

602: Nvidia vs Google TPU/ASICs, Nvidia Q3, Nano Banana Pro, Google + Meta, Anthropic’s Magnum Opus, France's Forgotten Role in the Depression, and Project Hail Mary
"you have to do a lot of other things right to compete"

To quiet a crowd or a drunk, just whisper.
—Kevin Kelly
🇺🇸🙏🦃🍗🥧🌾🌽Happy Thanksgiving to my American friends!
For me, this is the week when the internet goes quiet and I can do more deep work.
But I hope you enjoy the food and time with your families (don’t talk about politics, nothing good can come of it!).
I’ve got a couple of suggestions for you to bring some AI goodness to those who may not be following the tech closely:
Use Google’s Nano Banana Pro image generator, available in Gemini, to ‘imagine’ what some of the younger family members might look like when they’re older. I did this with my kids, and we haven’t laughed this hard in ages. I was gasping for air, it was great.
Here’s what Nano Banana Pro thinks my 7-year-old will look like at 25:

Put ChatGPT in advanced voice mode and turn on the video feed. Ask it to describe the room, the people, suggest recipe improvements or outfit tweaks, interior design, etc. Tangible things that everyone can see. The video element is still magic to normies, and it’s fun. You can also ask it to mimic regional accents or English-as-a-second-language accents or speak in various languages, that’s usually a crowd pleaser too.
🛀💭📸🍌 Speaking of Google’s new image model, I came up with a tagline for it:
Nano Banana Pro: Plausible-Deniability-as-a-Service.
🦾🪞📖🦋✍️🏆 Quick reminder: You have until December 1st to enter the giveaway for a signed copy of ‘White Mirror’.
All the details, plus the podcast I did with the author and editor of the book, are here:
It’s aimed at people who haven’t read the book yet, and we dig into a bunch of ideas I think you’ll really enjoy.
🔎📫💚 🥃 Exploration-as-a-service: your next favorite thing is out there, you just haven’t found it yet!
If this newsletter adds something to your week, consider becoming a paid supporter 👇
🏦 💰 Business & Investing 💳 💴
🐜🔬🕵️ Nvidia vs Google TPU/ASICs: What the Market May Be Missing 🤖 ☁️☁️☁️
We’re in the part of the cycle where the market turns skeptical on Nvidia and sells off the stock. 🔄
Far be it from me to make market calls. Nobody knows the future 🔮 especially when things are changing as fast as they are in this industry, and there are that many variables…
But it seems to me like Mr. Market may be misreading the situation a bit.
Most of the recent developments seem very POSITIVE for Nvidia, or at least, that’s my reading of them.
Google Gemini 3 Pro made big waves by… showing that pre-training and post-training scaling laws still hold. This suggests that demand for compute will remain robust for the foreseeable future.
In fact, in a recent presentation to Google Cloud employees, a VP said:
At an all-hands meeting on Nov. 6, Amin Vahdat, a vice president at Google Cloud, gave a presentation, titled “AI Infrastructure,” which included a slide on “AI compute demand.” The slide said, “Now we must double every 6 months.... the next 1000x in 4-5 years.”
Double every 6 months! And not from a small base! 🤯
The better Google does, the more pressure there is on everyone else to keep up. This means more demand for GPUs, networking gear, giant coherent training clusters, etc.
If energy is the bottleneck, at least in the West, then whoever can provide the most tokens/watt will be advantaged. In pretty much every category, that’s Nvidia.
What ultimately matters to those who build AI infrastructure is ROIC, not how much a GPU rack costs. They must take into account the expected economic output of the equipment over its whole life, and more versatile GPUs tend to have an advantage over more specialized ASICs. It recently came out that even older Ampere and Hoppers were still mostly fully utilized. It helps that Nvidia keeps updating and optimizing CUDA for older generations too, making them more efficient than they were the day people bought them.
The software investments required to do that make sense for Nvidia because they have such a large installed base, and every product was designed from the ground up to run on the same CUDA. It’s doubtful that most ASICs will get this long-tail support and optimization, as the smaller installed base gives lower leverage to these software efforts, making it harder to justify.
It’s true that recent developments, such as Google apparently being in talks to make a deal with Meta for TPUs, and hosting more third-party workloads on TPUs, mean that Nvidia has incrementally more competition and the distribution of future outcomes is wider.
BUT
They’ve had fierce competitors for a long time (TPUs have been around for a decade, AMD has been doing good work for a while, lots of large players have had ASIC programs for years). Nvidia has beaten them because they started investing in the space years before everyone else, with more focus, then executed really well, and they move really fast, so they are extremely hard to catch up with. They’ve never won ‘by default’ because there was no competition.
I expect that they will have a smaller slice of the pie over time, but the pie is growing very fast and is very large. 🥧
Most ASIC/custom-silicon programs will likely fail. And the chips are just one piece of the puzzle, you have to do a lot of other things right to compete. 🧩
You need the whole stack to be cutting-edge. Otherwise, even if you have good chips, you can be bottlenecked elsewhere (networking, software, difficulty getting coherence for training clusters, etc). Speed of execution is also important: If an ASIC program runs into problems and gets delayed by a couple of quarters, any benefits over Nvidia’s hardware may evaporate.
This matters if you’re a giant company trying to invest tens of billions in infrastructure that is crucial to your competitive position against other giants. You know Nvidia can deliver a ton of chips, networking gear, racks, software, and that it’ll all integrate well together. If you rely on someone else and they can’t handle the scale, what seemed like a bargain may become expensive.

So Mr. Market has sold down NVDA to around 24x forward P/E, close to a 17% drawdown from peak as I’m writing this (intraday), just as Nvidia's quarterly results (more on that below) positively surprised most observers despite already high expectations. For a company growing this fast, with good visibility into growth for the next couple of years, with Visa-like net margins, that feels a bit overly pessimistic.
Not that it’s a surprise, sentiment and animal spirits bounce around, that’s what they do in a market. A few months ago, the market was skeptical of Google, and now they’re the anointed one. Microsoft was the AI winner that could do no wrong for a while, and now they’re falling behind… Same for Meta and Amazon, going from hero to zero over the cycles.
We haven’t even seen models fully trained on Blackwell yet 🤔
The OpenAI and Anthropic models that make all those headlines are Hopper-based. I think that when these come out, if scaling laws hold the way Gemini 3 seems to show, it may start a whole new investment frenzy.
And by then, Vera Rubin will be starting to ship, and Nvidia will probably pull a few more rabbits out of its hat, possibly including systems that are more specialized in one part of the AI pipeline, similarly to the Rubin CPX that was announced a few months ago…
I wouldn’t be surprised if, over time, they added more SKUs and had systems that were highly tuned just for certain kinds of inference, or certain steps of pre or post-training/RL. They won’t stand still in the face of the ASIC threat.
🩻🔍 Nvidia Q3 Highlights: Surpassing High Expectations🔥
Despite the recent stock price drop, actual Q3 results were pretty mind-blowing:
Revenue: +22% sequentially (!!) and 62% year-on-year, at that scale
Data center revenue: +25% sequentially and +66% year-on-year (🤯)
Gaming revenue: +30% YoY, but it doesn’t really matter anymore because it’s just $4.3bn while data center is $51.2 billion 🎮👾
Even the networking business is now twice as big as gaming, and growing much faster: +162% year-over-year, generating $8.2 billion
Mellanox was such a great acquisition, easily one of the all-time greats 🥇
Gross margins holding pretty well, down 120bps from a year ago to 73.4%, but Blackwell is a very complex architecture and still ramping, so all things considered, that seems pretty good to me
EBITDA margin: 64.5% (this is Visa-level 💳 but for a physical product)
Net income margin: 56% (this is actually higher than Visa…)
“This past quarter, we announced AI factory and infrastructure projects amounting to an aggregate of 5 million GPUs.”
GB300 is now 2/3 of Blackwell revenue (Grace-Blackwell Ultra is faster, has more memory, and produces more FLOPs/watt than GB200. Also higher price tag.)
If we zoom out a bit:
“Nvidia’s free cash flow has mushroomed from $3.8 billion in the year to January 2023 to an estimated $96.5 billion in the year ending this coming January… That revenue growth represents a compound annual growth rate of 194%” 💰
The danger when you’re doing this well is that there’s only one way to go, and it’s down (losing market share, margins being pressured, etc). But that’s also what everyone has been saying about Google for a long time, so it’s sometimes possible to keep finding new heights for a long time.
And at the end of the day, shareholders should care about per share owner’s earnings/free cash flow, not margins or market share.
Here are a few of my highlights from the call 👇
On “content per gigawatt”, aka how much of the capex spent on a gigawatt does Nvidia typically capture, Jensen had this to say:
Q: we have heard numbers as low as $25 billion per gigawatt of content to as high as $30 billion or $40 billion per gigawatt. So I’m curious what power and what dollar per gig assumptions you are making
Jensen: In each generation, from Ampere to Hopper, from Hopper to Blackwell, Blackwell to Rubin, our part of the data center increases.
And Hopper generation was probably something along the lines of 20-some-odd, 20 to 25. Blackwell generation, Grace Blackwell particularly is probably 30 to 30 to say, 30 plus or minus and then Rubin is probably higher than that.
And in each one of these generations, the speed up is X factors. And therefore, their TCO, the customer TCO, improves by X factors, and the most important thing is, in the end, you still only have 1 gigawatt of power.
On the importance of power-efficiency in an energy-constrained world:
Jensen: One gigawatt data centers, 1 gigawatt power. And therefore, performance per watt, the efficiency of your architecture is incredibly important.
Your performance per watt translates directly absolutely directly to your revenues, which is the reason why choosing the right architecture matters so much now. The world doesn’t have an excess of anything to squander.
And so each generation, our economic contribution will be greater. Our value delivered will be greater but the most important thing is our energy efficiency per watt is going to be extraordinary, every single generation. [...]
so at this point, I’m very confident that NVIDIA’s architecture is the best performance per TCO, it is the best performance per watt. And therefore, for any amount of energy that is delivered, our architecture will drive the most revenues.
Gavin Baker wrote about how the more power constraints we face, the better for Nvidia vs ASICs:
Power shortages could be great for Blackwell. When watts are the bottleneck, tokens per watt will drive decision making as tokens literally = revenue.
GPU vs. ASIC pricing will matter much less in a power constrained world.
This fact combined with Google selling the TPU externally likely means that almost all other ASIC programs will be cancelled. Even if an ASIC can reduce the cost of a 1 gigawatt datacenter from $50b to $40b, the ROI on that $40b will be lower because the revenue (tokens) produced by that datacenter will be significantly lower.On the longevity of older GPU generations, and how we should think about useful life:
Jensen: The long useful life of NVIDIA’s CUDA GPUs is a significant TCO advantage over accelerators. CUDA’s compatibility in our massive installed base, extend the life NVIDIA Systems well beyond their original estimated useful life. For more than 2 decades, we have optimized the CUDA ecosystem, improving existing workloads, accelerating new ones and increasing throughput with every software release.
Most accelerators without CUDA and NVIDIA’s time-tested and versatile architecture became obsolete within a few years as model technologies evolve.
Thanks to CUDA, the A100 GPUs we shipped 6 years ago are still running at full utilization today, powered by vastly improved software stack.
At the same time, Nvidia’s annual cadence is designed to obsolete those older chips. They’re trying to have their cake (long useful lives) and eat it too (relentless upgrade pressure).
Gavin Baker recently wrote this:
The fact that Hopper rental prices have increased since Blackwell became broadly available suggests that GPU residual values might need to be extended beyond 6 years.
Even A100s are still generating really high variable cash margins today. If these trends continue, expect GPU financing costs to drop another 100-200 bps. As an aside a 1-2 year useful life for GPUs is just not possible given the physical realities of a datacenter.On the $500bn of orders slide from GTC, he said it could even be more:
Jensen: So we shipped $50 billion this quarter, but we would be not finished if we didn’t say that we’ll probably be taking more orders. For example, just even today, our announcements with KSA, and that agreement in itself is 400,000 to 600,000 more GPUs over 3 years. Anthropic is also net new. So there’s definitely an opportunity for us to have more on top of the $500 billion that we announced.
Crazy numbers!
What other company is talking about half a trillion dollars of orders of physical product over a couple of years, at 50%+ net margins?!
Real-world ROI example:
Jensen: Meta’s GEM, a foundation model for ad recommendations trained on large-scale GPU clusters exemplifies this shift. In Q2, Meta reported over a 5% increase in ad conversions on Instagram and 3% gain on Facebook feed driven by generative AI-based GEM. Transitioning to generative AI represents substantial revenue gains for hyperscalers.
This is massive!
At Meta’s billions-of-users scale, improving ad conversion by even fractions of percentage points delivers large absolute profits. 3-5% increases are gigantic, and will keep paying dividends in the future, and may even become more profitable as optimizations either make serving the same ad targeting cheaper over time, or they simply reinvest the compute into improving targeting further.
Here’s Gavin on early signs that ROIC on all this AI capex is, so far, pretty good:
As of the third quarter, the ROIC of the hyperscalers remains higher than it was *before* they ramped their capex on GPUs. This is the most accurate way to quantitatively measure the “ROI on AI” as it also captures the immense revenue benefits that Google and Meta have seen from moving their recommendation and advertising systems to GPUs from CPUs.
It is possible that we have an “ROIC” air pocket over the next two quarters as capex ramps sharply for Blackwell and there is definitionally no initial ROI on this spend as the Blackwells are used for training. Obviously the only “ROI on AI” comes from inference.What happens to compute demand when AI starts making breakthroughs in biotech or when robotics hits the mainstream?
☁️🤝☁️ Google May Sell TPUs to Meta 🤔
Everybody’s talking to Google these days, the new golden child:
Meta, the parent company of Facebook and Instagram, is currently in talks with Google about spending billions of dollars to use TPUs in Meta’s data centers in 2027, as well as to rent Google chips from Google Cloud next year
Meta competes with Google in the ad market, but not in the cloud hyperscaling business, so this odd-bedfellows pairing makes some sense.
Meta has the scale to optimize their models for TPUs and would benefit from having one more source of compute and some negotiating leverage with Nvidia.
From Google’s point of view, considering how much internal compute demand they have, I don’t know if selling TPUs to external customers gets them a higher ROIC than just using them internally to further optimize ad targeting and serve their products. It’s hard to know the trade-offs without knowing how much supply of TPUs they expect to have in the coming years ¯\_(ツ)_/¯
For Meta, I’m not sure how much cheaper TPUs would be than Nvidia’s GPUs, though, as Google will assuredly want a nice margin too. TPUs are cheaper for Google than for any third party to which they may sell them because the stack is largely internally developed and optimized for their specific use cases.
Note: Some people think TPUs are just Broadcom chips, but over time, Google’s internal silicon team has developed a lot of the IP, and Broadcom’s share of the IP has decreased relative to Google’s own contribution. 🐜👨🔬
As Ben Thompson (💚 🥃🎩) points out, most other potential Google TPU customers are direct competitors to GCP (AWS, Azure, Oracle), so they may be more reluctant to fund their competitor and become dependent on them.
But Nvidia is also a harsh mistress, allocating GPUs to neoclouds and trying to divide and conquer to keep competition high among its customers, so it’s not like there’s no downside there either.
I suspect that over time, all the big players will spread their bets and have some ASICs, some AMD GPUs, maybe some TPUs… and a whole crapload of Nvidia for the foreseeable future.
🇫🇷📉 France and the Gold Standard’s Role in the Great Depression 🥖
Ok, first, the bit about keeping the country secret made me smile. It was a well-executed gag.
But also, I like to think that I know a fair amount about that period of history, and I had never heard of this, so I figure that you may find this bit of history interesting too.
🧪🔬 Science & Technology 🧬 🔭
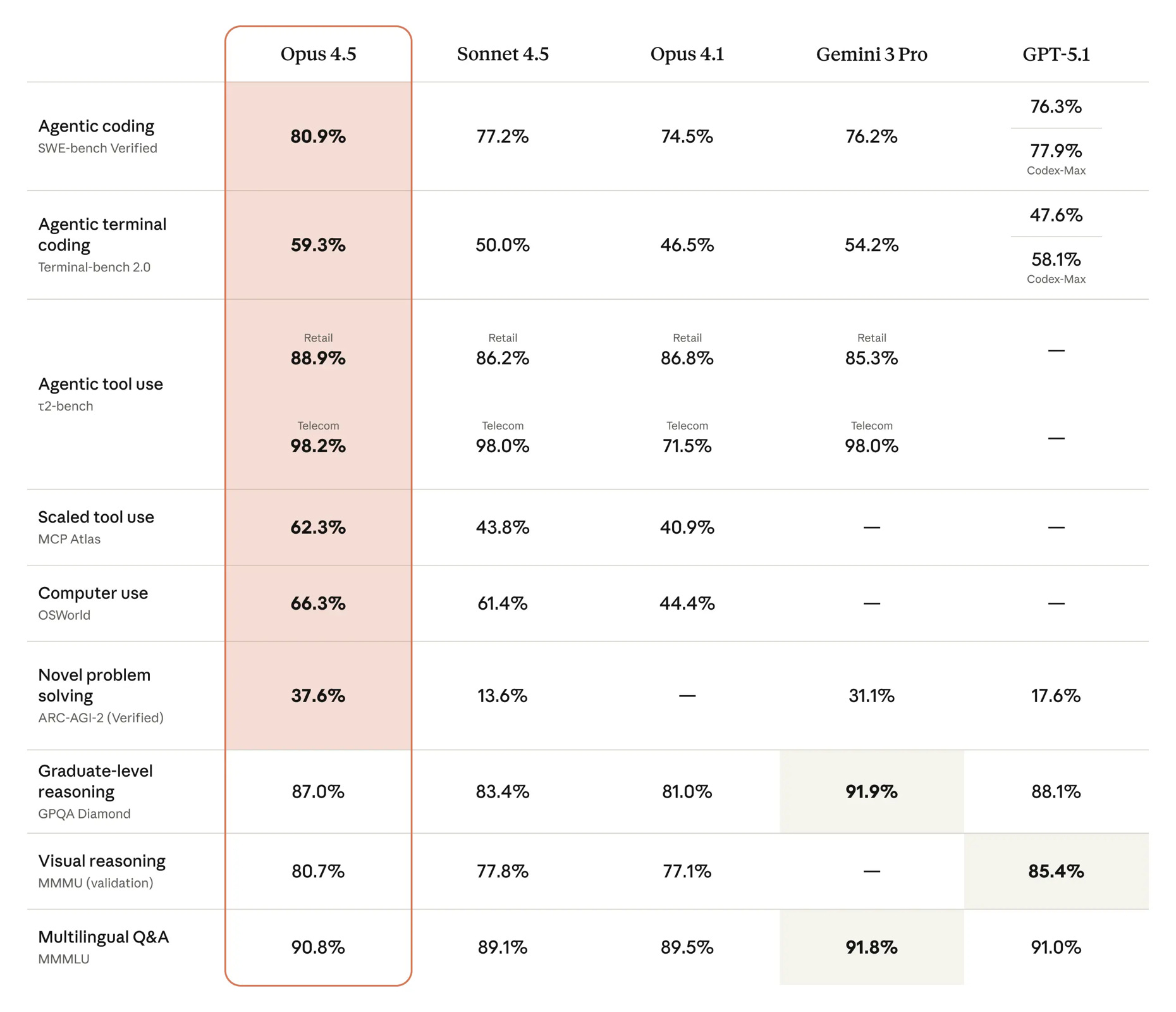
🤖🎓 Anthropic’s Magnum Opus (4.5) + Why Smarter Models Use Fewer Tokens 📊🗜️
I gotta say, as much as I like Gemini 3 Pro so far, Opus 4.5 has given me more “feel the AGI” moments. I don’t mean that it’s AGI, just that it feels more genuinely intelligent than models I’ve interacted with. I can’t quite put my finger on it… I’ll ask a question, and the answer will exceed my expectations in how well-written, well-structured, and nuanced it is.
There’s also a new feature that I like and hope everyone else will adopt:
For Claude app users, long conversations no longer hit a wall—Claude automatically summarizes earlier context as needed, so you can keep the chat going
You can still scroll up and see what you wrote, that doesn’t get compacted. But to fit in the model’s context window, the conversation will get “compressed/summarized” for the model once in a while.
What’s particularly notable about Opus 4.5, other than how smart it is, is the pricing and token efficiency.
$5/million for input and $25/million for output. This is a lot cheaper than the previous Opus at $15/$75 and keeps it a little more competitive with the GPT-5.1 family ($1.25/$10) and Gemini 3 Pro ($2/$12, or $4/$18 for >200,000 tokens). For comparison, Sonnet 4.5 is $3/$15 and Haiku 4.5 is $1/$5.66% cheaper than Opus 4.1 while being smarter!
How can they do this?
I’m guessing a mix of some algorithmic optimizations + Blackwell GPUs coming online for inference 🤔
They’ve also improved usage limits:
For Claude and Claude Code users with access to Opus 4.5, we’ve removed Opus-specific caps. For Max and Team Premium users, we’ve increased overall usage limits, meaning you’ll have roughly the same number of Opus tokens as you previously had with Sonnet.
This means you can have longer sessions without running into limits or having the AI start to forget things.
And if we’re comparing it to other models, we can’t just look at the price per token, we also have to consider the token efficiency of the model.
This is where Opus 4.5 shines: It does better than Sonnet 4.5 on the SWE-Bench coding benchmark while using between 1/4 and 1/2 the number of tokens. This means that Opus 4.5 can be both better AND cheaper than Sonnet 4.5, at least for some use cases.
One way to think about token efficiency is that the model can pack more intelligence into each token, or convey the same information or solve the same problem using fewer tokens.
How does it do that?
Better planning and fewer false starts. A more capable model is more likely to identify the right approach on the first attempt. Less capable models might start down one path, realize it’s wrong, backtrack, and try again.
More information per token through better word choice. A smarter model tends to select words that are more precise and information-dense for the context.
Knowing what to omit. Perhaps counterintuitively, a big part of efficiency is knowing what not to say.
Reduced redundancy. Weaker models sometimes repeat themselves or restate points in slightly different ways. Stronger models tend to state something once, clearly, and move on.
Something that we should aspire to as humans 🤔
🍌 Google’s Nano Banana Pro: It’s bananas! 🖼️ 🎨
I mentioned this one in the intro, but it deserves a full section because it’s extremely impressive.
It’s not just good at following image prompts, there’s clearly a lot of non-visual smarts in there, too. People had it create “whiteboard” summaries of long presentations or solve difficult exam problems visually.
It’s much better than previous models at handling text and keeping things coherent.
My fave recent meme has been these guys in various situations.

I like that the API version can generate images up to 4k resolution. Pricing is fairly high for now (around $0.24 per 4K image and ~$0.13 for 1K/2K) but I expect it to come down over time.
You can see an example of a higher-res image by Simon Willison here.
All images made with it are embedded with Google’s “imperceptible SynthID digital watermark.” You can upload any image to Gemini and ask it if it was generated by AI, and it’ll look for the watermark. I hope others will adopt it to help create a bit more transparency about what was AI-generated and what wasn’t.
Sophisticated actors will likely bypass it, but it’ll be better than nothing for the vast majority of cases (I’ve already seen people get caught on Twitter posting photos that they claimed were real but had the invisible watermark).
🎨 🎭 The Arts & History 👩🎨 🎥
👨🚀 Read ‘Project Hail Mary’ Before the Film Drops 🚀🪨☀️🐜
Now’s the time to read the book, if you haven’t already. Do it before the film comes out, then we can both watch it, and I’ll likely do a podcast about both the book and film.
We’re all looking for more shared culture, this can be one of those for us!
I’m hoping the film will be good, and so far the trailer gives me some hope that it will be, but the book is so much fun… and the audiobook even more so!
The audiobook narrator, Ray Porter, is the 🐐 and because part of the book has to do with sound, so they’ve created very unique things in the audiobook.
I sincerely recommend that if there’s ANY chance that you’ll read the book or listen to it, don’t even watch the trailer 🙈 as it will spoil many things.
Go into it cold. It’ll be so much better that way!
Just wanted to say I loved reading Project Hail Mary, and would strongly recommend the Martian if you haven’t gotten to it yet