

611: The Escher Hands Era, Trust Paradox, AI Coding, Software Biz, Dylan Patel, Sleep Deprivation's Cruelest Trick, 500 Open Source Flaws, and Jonathan Tepper's Memoirs
"I didn’t pick the name ‘Liberty’ randomly."

After the primary necessities of food and raiment, freedom is the first and strongest want of human nature.
—John Stuart Mill [raiment = clothing, btw]

🗓️🌐📰🤔 I’m back. A handful of unrelated things overlapped to make me publish less often than usual lately. I want to unpack it for you, because there’s some important context in there.
First, the less dramatic stuff: I’ve been traveling, both with my family and for OSV projects.
🏝️📖⛱️👫 I went to the Dominican Republic for the first time and spent most of the week reading on the beach and hanging out with my wife and kids (more on the books later).
It was 30+ Celsius/86+ Fahrenheit every day, while back home in Canada it was -30 Celsius/-22 Fahrenheit. Quite the delta! 🥵🌡️🥶
📕✍️📝 I also traveled for a writers’ room to help with someone else’s book. It was fantastic. I can’t wait to tell you more about it, because I think you’ll really like it. But for now 🤐
So that’s the travel part.
🎧🗣️🗣️🎙️✂️💬 I also spent much longer than I expected working on the Trillion Dollar Club podcast with MBI.
The raw audio was almost 3 hours long, and I spent 8+ hours doing hundreds and hundreds of edits to make it flow and sound as good as possible. I could’ve published the raw files with minimal edits, but what can I say, when it comes to podcasts, I’m more Beatles than Neil Young ¯\_(ツ)_/¯
I hope you enjoyed it. If you haven’t listened yet, consider this your reminder to check it out!
🗽⛓️💥⚖️🕊️ The other thing that blocked me from writing more is the stuff going on right now. I don’t even need to be specific, you know what’s going on.
One of my goals for this steamboat is to stay positive (that’s just my personality), and another is to never BS you. 🚢⚓
But in recent weeks, it has felt off to publish a regular edition about various cool things while incredibly consequential events are playing out. I didn’t pick the name ‘Liberty’ randomly. I’m a HUGE believer in hard-won freedoms like freedom of speech, the rule of law, due process, habeas corpus, the right to a fair trial, privacy, property rights, the presumption of innocence, free and fair elections, and the broader idea that power needs to justify itself to the individual, not the other way around.
This list 👆 isn’t exhaustive, and it doesn’t need to be because I think people should have all rights except those specifically constrained for clear, justifiable reasons, not only the rights that happen to be written down somewhere.
A lot of us try to avoid regular politics because it’s a colosseum hosting a pointless fight designed to generate strong emotions, tribalism, and kill critical thinking 📺💢
We’ve all seen it. People who would probably otherwise be smart say completely idiotic things because they were one-shotted by politics. Twitter has revealed this phenomenon and destroyed so many reputations.
BUT
There's another level: What system do we live in? What society do we want for our kids?
That’s what is being attacked right now. Maybe it’s Politics with a capital P, but it’s *not* the usual circus 🎪
I think many people’s political instincts, which are useful in normal times, are misfiring here. People who normally avoid politics (like me) are staying silent and treating this like one more episode of the same old ugly show. But it’s not. The instinct to stay out of it IS the instinct they’re counting on. If freedom-loving people look away and take our historically-very-rare freedoms for granted, we may find out the hard way how valuable what we had was.
It’s always much harder to regain lost freedoms than to preserve them. In the long arc of history, reversion to the mean = more tyranny, not less. It takes energy to fight that freedom-entropy.
To be clear: I don’t want to be writing about this. But silence is also sending a message, and I don’t want you to think that silence = tacit acceptance. I want to fly the flag for the freedoms we inherited from our ancestors. The ones people died for. 🪦📜🪶
🔎📫💚 🥃 Exploration-as-a-service: your next favorite thing is out there, you just haven’t found it yet!
If this newsletter adds something to your week, consider becoming a paid supporter 👇
🏦 💰 Business & Investing 💳 💴
🔮 Welcome to the Escher Hands Era 🔄
When I first got interested in artificial intelligence about 20 years ago, one of the sci-fi-sounding predictions was that we would someday, in the faaaar future, hit a point when AI would become good enough that it would start working on improving itself, creating a recursive self-improvement loop.
In other words, v1.0 helps build v1.1, which helps create v1.2, and so on.
Humans working on a problem don't get much smarter over time. But with AI, the tool itself is improving. Each version of the AI is smarter than the last and helps build the next one. So the rate of progress accelerates. Even if the difficulty of the problems scales up quickly too, you're still moving faster than if only humans were at it.
Recent reports from OpenAI, Anthropic, and DeepMind make it clear that we’ve crossed a new threshold.
AI tools have long been useful to AI researchers, but at the frontier, top coders were still very much writing code and deep in the weeds of the details. In fact, when Dario Amodei said this in March 2025 (feels like a lifetime ago):
“I think we will be there in three to six months, where AI is writing 90% of the code. And then, in 12 months, we may be in a world where AI is writing essentially all of the code.”
The reaction at the time was very skeptical. Oh, Dario, come on, not that fast. Stop the hype, you’re only saying that because you’re raising money…
But the release of Opus 4.5 was a milestone for AI coding, and the pace has been accelerating ever since. The recent releases of Opus 4.6 and, mere minutes later, GPT-Codex-5.3 have unleashed a tsunami of comments from coders about how good these models now are. A large number of very strong coders have publicly admitted that they don’t really write code anymore, they just act as PMs for the models.
Many sources at OpenAI and Anthropic have also publicly said that most AI researchers are now letting the models write the code. Boris Cherny, the creator of Claude Code, said that new versions are mostly built by the AI itself.
In the technical documentation of Codex 5.3, OpenAI wrote:
GPT-5.3-Codex is our first model that was instrumental in creating itself. The Codex team used early versions to debug its own training, manage its own deployment, and diagnose test results and evaluations.On his personal blog, Dario recently wrote:
AI is now writing much of the code at Anthropic, it is already substantially accelerating the rate of our progress in building the next generation of AI systems. This feedback loop is gathering steam month by month, and may be only 1–2 years away from a point where the current generation of AI autonomously builds the next.Escher hands all the way down…
🤝 The Trust Paradox ⬛ 🔍🤨
We've been living with black-box outputs for years. Nobody fully understands why a LLM gives the answers it does. But we at least understood a lot about the process that created it. Now the process itself is going dark. That's a different kind of not-knowing.
Soon both the LLM and the process that built it will be beyond the grasp of anyone.
Black box²
The opacity is compounding.
That makes it all the more important that we figure out better ways to see inside these things if we want to avoid bad surprises down the line.
Using AI to help us understand AI is the kind of leverage that makes sense as things get more complex… but it’s also the definition of the problem. How do you get comfortable trusting the tools if they were made by unreliable/unverifiable tools in the first place 😵💫
In Escher’s drawing, there’s no original hand. No hand that was drawn by something other than itself. That’s increasingly how these models are being built.
🗺️ Outside the Coding Beachhead 🛣️

Coding is perfectly ‘shaped’ for AI. There’s a lot of example code out there, it’s deterministic (it compiles or doesn’t), and the better AI gets at it, the more it can improve itself, becoming even better at it. Rinse and repeat.
But other sectors are seeing rapid progress.
Opus 4.6 improved on a variety of benchmarks in real-world finance, computational biology, cybersecurity, etc. It has gotten better at tool use, and new front ends like Claude Code and Cowork, as well as plugins for browsers, legal work, and apps like Excel and PowerPoint, are allowing it to colonize other fields.
One of the big improvements in Opus 4.6 vs 4.5 was that it is much better at retrieving information in long documents and handling long context windows. In the MRCR v2 benchmark with 256k and 1m tokens context, it got the needles in the haystack 93% and 76% of the time vs 10-18% for Sonnet 4.5 (which was state of the art a few months ago). This ability should make it much more reliable for paperwork-related tasks (finance, legal, HR, insurance, medical, etc).
Right now there’s high uncertainty about which sectors will be hit most. Which will be disrupted and which will use AI as a sustaining technology. At this point, it’s unknowable where exactly the chips will fall, but one thing is certain: This is a once-in-a-lifetime technological reshuffling of the deck.
📈 The Rise of Codex 🤖
For a while, OpenAI seemed focused on dominating the chatbot consumer market and let Anthropic play in the enterprise via its API. But Anthropic has executed so well — even Microsoft, OpenAI’s biggest backer, is reported to be on pace to spend over $500m/year on Anthropic’s AI — and increased ARR so fast that it clearly attracted OpenAI’s attention. Codex has been their response, and while at first it seemed doubtful that they would make much of a dent without the laser-like focus on coding that Anthropic has shown, it turned out that Codex is *surprisingly* good!
The graph below is just an indirect proxy on adoption, and Anthropic still no doubt dominates when it comes to sheer number of enterprise API tokens, but it’s an impressively fast counter-attack:
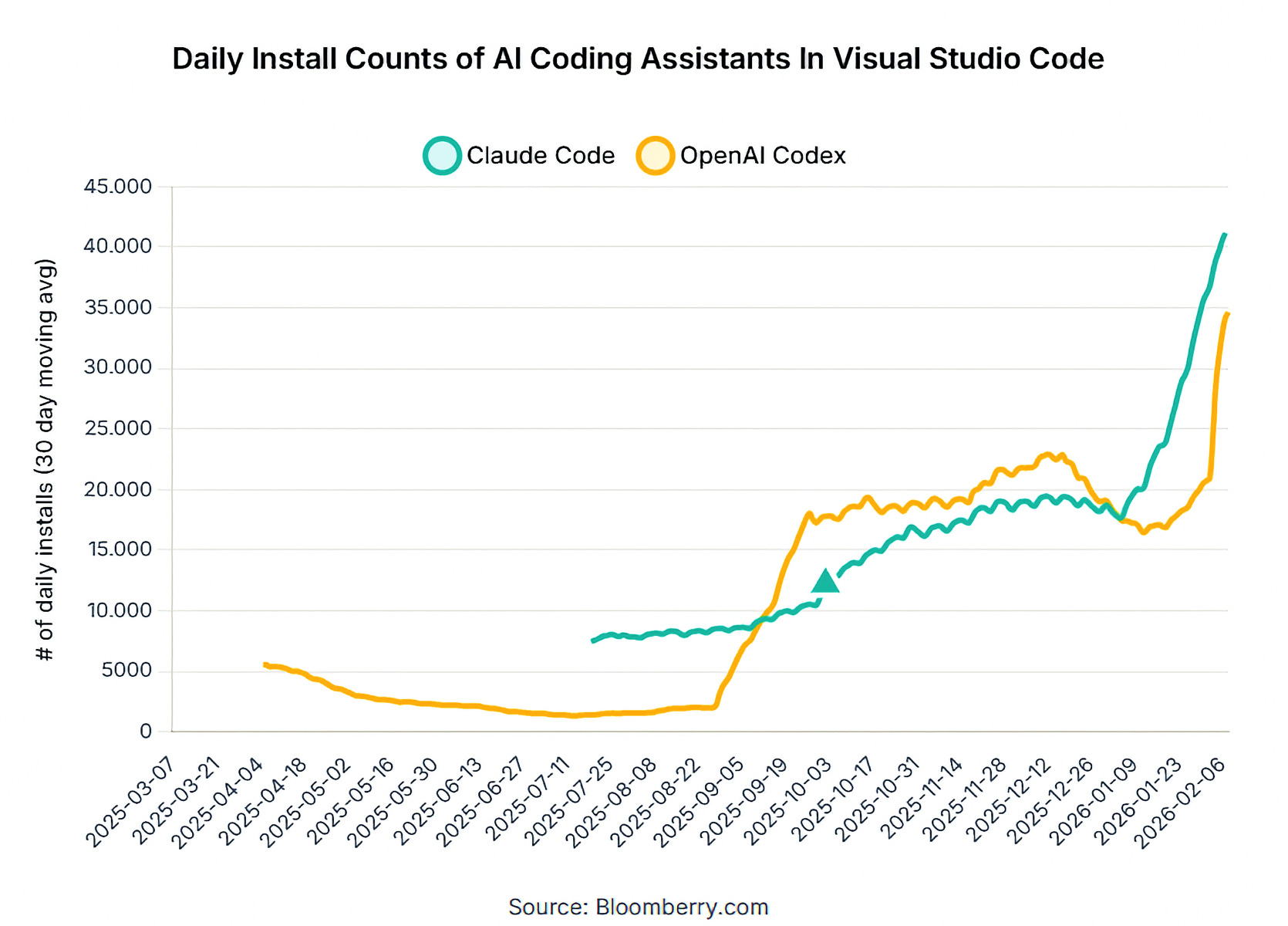
Purely anecdotally, I’m seeing more coders say that they find Codex-5.3 better than Opus 4.6. That it’s less fun to use, but it runs autonomously for longer and produces better code with fewer problems.
There were rumors that Anthropic was about to release Sonnet 5 (there are even conspiracy theories that Opus 4.6 actually is a renamed Sonnet 5, allowing Anthropic to charge higher API prices for it..). We’ll see if anyone can get a sustainable lead in coding or if they will stay neck-and-neck for a while.
💾 What is a Software Business? “Writing the code was never the hard part” 🤔
Interesting discussion between Benedict Evans and Ben Thompson about what software businesses actually do:
Benedict Evans: I never thought that the hard part of building a piece of software that manages the thing for the other thing in the thing deep inside a big company was writing the code.
Ben Thompson: Right. Completely agree.
Benedict Evans: That’s not the hard part. The hard part is working out that that problem exists and then working out the right way of solving it and then going out and building a go-to-market and working out how to get your customers to buy it. It’s the implementation, the execution, the route to market, the right way of solving the problem.
You remember this phrase that was going around a couple of years ago about thin GPT wrappers, well every one of those 400 apps is a thin SQL wrapper.
Ben Thompson: That’s right.
Benedict Evans: Those 400 SaaS apps, they’re all a thin SQL wrapper, they’re all just databases.
It’s like the dumb Hacker News comment, “Airbnb is just a CMS”. But yeah, every social network is just a CMS. Well, great, but Tinder, I mean, even that, Tinder and Hinge aren’t the same at all, and those really are just the same thing and they’re just a database with a social network on top.
Every piece of enterprise software is "just a database" the same way every restaurant is "just a kitchen." The value was never just in the ingredient, it's in knowing what to cook, for whom, and how to get them in the door.
This reminds me of what Mark Leonard said on his last (😢) conference call:
I believe that vertical market software is the distillation of a conversation between the vendor and the customer that has gone on frequently for a couple of decades. And you distill those work practices down into algorithms and software and data and reports and it captures so much about the business.The code is a manifestation of that accumulated knowledge of the customers, their workflows, pain points, weird edge cases, etc.
In some cases, customer intimacy doesn’t matter, and there’s not that much non-public domain knowledge to accumulate anyway. In others, sales cycle courtship can last years, and there’s a lot of tacit expertise behind every engineering and design decision.
How much “writing code” matters versus everything around the code probably varies more than either side of the AI debate wants to admit.
🗣️ Interview: Dylan Patel on Nvidia’s Groq Deal, AI Capex ‘Bubble?’, and China’s Semiconductor Industry 🏗️🐜🤖🇨🇳
I enjoyed this convo between Matt and friend-of-the-show Dylan Patel (💚 🥃).
Here are some of my highlights. First, how Jensen is making defensive/offensive bets like the Groq deal:
Dylan Patel: Nvidia takes the Andy Grove mentality more seriously than anyone else: “Only the paranoid survive” this is core to Nvidia. Jensen is very paranoid about losing. If he just kept making his mainline chip, point solutions for specific parts of the market would crush him on cost and performance. [...]
When you look across the market, only a few companies have successfully created a chip architecture and the software to run models accurately. Building a rack-scale solution and networking thousands of chips together is hard. Groq did it with not that many people.
I’m Nvidia I want to make four different chip architectures [...] and in addition my general purpose thing is actually not just a GPU chip, it’s GPU chips, CPU chips, networking chips, NV switch, NICs, like you know there’s many many chips and each of those chips has many chiplets.
You don’t have enough engineering resources, and so acquiring Groq, you get those resources to make more solutions for different parts of the market.
On how hard China is going at building its own home-grown semiconductor industry: 🐜🔬
Dylan Patel: The entire country [China] is “semiconductor-pilled.” There are romance dramas where people fall in love in a semiconductor fab or while researching solar cells. It’s considered super cool to be a semiconductor engineer. Compare that to the West where we have Love Island. We are so cooked.
[On China’s industrial strategy:] The specialization is absurd. There are entire cities in China that just specialize in lampshades, or microphone arms, or guitars. They are trying to replicate that hyper-specialization in semiconductors.
If you cut off globalism today, China has the most vertical stack in the world. They could still run their fabs because they’ve built the chemical supply chains. America could not build a fully vertical fab without parts from elsewhere. However, China is still about 10 years behind on lithography.
On why Nvidia is most scared of Huawei: 😱
Dylan Patel: Nvidia is deathly terrified of Huawei because Huawei caught up to Apple and actually surpassed them as TSMC’s biggest customer before they got banned. They crushed Nokia, Sony Ericsson, etc.—the entire telecom supply chain.
(Huawei was TSMC’s second-largest customer before the ban, I couldn’t find evidence they actually surpassed Apple as #1)
Huawei is the most vertical company in the world. No company is more verticalized than Huawei, which leads to huge innovations. It’s something that we don’t fully appreciate in the US, but when you travel in Europe, you see Honor phones completely destroyed them.
[…] Huawei is really cracked. And so, of course, they’re terrified.
His shorthand on each leading lab’s strength rang pretty true to me: 👨🔬
Dylan Patel: OpenAI has a better RL stack than Anthropic today. [But] their pre-trained models suck compared to Anthropic’s pre-training. If they catch up on pre-training and keep their better RL stack, they would have a much better model.
On the flip side, Google has a better pre-trained model than Anthropic or OpenAI, but their RL stack sucks. If they catch up on RL, these models are going to get ridiculous. Anthropic is advancing as well. [When] you look across the ecosystem, everyone’s advancing really fast.
Sounds like whoever gets better at the thing they are weaker at will win the next round 🏆
I find myself not using Gemini much because of both some weird behavior (which could be explained by weaker RL…?) and app-level papercuts.
For example, why is Gemini forgetting to cite source links so often? They’re literally the web search company! Why is the Gemini app and web interface so much worse than ChatGPT and even Claude? Why can’t it remember my choice of model in the picker and I have to manually select “Pro” every time?! Why is it worse at following my instructions? Why are so many parts of their app janky-feeling?
These days, I only use Gemini if I have a question about something visual (it’s much better with images) or very long text (huge context window and good retrieval). Otherwise, I pretty much use GPT-5.2-Thinking-Extended and Opus 4.6 Extended (increasing in the Claude Code and Codex desktop apps).
🏡🏠 Why Housing is Bad for Buyers AND Sellers 🏘️🏚️
I liked this video explaining some of the dynamics at play right now, especially in the U.S., where very long fixed-rate mortgages are the norm.
🧪🔬 Science & Technology 🧬 🔭
Sleep Deprivation’s Cruelest Trick: You’re Too Impaired to Notice You’re Impaired 🥱🧠
One of the strangest bugs in human OS is that the “how am I doing?” dashboard can break… while the needle is in the red, and you would need to know it most 📊
Most of us know what it feels like to be acutely tired. You pull one all-nighter (or get two nights in a row of awful sleep), and your brain feels like it’s moving through molasses. You can tell you’re impaired.
BUT
Chronic sleep deficit is sneakier.
A 2003 study took 48 healthy adults and randomly assigned them to get either 8, 6, or 4 hours of sleep per night for 14 consecutive days — or no sleep at all for 3 days straight. Everything was monitored in a controlled lab setting.
The results:
Chronic restriction of sleep periods to 4 h or 6 h per night over 14 consecutive days resulted in significant cumulative, dose-dependent deficits in cognitive performance on all tasks. Subjective sleepiness ratings showed an acute response to sleep restriction but only small further increases on subsequent days, and did not significantly differentiate the 6 h and 4 h conditions.
Here’s the part that should make you raise an eyebrow: by the end of 14 days, the people sleeping 6 hours a night were performing as badly as someone who hadn’t slept for two days straight.
But they didn’t feel like it.
Sleepiness ratings suggest that subjects were largely unaware of these increasing cognitive deficits, which may explain why the impact of chronic sleep restriction on waking cognitive functions is often assumed to be benign.
Your brain stops sending you the "I'm tired" signal, but the cognitive impairment keeps accumulating. It’s like a slow carbon monoxide leak: the damage accumulates while you feel nothing…
This is the trap.
Most people who chronically undersleep aren't walking around thinking "I'm severely impaired right now." They feel mostly fine. Maybe a little tired. And that's exactly the problem: the subjective feeling of being okay diverges from actual cognitive performance, and keeps diverging the longer the deprivation lasts. You're not fine. You just can't tell that you're not fine.
I think about this whenever I hear someone brag about only needing 5-6 hours of sleep. The data on genuine short sleepers (people with the genetic mutation who truly need less) suggests they’re extremely rare, way rarer than the number of people who claim to be one. My guess is that most people who “get by” on six hours have just acclimated to a state of impairment they can no longer perceive.
They’ve been driving with the parking brake on for so long, they forgot what it feels like without it.
Anthropic’s Opus 4.6 Found 500 Zero-Day Vulnerabilities in Open Source Code 💾 🔍🤖
Claude Opus 4.6 is still hot from the oven, and already Anthropic has pointed it at well-known open source projects to scan for bugs and flaws.
It found over 500 previously unknown, high-severity vulnerabilities in code that has been in wide use for years, accumulating millions of hours of CPU time. 😬
This is a genuine public good.
Open source code runs everywhere. EVERYWHERE!
Enterprise systems, critical infrastructure, your phone, your car. Most of these projects don't have dedicated security resources. AI-powered vulnerability discovery at scale is a massive force multiplier for defenders.
What makes this qualitatively different from traditional automated scanning is how the model works. It’s closer to how a human would review the code than traditional automated code review tools.
In one case, Claude read a project's Git commit history, found a security fix, realized it was incomplete, then hunted for other code paths with the same unfixed bug. In another, it understood the LZW compression algorithm well enough to know that a specially crafted input could force "compressed" output larger than the input -- triggering a buffer overflow that coverage-guided fuzzers would never find. That's how a human security researcher thinks, except it happened autonomously.
But here’s the double-edged sword aspect: everything that makes Opus 4.6 good at finding vulnerabilities for defenders also makes it good for attackers. 🏴☠️⚔️
And the guardrails at frontier labs only apply to their models. The open source AI ecosystem is advancing fast, so even if the black hats can’t use the frontier models, they won’t be far behind.
There’s also a structural asymmetry: defenders have to find and fix all the bugs; attackers only need one to get in. And as Anthropic themselves note, industry-standard 90-day disclosure windows may not survive AI-speed discovery.
Short-term, this favors defenders. Responsible labs can burn through a huge backlog of decades-old bugs in critical code. But the equilibrium shifts once the easy wins are gone.
🎨 🎭 The Arts & History 👩🎨 🎥

📕 Jonathan Tepper’s Memoir (Pre-Order) 🇪🇸💉
If you’ve been on fintwit for a while, you may remember Jonathan as an active poster for many years. He recently wrote a very good memoir, now available for pre-order, that OSV’s Infinite Books is co-publishing along with a UK publisher.
What is it about?
In the shadows of Madrid's most notorious drug slum, an American missionary family plants roots among heroin addicts and builds an unlikely church. Shooting Up is Jonathan Tepper's searing memoir of a childhood spent in San Blas, where syringes littered playgrounds and his closest friends were recovering junkies twice his age.
When Elliott and Mary Tepper arrive in 1985 with their four young sons, San Blas is ground zero of Europe's heroin epidemic. While other children play soccer, Jonathan befriends bank robbers and former prostitutes. His heroes aren't athletes but men like Raúl and Jambri, charismatic ex-addicts who transform their lives through the revolutionary drug rehabilitation center the Teppers help found.
What begins as eight men in an apartment becomes Betel, now one of the world's largest drug rehabilitation networks. But this isn't a story of institutional triumph. It's an intimate portrait of radical compassion amid the AIDS crisis, told through the eyes of a boy watching his parents choose the damned over the respectable, witnessing miracles and tragedies in equal measure.
Tepper writes with unflinching honesty about the magnetic pull of the streets, the seductive danger of heroin, and the complicated love between broken people healing togetherThis is a memoir about “choosing to see beauty in ruins, finding family among outcasts, and learning that the answer to suffering is always more love.”
If you’re curious for more, there’s a review in the Times and an excerpt in The Telegraph.
🤘🏻🧑🏻🎤Rock on Liberty!👊🏻