

612: Anthropic Bull & Bear, Jeff Dean's Mind, Codex Spark & Qualitative Speed, Adults Out-Scrolling Kids, ChatGPT's Authority Laundering, and Haptic Visuality
"What does that even mean anymore?"

The world will ask you who you are, and if you don't know, the world will tell you.
–Carl Jung (paraphrased)

🏄♂️🧠 If you’re wondering what that is, it’s my balance board turned upside-down so you can see the magnetic stoppers and the ball.
I wrote a few times about how much fun I’ve been having learning to stand on this thing with the cylinder-roller thingy. But lately, it was getting a bit boring because I could stay on it for almost as long as I wanted (which is a nice problem to have, but… you know).
I had tried swapping the cylinder for the ball, but it was so hard, it just felt IMPOSSIBLE.
So I was kind of stuck until a convo with subs in the private Discord. They convinced me to give the ball another try. I started by holding on to a chair and doing a few minutes each day.
The human nervous system is a marvel, because I went from not being able to stand at all to being able to stand for a few seconds without holding on to anything!
It was a good reminder that most of us tend to give up too quickly. We stop trying before finding the real limits of what we can do, physically and mentally.
I don’t think I’ll be joining Cirque du Soleil any time soon, but it feels ridiculously satisfying to make progress on something this hard.
🌱👦🎧📺🎬 Was my youth impoverished by the fact that I didn’t have access to 100 million songs (Spotify) and thousands of films and TV shows on demand (Netflix, Disney+, Prime Video) like today’s kids?
Or was it enriched because I dove DEEP into what I did have?
Watching and listening to the same things over and over, bordering on obsession… it all got burned into my brain (🧠). Mystique from unanswered questions included, the stuff you couldn't look up on the internet yet. 🤔
🗣️🗣️🗣️☎️ Today at noon, I’ll be having a Zoom call with paid supporters of this steamboat. These are always lots of fun!
If you aren’t a supporter yet, it’s a bit late for this call, but you can join us on the next one by becoming a supporter:
🏦 💰 Business & Investing 💳 💴

Anthropic is Doing Amazing/is in Trouble 😵💫 🚀💣
Being able to hold uncertainty in your mind is a rare talent.
Most people try to resolve it as quickly as possible in one direction or the other.
Things are either good or bad. Binary minds in a probabilistic, nuanced world.
Anthropic and its CEO Dario Amodei have been front and center recently, partly because of Claude Code (now at a $2.5bn run rate!) and Opus 4.6. And partly because they raised $30bn at a $380bn post-money valuation.
I mean, look at the graph above 👆 That growth is just bonkers at that scale 🤯
As an aside, if this was an IPO, it would be and ranked #1 ahead of Saudi Aramco’s $29.4bn raise in 2019 (including the over-allotment). But raising $30 large ones in the private market is pretty unheard of, and has only been surpassed by (surprise!) OpenAI’s $40bn raise last year.
Another reason why the spotlight has been on Anthropic is Dwarkesh’s interview (which I encourage you to listen to fully):
And if that’s not enough, there’s also this recent interview by Bloomberg.
After seeing all this and hearing Dario’s ambition and predictions about where things are going, it’s hard not to be impressed and think that these frontier AI labs are world-changing, generational rocketships.
BUT
At the same time, I keep seeing all these Chinese open source models fast-follow just a few months behind the leading edge:

It’s not entirely clear how much benchmark overfitting is going on (on every side, to be clear), but what is clear is that frontier models get distilled/caught up with fairly quickly, so the big labs are on a treadmill.
My friend MBI (🇧🇩🇺🇸) had some great thoughts about all this in this daily update (🔐):
Notice how Amodei himself acknowledges that without training the new model (or without having access to ample compute to train one), they may fall behind and demand may evaporate pretty fast if that happens. If that’s the case, why are we ignoring cost of training in gross margin calculation? [...]
And it’s not just that you lose bragging rights. You lose customers.
In a world of fast-follow models and easy switching, enterprise loyalty might be measured in months, not years.
The exploding popularity of Codex vs Claude Code is a real-world example of this.
I hate to break it to Amodei, but not all of his competitors, especially Alphabet, need gross profit from the current generation of model, especially when they explicitly know if they can keep gross margin down, life becomes really difficult for their competitors. Alphabet have myriad other products to generate ample gross profit from elsewhere with $80 Billion net cash on balance sheet (and much greater ability to raise debt than its competitors). So, if Alphabet actually acts rationally, that might be Amodei’s nightmare. [...]
How can we assume the gross margin will remain so high when its more well funded competitors know they can exert unduly amount of pressure on Anthropic if they take the gross margin on inference to…say 30%? If Anthropic cannot get enough gross profit from today’s model, its hands will be tied for training the next one.
I really don’t know which of the superimposed narratives will win out in the end.
🐻 The Bear Case 📉
Will it turn out that OpenAI and Anthropic run out of steam over time because they can’t keep up with the demands of always spending more and more on new frontier models that have relatively short windows at the top because there’s commoditization pressure from the swarm of smaller labs who fast-follow? 🐢🐇🇨🇳
Most brutal: the giants can choose to make this a terrible game.
As friend-of-the-show Byrne Hobart (💚💚💚💚💚 🥃) wrote:
Google's capex guide this year is higher than their cumulative capex from founding through the end of 2021.Will Google (and Meta, if they can catch back up to the front of the pack) decide to use their legacy cash engines to keep funding frontier models in a way that businesses who need to raise external capital can’t? 💰💸
It’s not that Anthropic is weak. It’s possible that the game itself might not allow a durable advantage. 🎲🃏🎰
🐂 The Bull Case 📈
Or are we on the verge of changes that will make it so that OpenAI and Anthropic can capture more of the value they create, find durable moats, and become truly profitable and self-funding, training costs included?
Are we in the era of AI that is the equivalent of social networking before the newsfeed-with-ads, where some unlock changes everything? 🤔
Is it a case of: the problems are obvious but not the solutions, because if the solutions were obvious, the problems wouldn’t be problems 🔁, but that doesn’t mean there won’t be solutions.
And if the market trusts that solutions are coming, it’s very possible that they will fund the labs and provide a bridge all the way to the other side (along with Nvidia’s chequebook, maybe).
¯\_(ツ)_/¯
🗣️ Interview: Jeff Dean, Google’s Chief Scientist and 1,000x Engineer 👨🔬👨🔧🔮
Listening to Jeff Dean go into the weeds is always such a treat. He’s a legendary engineer, in the tier reserved for John Carmack and Jim Keller.
If you’re not familiar with him, he’s Google’s Chief Scientist and one of the company’s earliest engineers (he joined in 1999). He’s best known for building the “planet-scale plumbing” under modern computing, systems like MapReduce, Bigtable, and Spanner. He later led major AI efforts as well (including Google Brain), and co-created TensorFlow and shaped development of the TPU.
He’s so impressive that his coworkers created “Jeff Dean Facts.” Here are a few of my faves:
Jeff Dean proved that P=NP when he solved all NP problems in polynomial time on a whiteboard.
Jeff Dean was forced to invent asynchronous APIs one day when he optimized a function so that it returned before it was invoked.
Jeff Dean once implemented a web server in a single printf() call. Other engineers added thousands of lines of explanatory comments but still don't understand exactly how it works.
When Jeff Dean goes on vacation, production services across Google mysteriously stop working within a few days.
Jeff Dean’s PIN is the last 4 digits of pi.
When Alexander Graham Bell invented the telephone, he saw a missed call from Jeff Dean.
Anyway, there are tons more… but this gives you an idea of the legend of Dean among engineers!
Here are my highlights from the interview, first starting with the interactions between the model team and the TPU chip design teams, because things need to be predicted 2-6 years ahead of the curve:
Jeff Dean: I mean, we have a lot of interaction between say the TPU chip design architecture team and the sort of higher level model experts, because you really want to take advantage of being able to co-design what should future TPUs look like based on where we think the sort of ML research puck is going […] as a hardware designer for ML […] you’re trying to design a chip starting today and that design might take two years before it even lands in a data center. […]
So you’re trying to predict two to six years out where, what ML computations will people want to run two to six years out in a very fast changing field.
Model ↔ chip co-design, because hardware lives on much longer timelines than models.
The one-page memo that may have caused DeepMind and Google Brain to merge and explains why their model is called Gemini (👬♊):
Jeff Dean: I wrote a one-page memo saying we were being stupid by fragmenting our resources […] we were fragmenting not only our compute across those separate efforts, but also our best people […]
And so I said, this is just stupid. Why don’t we combine things and have one effort to train an awesome single unified model that is multimodal from the start, that’s good at everything. And that was the origin of the Gemini effort.[…]
[on why the name Gemini] it’s sort of like these two organizations really are like twins in some sense coming together. […] there’s also the NASA interpretation of the early Gemini project being an important thing on your way to the Apollo project.
Here he is on what programming may be like when the need to manage swarms of agents is essential:
Jeff Dean: imagine a classical software organization without any AI assisted tools, right. You would have, you know, 50 people doing stuff and their interaction style is going to be naturally very hierarchical […]
But if you have, you know, five people each managing 50 virtual agents, they might be able to actually have much higher bandwidth communication among the five people […]
On the growing importance of clear specifications and English as the new programming language (revenge of the wordcels? 🤔):
Jeff Dean: whenever people were taught how to write software, they were taught that it’s really important to write specifications super clearly, but no one really believed that.
Like it was like, yeah, whatever. I don’t need to do that. I mean, writing the English language specification was never an artifact that was really paid a lot of attention to. I mean, it was important, but it wasn’t sort of the thing that drove the actual creative process.
If you specify what software you want the agent to write for you, you’d better be pretty darn careful about how you specify that because that’s going to dictate the quality of the output, right?
The engineers who spent their careers learning to speak to machines are now building machines that need humans to get better at speaking to each other 😅
That’s just 4 highlights from a 90-minute peek into the mind of a truly rare engineer.
He also talks about the importance of latency, super large context (and how to fake it), model architecture, the future of personalized AI, how general models have been beating specialized ones, etc. I encourage you to listen to the whole thing 👋
📲 It’s not just the kids 🤳
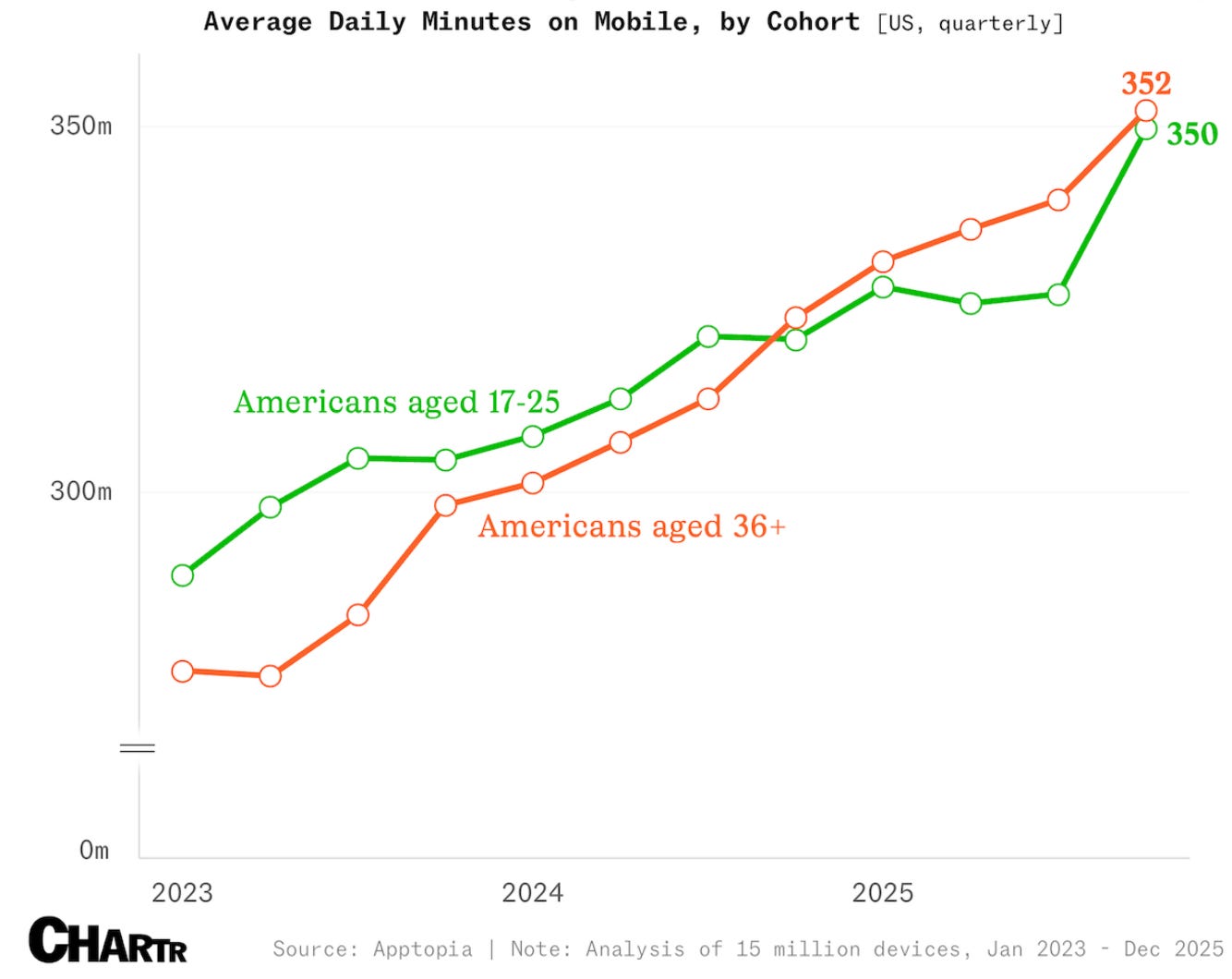
The tablets have turned (ok, that’s a baaaad pun 😬):
young Americans, regularly accused of mindlessly scrolling through never-ending brainrot on their devices […] Per figures from mobile app intelligence provider Apptopia, 17- to 25-year-olds in the US have actually spent less time on their phones than adults aged 36 and over of late (Source)
But before we celebrate, notice that both lines keep going up. The adults who spent a decade warning kids about screens are now the heavier users…
Today, “the average American spends 6.3 hours a day on their phone, up some 51 minutes from the 5.5-hour total recorded at the start of 2023.” 😮
🧪🔬 Science & Technology 🧬 🔭
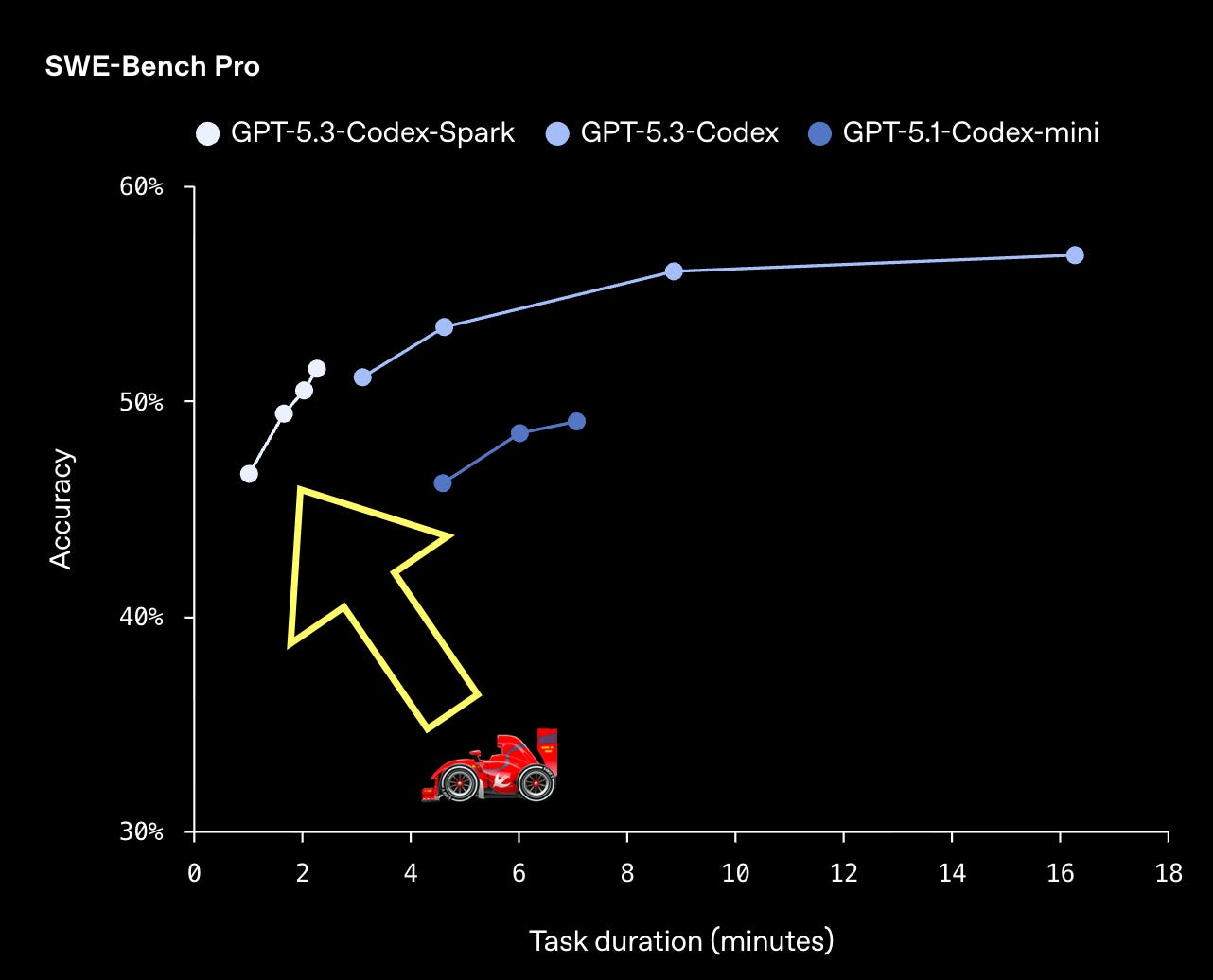
⚡ Codex Spark: Speed Can Be Qualitative 🌶️
OpenAI just shipped a research preview of GPT‑5.3‑Codex‑Spark: a smaller version of GPT‑5.3‑Codex designed for real-time coding. It’s served on Cerebras hardware, and the headline number is spicy: 1000+ tokens/second output speed, while staying “highly capable for real-world coding tasks.”
Why Cerebras?
Their signature product is the Wafer Scale Engine, which is literally a full silicon wafer turned into a single massive chip, designed to keep more of the working set (weights and KV cache) on-chip and reduce the overhead of shuttling data around.

There’s a threshold where a tool starts feeling like true pairing.
The model didn’t get smarter, but your brain stays in the same mental context, the same flow state. 🧠
Roughly:
When the latency is high, you batch. You over-explain. You ask for big changes less often. You tolerate a little wrongness because you don’t want to pay the time cost of correcting it. Friction friction friction…
When the latency is low, you steer. You interrupt. You try variants. You ask for lots of things you normally wouldn’t bother with if it was a big ordeal every time.
That’s why “1000 tokens per second” is less about just doing the exact same things faster (though that’s also good!), and more about doing things differently and better because of the qualitative difference in interactivity.
ChatGPT's Authority Laundering Problem: One Brand, Many Brains 🧠🤪 🔀 🧠🤓
You’re hanging out with friends, or maybe your in-laws, and someone says, “ChatGPT told me XYZ”. What does that even mean anymore?
OpenAI introduced the model router with GPT-5, a kind of switchboard that sends your prompt to one of several models behind the scenes. It’s a clever innovation with multiple benefits:
Less-technical users who may never have manually selected a model before could be automatically routed to better reasoning models for more complex queries.
OpenAI could better manage its compute budget than with a one-size-fits-all model that had to be all things to all users. Saving the big guns for the hard stuff.
By routing more queries to smaller models, casual users got answers faster and were more satisfied than if they had to wait.
Potentially less confusion around model names (is o3 better than o4-mini? Is 4o better or worse than o3?)
BUT
There’s one big downside to hiding complexity behind the curtain: When someone says “I checked it on ChatGPT,” you have no idea what actually happened.
You can’t know if they got a quick one-shot without using tools or web search from the smallest, dumbest model, or if they used the biggest, smartest reasoner that generated 60 pages of thoughts about it, ran Python code to double-check the math, and checked 30 different websites to confirm the facts.
They might have asked a Nobel laureate or a summer intern ¯\_(ツ)_/¯
Why is that a problem?
Authority laundering. “ChatGPT” sounds like a single authority. When someone cites it, they are borrowing that authority… while smuggling in total ambiguity about the process and the model quality. It’s like “I Googled it,” but much fuzzier 🔍🤔
This also creates a few downstream problems:
Reputation risk cuts both ways. If the free-tier model hallucinates or gives a shallow answer, the user might tell people “ChatGPT said X” and it damages the brand. But if someone hears “ChatGPT is amazing” from a power user on the top model, tries the free version, and gets mediocre results, they feel misled. Either way, the brand takes a hit.
It muddies public discourse about AI capabilities. When researchers, journalists, or just people at dinner say "AI can/can't do X," they're often generalizing from one interaction with one model tier. The variance between the floor and ceiling within a single brand is enormous now, arguably larger than the variance between brands at the same tier.
All this got even worse on December 11, 2025, when OpenAI removed the automatic router for free users and defaulted all of them to GPT-5.2-Instant. Before, free users sometimes got an answer from the reasoning model. Now, if they don’t manually pick a thinking model, they don’t get one. If I had to guess, I’d say that 99.999% of them never do.
I think Anthropic suffers less from this problem because their model size branding is more obvious and memorable (Haiku/Sonnet/Opus). Even non-technical users can remember which are ‘good/better/best’. Well, they also have almost no normie users, so that also avoids the problem… but if they did, I think their naming convention would help.
I wish OpenAI would do something similar. Even if they kept the router, better model branding with clearer signals about which tier you’re getting would help. Or give every answer a clearer ‘epistemic receipt’: which model, which tools, which sources (if any), and roughly how much work it did. I think that over time, even non-technical users would learn to understand the differences (similarly to how ‘GPT-4o’ became a well-known brand among many non-technical users, though probably not for great reasons… some people just love sycophancy 😬).
🎨 🎭 The Arts & History 👩🎨 🎥
🎞️ When Images Speak to Your Whole Body, Not Just Your Eyes 👀
Here’s a strong video essay on why modern movies feel less real than older films, even when those older movies were depicting ‘unreal’ dinosaurs or aliens with obviously more limited SFX.
The answer has to do with how cinema engages the body, not just the eyes.
Classic films often used deep focus, tangible textures, and careful sensory layering to create images you could almost touch.
The technical term is "haptic visuality," which sounds fancy, but describes something you’ve felt even if you didn’t have a word for it.
Modern films tend toward shallow depth of field, heavy post-production polish, and over-manipulated environments that look technically impressive but don't trigger the same tactile response, which is a shame. I hope filmmakers rediscover this art 🖐️
Thanks. Great post. As usual.
Wow 6.3 hours average time on our devices! Hopefully a significant percentage is listening to music or podcasts while hiking, biking or walking outdoors instead of all screen time.
Sad I missed the zoom session! Hopefully I can make it to the next one.
Great post as usual. Have a great weekend!