603: Gemini vs Claude vs GPT, Code Red, Mark Chen on OpenAI’s Plan, Sundar Interview, TPU Pressure & Nvidia Equity Discounts, Trainium 3, Creatine, and James Cameron
"introspection about that notoriously brutal shoot"
Nothing in life is to be feared, it is only to be understood. Now is the time to understand more, so that we may fear less.
—Marie Curie
🤖🤖🤖🔍🕵️ So many good AI models have come out lately, it’s an embarrassment of riches.
The best way to compare them? Send my real-world queries to multiple models. I’ve been triple-wielding Opus 4.5, Gemini 3 Pro, and GPT-5.1 Thinking, to figure out which one I prefer.
This allows me to get a better feel for each model’s ‘flavor’ and how they perform with my specific use cases, rather than relying on benchmarks that may not reflect what I do. Benchmarks are also likely being gamed because the incentives are so overwhelming to rank at the top 🥇🥈🥉
Remember Goodhart’s Law: When a measure becomes a target, it ceases to be a good measure.
Even knowing this, it’s hard not to be swayed by the halo effect 😇 of great benchmark scores and model hype, especially since there’s plenty of subjectivity involved in deciding which model you prefer.
Your favorite model is as much about taste and workflow fit as raw IQ.
I’ll admit that going in, I expected Gemini 3 Pro to become my new default model, and maybe Opus 4.5 to follow closely behind as GPT-5.1 would get left in the dust by a new crop of state-of-the-art models.
I was surprised by how often I preferred GPT-5.1’s answers!
I really didn’t expect it.
As long as I keep it in Thinking mode, the quality of answers is consistently very strong. I often enable the ‘Extended Thinking’ toggle on the web, but strangely, there’s still no manual toggle in the apps.
Maybe the model isn’t quite as smart as Gemini 3 Pro or Opus 4.5, but it behaves like a better and more diligent worker. It structures responses well, finds and cites useful sources with links, gives progressive disclosure of details (summary + details), and offers ideas for where to go next to dig deeper.
It’ll often find angles or highlight potential issues to watch out for that the other models don’t even mention, and it seems to use ‘memory’ more effectively than others, referencing past conversations and taking into account my stated preferences.
Don’t get me wrong, Gemini 3 Pro and Opus 4.5 are *extremely strong*, sometimes surprising me with a level of nuance or good writing that I haven’t seen from GPT-5.1. But after countless A/Bs, I consistently return to GPT-5.1 Thinking ¯\_(ツ)_/¯
This is likely a testament to OpenAI’s product abilities.
After all, the model is extremely important, but it’s only part of the equation.
What shapes the final outcome is the integration of many other ingredients: UX, UI, system prompts, reinforcement learning for tool use, tweaking reasoning parameters to know when to spend more tokens, and the massive signal from user feedback, including all those thumbs up and down on conversations and in-app A/B tests 👍👎
It could be how they’ve been able to get such good performance from a model that is likely built on top of a smaller pre-training run than Gemini and Claude Opus.
Let me leave you with one piece of advice:
👉 If you use ChatGPT, set it to Thinking mode by default 👈
You can do that in a dropdown menu at the top 👆
OpenAI wants you to leave it in “auto” mode because it saves them compute, but you want max intelligence, right? When you default to thinking, you can still manually override it by hitting “skip”, so that’s always an option when you’re in a hurry.
The quality of answers in reasoning mode is SO MUCH HIGHER, it’s almost always worth waiting a bit longer. You’ll also get far fewer hallucinations.
🦾🪞📖🦋✍️📬 I’ll be contacting the book giveaway winners shortly.
Congrats, and enjoy your signed copy of ‘White Mirror’!
🔎📫💚 🥃 Exploration-as-a-service: your next favorite thing is out there, you just haven’t found it yet!
If this newsletter adds something to your week, consider becoming a paid supporter 👇
Liberty’s Highlights is 100% reader-supported, 0% algorithm-driven. It CAN’T exist without your support. 💚 🥃🚂 🦊🐙⚓️
🏦 💰 Liberty Capital 💳 💴
🚨 Code Red: Mark Chen on OpenAI’s Plan to Strike Back Against Google 🧄🔬👨🔬
This is my favorite interview this week 🥇
Chen is such a pleasure to listen to because he isn’t afraid to explain his reasoning and give details, even if he keeps some cards close to the vest. And Vance does a good job steering the interview to interesting places, digging deeper whenever he hits a rich vein.
Here are my highlights. First, on Gemini 3:
Yeah, so to speak to Gemini 3 specifically, it’s a pretty good model. And I think one thing we do is try to build consensus. The benchmarks only tell you so much. And just looking purely at the benchmarks, we actually felt quite confident. We have models internally that perform at the level of Gemini 3, and we’re pretty confident that we will release them soon and we can release successor models that are even better. [...]
One thing that, kind of reading into the details, that I’ve noticed is, you know, when you look at stuff like their SWE bench numbers, there’s still a big thing around data efficiency that they haven’t cracked, right? They haven’t made that much movement on it. And I think we have very strong algorithms there.
Thanks to a timely scoop from The Information, we might know exactly what “internal model” Chen is talking about.
OpenAI is reportedly developing a new model codenamed ‘Garlic’ (🧄) to counter Google (does that imply that Gemini is a vampire? 🧛♂️). It’s apparently performing well against Gemini 3 and Opus 4.5 in coding and reasoning tasks.
This comes as there’s a reported Code Red 🚨 at OpenAI. Garlic seems to be the immediate response, potentially released as GPT-5.2 or GPT-5.5 early in 2026.
But Google and Anthropic are not static targets, so we’ll see what they bring to the table by then…
The technical details are interesting: Garlic reportedly incorporates pre-training advances from another internal model (codenamed: Shallotpeat) to achieve better data efficiency. The goal? Infusing a smaller model with the same density of knowledge that previously required a massive model (like the now-disappeared Orion aka GPT-4.5 🪦).
Pre-training Is Back, Baby, And Scaling Isn’t Dead:
A lot of people say scaling is dead. We don’t think so at all. In some sense, all the focus on RL, I think it’s a little bit of an alpha for us because we think there’s so much room left in pre-training.
Chen reveals that OpenAI has been rebuilding its pre-training muscle 💪 after focusing heavily on reasoning, and they see lots of room left to run.
“Soup diplomacy” in the Meta–OpenAI talent war:
some interesting stories here are Zuck actually went and hand-delivered soup to people that he was trying to recruit from us. Just to show how far he would... Yeah, I think he hand-cooked the soup. And, you know, it was shocking to me at the time, but, you know, over time...
I’ve kind of updated where these things can be effective in their own way, right? And, you know, I’ve also delivered soup to people that we’ve been recruiting from Meta.
Tit-for-tat!
Who makes the best soup? 🍜🍲
The “Do You Really Need More GPUs?” Question Baffles Him:
When people ask me, like, do you guys really need all this compute? It’s such a shocking question, because day to day, I’m dealing with so many compute requests.
And really, my frame of mind is, if we had 3x the compute today, I could immediately utilize that very effectively. If we had 10x the compute today, probably within a small number of weeks, fully utilize that productively.
And so I think the demand for compute is really there. I don’t see any slowdown.
Compute demand still seems insatiable.
AI Has Different Intuitions Than Humans, And That’s Where the Magic Is:
Chen notes that AI models find different problems easy or hard than humans do.
We typically think of these machines as they’re very good at pattern recognition. You can take any problem, if it maps to a previous problem, it’s probably going to be able to solve it.
But what I’ve noticed is in some of the previous IOIs, this problem like message is very ad hoc. I didn’t think the models would solve it at all, but actually one of the easier problems for the AI. So yeah, I mean, this is giving me the sense that AIs plus humans in frontier research, it’s gonna do something amazing just because the AI has a different intuition for what’s easy and what’s not.
This isn’t just pattern-matching, it suggests AI + human collaboration could unlock genuinely new approaches to research 👨🔬🤝🤖
The Measurement Problem: How Do You Benchmark Superhuman Performance? 🏆
But there is this kind of interesting problem now of how do you go beyond what humans are able to do today? And I do find a serious measurement problem there too.
Even in the sense of like, can humans judge superhuman performance in the sciences, right? How would we know that this superhuman mathematician is better than that superhuman mathematician?
And we really do need to kind of come up with better evaluations for what it means to make progress in this world, right? We’ve been lucky up to this point, right? There have been contests like the IMO, IOI really just like giving who’s the top one mathematician in the world, right? But when the model capabilities go beyond humans, there are no more tests.
Chen articulates a *genuinely hard problem* that doesn’t get enough attention: once AI exceeds human capability, how do we even know which system is better? How do we know what to reward and steer towards?
Is it just going to be AIs grading the work of AIs because humans can’t see the difference anymore? 🤔
🗣️🔍☁️ Sundar Pichai on Google’s Full-Stack War Plan
On the other side of the battlefield, we have a solid interview with Pichai.
He’s not always the most riveting interview subject, but here he’s comfortable. I’d even say he exudes confidence. He opens up about his strategy and gives us a real glimpse into how Google views itself and the competitive landscape.
Google’s TPU Pressure: Nvidia Equity ‘Discounts’ and the Vera Rubin Counterpunch 🥊
I mostly agree with the big picture that credible TPUv7 alternatives give labs real leverage over Nvidia. But two specific claims deserve a closer look and some clarifications.
Here’s the context for the first. They write:
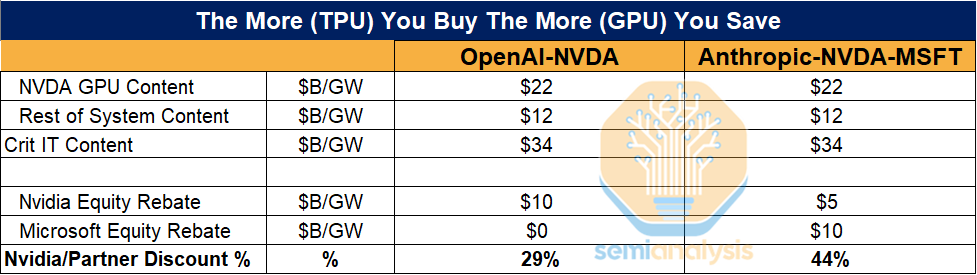
We think a more realistic explanation is that Nvidia aims to protect its dominant position at the foundation labs by offering equity investment rather than cutting prices, which would lower Gross margins and cause widespread investor panic. Below, we outline the OpenAI and Anthropic arrangements to show how frontier labs can lower GPU TCO by buying, or threatening to buy TPUs.
OpenAI hasn’t even deployed TPUs yet and they’ve already saved ~30% on their entire lab wide NVIDIA fleet. This demonstrates how the perf per TCO advantage of TPUs is so strong that you already get the gains from adopting TPUs even before turning one on.
The logic: rather than cut prices on its GPUs, which would lower its profit margins and make Wall Street freak out, Jensen counters the TPU threat by offering equity investments to labs that are talking to Google. SemiAnalysis treats these as “implicit discounts.”
In the table above, they calculate that OpenAI is getting a ‘29% discount’ if you take into account the first $10bn that Nvidia is investing in them, and Anthropic is getting a ‘44% discount’ because of the $15bn investment that Nvidia and Microsoft recently made.
First, even if you accept the logic, I don’t see why Microsoft’s investment should count toward an Nvidia ‘discount’ or relate to the TPU threat. To me, it seems about diversifying their AI exposure away from OpenAI and getting some large workloads to come to Azure.
But I’m not sure if I agree with calling this a discount in the first place, equating it to price cuts on GPUs. It’s an interesting metaphor, but imperfect.
Nvidia isn’t just handing out 30–40% off coupons. It’s more like the flour supplier buying a stake in the bakery so the baker can afford more flour. The baker’s flour feels cheaper, but the supplier now owns part of the bakery. 👨🍳🥐
If Nvidia were just handing cash to OpenAI and Anthropic to keep them as customers, that would be different. But they’re getting equity in return. While the equity’s value is uncertain, other investors are willing to pay similar valuations and there’s a real chance it’s worth at least what Nvidia paid, potentially more.
In fact, the investment acts as a self-catalyst, increasing the equity’s value by derisking its counterparties, both directly and indirectly, by signalling to other sources of capital that they have deep-pocketed backers. If there’s one thing we know about institutional investors and large sovereign wealth funds, it’s that they love to follow each other and pile on.
So yes, Google is putting competitive pressure on Nvidia, and Nvidia is working hard to keep its largest customers from diversifying away. But treating these equity deals as literal 30–40% GPU discounts stretches the metaphor past its useful range.
SemiAnalysis may not have intended this literally, but I’ve seen enough people take it that way that it’s worth clarifying.
The next part of the article has gotten less attention, but it’s worth highlighting:
While Ironwood is a proper competitor to Blackwell, Nvidia once again hits back with Vera Rubin. Vera Rubin will deliver huge performance uplifts across compute, memory and network with TPU v8 seeing much smaller improvements [...]
the gen-on-gen TPUv8 performance uplifts are much milder relative to what Nvidia plans achieve with Rubin in terms of both compute and memory. For external customers the TCO per effective FLOP advantage remains, but it is much narrower than Ironwood compared to Blackwell. [...]
Nvidia initially had a much less aggressive target for Rubin, but they upped the power from 1800W to 2300W in order to improve FLOPS and the HBM speed from 13TB/s to 20TB/s. This was largely because of Nvidia’s paranoia and competitive pressure from AMD and Google. Nvidia is sprinting as fast as possible at the speed of light.
If Nvidia’s aggressive last minute FLOPS and memory bandwidth increases work out, Google’s TPU goes from competitive externally to uncompetitive with the TPUv8, because they were so tepid on design choices. [...]
Google is ceding huge TCO advantages away to Rubin. We may end up in a world where Rubin in the Kyber rack is competitive or better TCO than Google’s TPUv8 even for many of Google’s internal workloads
TPUv7 might end up being the highest delta vs Nvidia we see for a while, unless Google really over-delivers on TPUv8 . But either way, this is a multi-round arms race, and Nvidia clearly isn’t standing still.
I think that for massive amounts of compute and AI R&D to move to TPU (outside of Google), it would need to be competitive or ahead of Nvidia for a longer period. This is especially true for other hyperscalers, considering they compete directly with GCP and will be hesitant to rely on Google to supply them with something so critical.
☁️🐜 Amazon Unveils Trainium 3 ASICs 🤖
While we’re on the topic of GPUs and TPUs, here’s what AWS announced yesterday at re:Invent 2025:
AWS Trainium3—AWS’s first 3 nm AI chip—are purpose-built to deliver the best token economics for next-generation agentic, reasoning, and video generation applications. Trn3 UltraServers deliver up to 4.4× higher performance, 3.9× higher memory bandwidth, and over 4× better energy efficiency compared to Trn2 UltraServers […]
Each AWS Trainium3 chip provides 2.52 petaflops (PFLOPs) of FP8 compute, increases the memory capacity by 1.5x and bandwidth by 1.7x over Trainium2 to 144 GB of HBM3e memory, and 4.9 TB/s of memory bandwidth […]
On Amazon Bedrock, Trainium3 is the fastest accelerator, delivering up to 3× faster performance than Trainium2 and 3× better power efficiency than any other accelerator on the service.
This all sounds good on paper, but I’m looking forward to how they do in real-world use. That’s the hard part!
AWS has also announced that for Trainium 4:
AWS will support NVIDIA NVLink Fusion — a platform for custom AI infrastructure — for deploying its custom-designed silicon, including next-generation Trainium4 chips for inference and agentic AI model training, Graviton CPUs for a broad range of workloads and the Nitro System virtualization infrastructure. [...]
AWS is designing Trainium4 to integrate with NVLink and NVIDIA MGX, the first of a multigenerational collaboration between NVIDIA and AWS for NVLink Fusion.
AWS is hedging its bets. It wants to compete with Nvidia, but it’s integrating with its interconnects to make migration easier. 🤔
🧪🔬 Liberty Labs 🧬 🔭
💪🧠💊 Your Reminder to Take Creatine
I’ve covered the creatine beat a fair amount over the years, so instead of rehashing the basics, here’s a good video on the newer evidence for creatine, and for upping your daily dose to around 10 grams.
☁️↔☁️ Fierce Competitors AWS and Google Cloud… Partner on Multi-Cloud Networking?!
The #1 and #3 hyperscalers just announced a partnership to simplify networking between their clouds, letting customers move workloads and data more easily.
Previously, to connect cloud service providers, customers had to manually set up complex networking components including physical connections and equipment; this approach required lengthy lead times and coordinating with multiple internal and external teams. This could take weeks or even months. [...]
By integrating AWS with Google Cloud’s Cross-Cloud Network architecture, we are abstracting the complexity of physical connectivity, network addressing, and routing policies. Customers no longer need to wait weeks for circuit provisioning: they can now provision dedicated bandwidth on demand and establish connectivity in minutes through their preferred cloud console or API.
The process went from DIY over weeks to a supported API that works in minutes. That’s a massive improvement.
If this works well, at maturity, it could almost allow engineers to treat another cloud as “just another region”.
From a strategy perspective, if multi-cloud is inevitable, then make your cloud the easiest on-ramp to everyone else’s toys. By defining the API, they control the standard and can lure customers away from competitors who don’t join.
This is how Cloudflare is counter-positioning itself, charging no egress fees and trying to get users to move data to R2 to more easily multi-cloud. I wonder if this new alliance weakens Cloudflare’s pitch? 🤔
Crucially, as far as I know, egress and data-transfer pricing still apply. No one is promising free bandwidth here. The clouds will still make high-margin revenue on data transfer, but the architectural friction will be drastically lower.
From the users’ point of view, all I see is upside. It removes a pain they already had, and it makes it easier to create best-of-breed stacks that use different parts of different clouds.
AWS mentioned that Azure would be joining the Interconnect standard later in 2026. If that’s correct and Microsoft joins, I suspect that everyone else will join (Oracle, the neoclouds).
My friend MBI (🇺🇸🇧🇩) argues convincingly that by making Google’s TPUs more easily accessible to AWS customers (the largest cloud customer base), both companies retain customers within their ecosystems while collectively expanding the viability of non-Nvidia hardware. That strengthens the hyperscalers’ negotiating position and contributes to long-term compute diversification.
🇺🇸👩🔬💾 Genesis Mission: U.S. Opens National Lab Data for AI Research
We don’t have many details on implementation yet, but a new plan will open 17 national labs’ data to AI labs:
An executive order issued on 24 November instructs the US Department of Energy (DoE) to create a platform through which academic researchers and AI firms can create powerful AI models using the government’s scientific data. [...]
The scale and timeline of the plan is ambitious. In 60 days, the DoE is expected to create a list of 20 potential science and technology challenges for the project to tackle, in areas of national priorities such as nuclear fusion, quantum information science and crucial materials.
The agency is supposed to create a full inventory of available federal computing resources and identify initial data assets to use, then work out how to safely include external data sets. The administration expects to demonstrate the platform’s capability for one of these research challenges in nine months.
This is a potential goldmine ⛏️
Access to massive, high-quality datasets not in Common Crawl could give American labs a significant advantage. It should also improve scientific reasoning capabilities, accelerating progress via autonomous ‘lab researcher’ agents.
This direct collaboration may also spark new ideas and research directions.
The new Genesis Mission is meant to provide “secure access to appropriate datasets, including proprietary, federally curated, and open scientific datasets, in addition to synthetic data generated through DOE computing resources”, according to the executive order.
The Department of Energy has created a fancy website for it, but the real test will be execution: can DoE actually deliver clean, usable datasets at scale, and keep them secure from spies? 🕵️
🎨 🎭 Liberty Studio 👩🎨 🎥
🎬🍿 James Cameron’s Guided Tour of His Own Films 🎞️
There’s something special about hearing Cameron autopsy his own films and walk through what he was trying to do on each project. He’s as analytical about his films as he is technical about his shoots.
During the Abyss segment, Cameron shows real introspection about that notoriously brutal shoot, acknowledging the toll it took on the cast and crew. The origin story of Titanic is surprisingly random: Cameron basically wanted an excuse to dive to the wreck. It’s a reminder that cultural phenomena often emerge from personal obsessions, not calculated plans 🚢
This whole thing made me want to rewatch multiple films 😅
(I can’t wait for my boys to be old enough to watch Aliens and T2)
Happy New Year, quite interesting on the comparision between the three models, do you have an easy way to compare the three models, something like the multiplicity.ai for the best models? Best Drew




Happy New Year, quite interesting on the comparision between the three models, do you have an easy way to compare the three models, something like the multiplicity.ai for the best models? Best Drew
Thank you.