Turbo was less than half the size. And from GPT-4 Turbo to 4o, the cost of 4o was way lower. They just kept shrinking the cost.
On the choice of not scaling up GPT-5 and leaning more on reasoning and RL:
So as OpenAI, what’s your choice? Do you go from 4o to 5 and make the model way bigger but not be able to serve anyone? And because you can’t serve anyone, and it’s slow, adoption doesn’t really get going. Or do you make the model the same size, which is what they did for GPT-5?
It’s basically the same size as 4o and roughly the same cost—maybe a little cheaper. Then you serve way more users and get everyone further up the adoption curve. Instead of putting them on a bigger model, you put them on models that do thinking.
This is the funny thing about people who think GPT-5 proves that scaling doesn’t work anymore: GPT-5 isn’t really bigger, unlike GPT-4.5, which was bigger and better in some ways, but it was not a reasoning model, so it couldn’t compete with o1 and o3 on many types of queries, and was too slow and expensive to be deployed widely.
As GPUs get faster and have more memory, much larger models will become more practical and will feel fast to users. I can’t wait to see what a truly bigger model (much larger than the original GPT-4) that has all the modern algo improvements, reasoning, and RL improvements can do 🤔
On building the power for all this:
The first approximation is that it’s not that much power yet. Data centers are like 3–4% of U.S. power. Of that, two is regular data centers and two is AI data centers. So that’s nothing, dude. That’s literally nothing.
It’s just we haven’t built power in 40 years, or we’ve transitioned from coal to natural gas more and more over 40 years. Mostly we just don’t know how to. There are regulations, not enough labor, supply chain constraints forever.
Maybe the job of the future is to be a data center electrician 🤔
🤝 AMD is Paying OpenAI to be a Customer: 6 GW Compute + Equity Deal 🏗️🏗️🏗️🏗️
We’re in the part of the cycle where there isn’t a week without a mega deal between the various giants involved in the AI buildout. After massive deals involving Oracle and Nvidia, OpenAI is now partnering with AMD:
Under the terms of the deal, OpenAI committed to purchasing 6 gigawatts worth of AMD’s chips, starting with the MI450 chip next year. The ChatGPT maker will buy the chips either directly or through its cloud computing partners. AMD chief Lisa Su said in an interview Sunday that the deal would result in tens of billions of dollars in new revenue for the chip company over the next half-decade.
The devil’s in the details: We can see who had the leverage in this negotiation, and it wasn’t AMD.
When Nvidia and OpenAI made a deal, Nvidia got OpenAI equity.
Here, it’s OpenAI that is getting 160 million warrants with a $0.01 exercise price. This is potentially 10% of the company!
If we look at AMD’s 8k:
the first tranche of shares vesting after the delivery of the initial one (1) gigawatt of AMD Instinct MI450 Series GPU products and full vesting for the 160 million shares contingent upon Warrantholder, its affiliates or Authorized Purchasers purchasing six (6) gigawatts of AMD Instinct GPU products. Vesting of Warrant Shares are further subject to achievement of specified Company stock price targets that escalate to $600 per share for the final tranche and stock performance thresholds. Additionally, each tranche of vested Warrant Shares is subject to the fulfillment of certain other technical and commercial conditions prior to exercise.
From OpenAI’s side, those penny-strike warrants behave like a contingent, back-end rebate paid in AMD stock. Or in other words, if the AMD GPUs were full price, OpenAI probably would have preferred to stick with Nvidia, but at what is functionally a large discount, hey, why not, we need all the compute we can get!
Matt Levine put it best:
How do those negotiations go? Like, schematically:
OpenAI: We would like six gigawatts worth of your chips to do inference.
AMD: Terrific. That will be $78 billion. How would you like to pay?
OpenAI: Well, we were thinking that we would announce the deal, and that would add $78 billion to the value of your company, which should cover it.
AMD: …
OpenAI: …
AMD: No I’m pretty sure you have to pay for the chips.
OpenAI: Why?
AMD: I dunno, just seems wrong not to.
OpenAI: Okay. Why don’t we pay you cash for the value of the chips, and you give us back stock, and when we announce the deal the stock will go up and we’ll get our $78 billion back.
AMD: Yeah I guess that works though I feel like we should get some of the value?
OpenAI: Okay you can have half. You give us stock worth like $35 billion and you keep the rest.Of course, the warrants are contingent on various milestones, so they’re not exactly free money. If they end up being exercised, it means AMD is doing well as OpenAI is getting part of its compute expenses “refunded” in equity.
Jensen had this to say when asked to comment on the deal:
“It’s imaginative, it’s unique and surprising, considering they were so excited about their next generation product,” Huang said. “I’m surprised that they would give away 10% of the company before they even built it. And so anyhow, it’s clever, I guess.”“Clever, I guess” 🙃
It signals that AMD is in a weak position, and if you’re considering a big order from them, maybe you should try not to pay full price. It makes me wonder if it wouldn’t have been better for AMD to offer OpenAI a secret discount instead of that equity, but it’s possible that Sam Altman really wanted the equity to capture more of the potential upside.
So what will OpenAI do with these chips?
It looks like the answer is inference, which Nvidia must be happy about, because it’s in training that the CUDA moat is strongest.
OpenAI is probably also looking to use this dual-sourcing to secure better terms from Nvidia.
The biggest questions that remain are: How will OpenAI pay for all this, and where is the power going to come from for all those gigawatts of compute?
As for Nvidia, if the warrants are exercised, it’ll be an investor in AMD AND Intel 😎
Things are getting stranger.
📜✉️ 60 Years of Warren Buffett Letters in One Tome
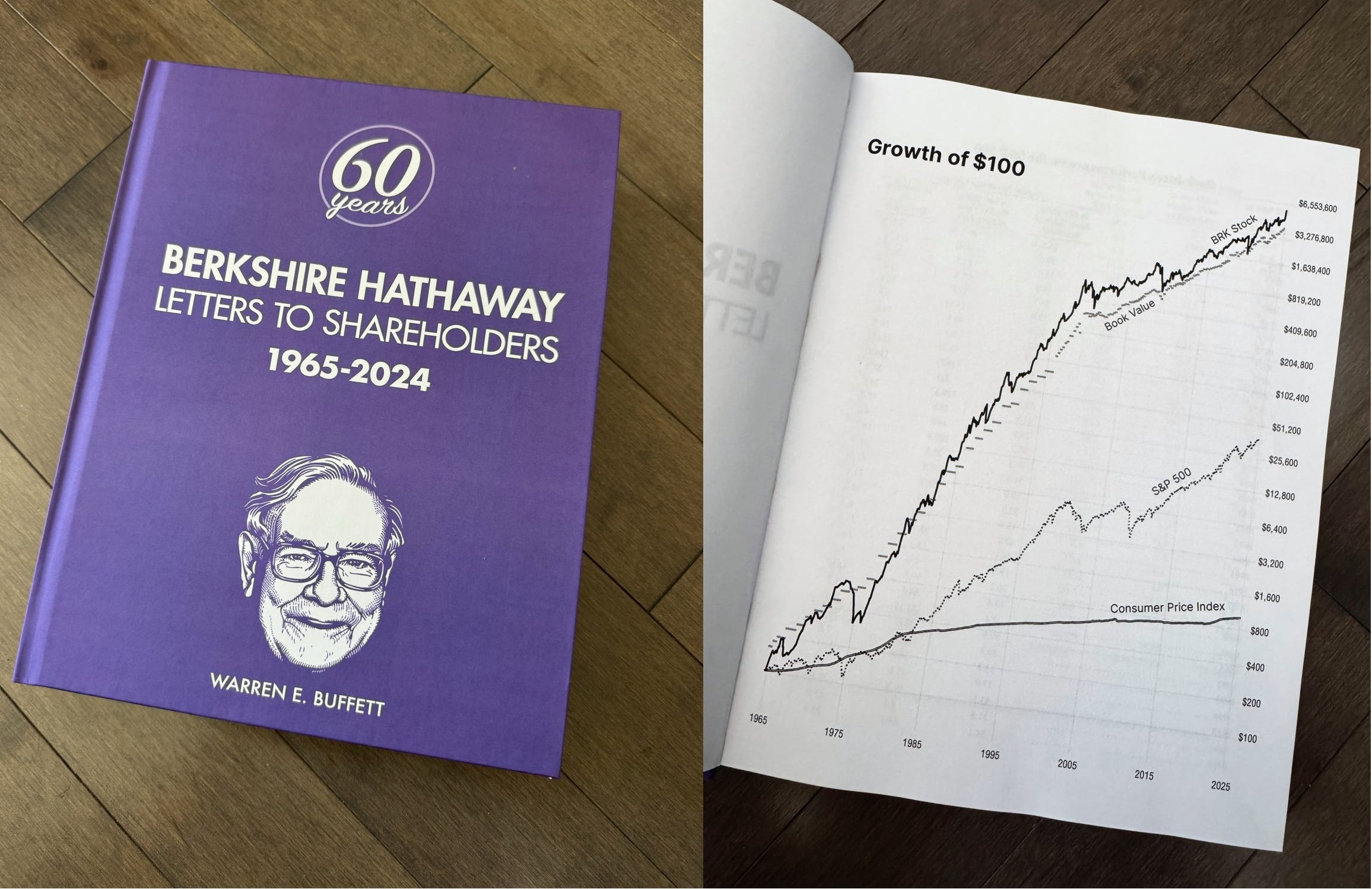
Friend-of-the-show and supporter Max Olson (💚 🥃) did a great job curating this. I love having it as a reference, opening it up to random pages to refresh my memory.
In fact, reading Buffett is probably the most counter-cyclical thing you can do in this market! 😅
🧪🔬 Science & Technology 🧬 🔭
🦅🇺🇸 U.S. Defense Flaws: ‘Silicon Shield is Fake, Drones + Future of War’ 🛡️
War is hell, and to best avoid it, we should take its possibility seriously and deter it through (real) strength (not posturing and bluster). The worst thing is to bury our head in the sand and hope for the best.
This podcast covers a lot of interesting geopolitical and strategic aspects of the current world chessboard.
Here are highlights, but I recommend the whole thing:
Unaddressed drone vulnerability: The US lacks serious defensive planning against covert drone strikes on critical infrastructure (shipyards, natural gas facilities, airports), despite Ukraine and Israel demonstrating these capabilities against Russian and Iranian strategic assets.
Counter-drone seen as tactical, not strategic: Treated as battlefield tools rather than homeland defense priorities, with no “coastal artillery” equivalent to protect American industrial capacity from determined adversaries. The traditional assumption that two oceans protect America is obsolete.
Critical vulnerabilities still ignored: The US has failed to address known weaknesses for decades: GPS dependency (executive order from 2000), critical mineral reliance on China (15+ years of warnings), and telecommunications breaches (Salt Typhoon).
Cyber overhyped, sabotage underestimated: While cyber warfare dominates discussions, physical sabotage (already occurring between Russia and EU) represents an equally serious threat that can’t be discussed without triggering “red scare” overreactions.
Silicon Shield is a flawed strategy: Basing Taiwan deterrence on semiconductor interdependence is “tier 4 or 5” deterrence. Economic entanglement has never prevented war throughout history (Peloponnesian Wars to WWI). The Silicon Shield is fundamentally a self-hostage situation (“Nobody move or I’ll shoot myself”). Efforts to educate Wall Street about war costs backfired by encouraging investment de-risking without policy changes to improve deterrence.
TSMC not irreplaceable (but expensive): Despite industry claims of quick replication, rebuilding TSMC capacity would realistically require 10 years and half a trillion dollars, including supply chains and expertise—not just facilities. US policy simultaneously treats TSMC as indispensable while forcing domestic production and restricting Chinese students in tech, undermining both Silicon Shield logic and talent acquisition.
🧠💭💪 Gaining Muscle Strength from Imagining Training

Here’s a wild one that sounds like pseudoscience, but apparently isn’t.
Researchers took 30 volunteers and split them into groups: One spent 15 minutes a day just *imagining* flexing their pinky finger. Another *mentally* practiced elbow curls. A control group did nothing (perfect for the lazy like me!). Then a fourth group actually did the physical exercises.
This went on for 12 weeks.
The pinky group? Their finger strength increased 35% without ever training that finger.
The elbow group? 13.5% stronger. Again, zero actual exercise.
The physical training group hit 53%, so imagination doesn’t beat reality. But 35% from pure thought is pretty, pretty good.
EEG measurements showed the mental training was literally rewiring their brains. The cortical signals controlling those muscles got stronger—the brain was learning to activate dormant motor units more efficiently.
Some implications of this:
For rehab patients who can’t move certain muscles yet, they could start “training” before they’re cleared for physical therapy.
For athletes dealing with injuries, they could maintain neural pathways while immobilized.
For anyone, you and me, it’s a reminder that strength isn’t just about muscle mass, it’s about your brain’s ability to tell those muscles what to do 🧠
I found a few other studies that seem to replicate this effect, with varying levels of benefits, so at least it’s not one of those non-replicating studies.
🐜🔬 TSMC is Bringing 2nm to Arizona, Upscaling Demo Fabs 🇺🇸
DigiTimes reports:
Industry insiders say the Arizona P2 fab, initially intended for 3nm technology, will now incorporate 2nm capabilities — a node originally scheduled for the later-stage P3 plant. Mass production at P2 could begin as early as late 2027, significantly closing the gap with TSMC’s most advanced fabs in Taiwan.
According to equipment suppliers, TSMC has publicly committed to allocating 30% of its sub-2nm total production capacity to its US facilities. To meet this target, the company is undergoing a sweeping overhaul of its global fab planning and capacity allocation.
That’s very interesting because Taiwan’s government has been trying to keep leading-edge stuff in Taiwan. I’m not sure what has changed things here. Possible rising demand from AI, meaning that they’ll want even more 2nm capacity in 2027 than they originally planned for 🤔
More details:
The P1 plant — which will enter mass production by the end of 2024 — has upgraded from 5nm to 4nm. Meanwhile, fabs P2 through P6, initially designed with demonstration-scale capacity, are being recalibrated to full-scale production.
The P2 fab, built on the foundation laid by P1, has accelerated its construction timeline. In addition to its 3nm capabilities, it will now be equipped for 2nm production — ahead of schedule by about six months.
Tool installation is expected before the end of 2026, with volume production slated for late 2027.
👻 Andrej Karpathy on Building Ghosts vs Animals 🐦⬛
Karpathy wrote some thoughts about the recent Richard Sutton-Dwarkesh Patel interview, and this part stood out to me:
So that brings us to where we are. Stated plainly, today’s frontier LLM research is not about building animals. It is about summoning ghosts. You can think of ghosts as a fundamentally different kind of point in the space of possible intelligences. They are muddled by humanity. Thoroughly engineered by it. They are these imperfect replicas, a kind of statistical distillation of humanity’s documents with some sprinkle on top.
They are not platonically bitter lesson pilled, but they are perhaps “practically” bitter lesson pilled, at least compared to a lot of what came before. It seems possibly to me that over time, we can further finetune our ghosts more and more in the direction of animals; That it’s not so much a fundamental incompatibility but a matter of initialization in the intelligence space.
But it’s also quite possible that they diverge even further and end up permanently different, un-animal-like, but still incredibly helpful and properly world-altering. It’s possible that ghosts:animals :: planes:birds.
For context, check out the Sutton interview here, and Dwarkesh also wrote his thoughts post-interviews.
🎨 🎭 The Arts & History 👩🎨 🎥

💰👮♂️⚾ ‘The Town’ (2010) 🏦💸
My wife and I rewatched it. I don’t think we had seen it since it came out, but I remember really liking it at the time.
It has aged well. Still a great film!
It was my first time seeing the extended cut, and now I’m not sure which scenes I’d forgotten vs which are new.
Making a good heist movie is hard. There’s so much we’ve already seen, it’s hard not to fall into cliché. But I like the approach here, focusing on details and few clever tradecraft tricks that we may not have seen elsewhere + always keeping characters at the center of things, even during action scenes.
Renner was fantastic, probably the film’s highlight performance. Jon Hamm was also fun to watch, but maybe a little bit too one-note and trying a little too hard to be Vincent Hanna at times. But that’s a nitpick, it doesn’t really detract from the film.
I think this would work today as a prestige HBO-miniseries (6-8 episodes maybe). I wish we could’ve spent an hour on each of the robberies (planning, execution, etc), and maybe have a flashback episode on how these guys first started out in this life. It all goes by a little quickly in the film, IMO.
If you’ve never seen it, or haven’t seen it in years, I recommend it, it holds up 👍 👍
The poster for the movie reminded mi of this great ad https://www.youtube.com/watch?v=4JJyXryevxY . i saw it like 50 times
thanks for writing this! I enjoyed reading this!