

614: Anthropic vs Chinese AI Labs, Private vs Public Markets, OpenAI, Stripe + Paypal, Meta + AMD, Perplexity, Data Center Video Game, and Dunk & Egg
"he joys of unconditional love and having a clear purpose in life"

Avoidable human misery is more often caused not so much by stupidity as by ignorance, particularly our ignorance about ourselves.
—Carl Sagan

⭐️🏆👍👎 I was listening to two of my favorite people on this episode of Infinite Loops, and toward the end, they discussed the star ratings of various books on Goodreads and Amazon. You should listen for yourself, but the gist is that online ratings often seem a little absurd, with Harry Potter outscoring Shakespeare, and masterpieces like Cormac McCarthy’s The Road scoring lower than clearly lesser works.
I’ve been thinking about this for years, and I think I know what’s going on.
Any time I look at the ratings for a film, TV show, book, or whatever, I always calibrate mentally based on this rough formula:
Audience self-selection × (How Good it actually is / Expectations)
That’s why genre books/films are so over-represented in any ratings-based Top 200 list. If you go on IMDb, you’ll see that #3 is The Dark Knight, above The Godfather Part II, and #6 is Lord of the Rings: Return of the King, above Schindler’s List and films like Goodfellas and Saving Private Ryan.
Films like Shawshank Redemption attract a wide cross-section of the population because very little about them will turn people away. “Oh, it’s about a murder and prison in the 1940s? Sure, I’m in.”
But then it way over-delivers on expectations for that kind of film with great performances, cinematography, writing, music, locations, drama, humor, suspense, mystery, memorable images and quotable lines. It deserves to rank as high as it does.
The flip side is genre. Harry Potter and Batman still pull enormous audiences, but anyone who hates superheroes or magic self-selects out. So the people who do show up are disproportionately the people who want that experience, and the best executions rack up massive scores from the people they were built for.
That’s why Shakespeare and The Road have the ratings they do.
They are being read outside their natural audience for various reasons. Shakespeare is forced on people in school, or people check it out because they think they have to (prestige guilt, resulting in high expectations), and then they don’t enjoy it much. The Road was no doubt read by many people who expected a more traditional post-apocalyptic thriller and couldn’t handle the sparse, poetic bleakness.
There’s also a difficulty factor. Nobody picks up Dan Brown expecting to be challenged. Plenty of people pick up Shakespeare expecting to enjoy it because they’ve been told it’s great — and then they hit a wall of language that was never designed for casual consumption.
Sometimes there’s a different kind of expectations mismatch. Something is really good, but it’s soooo hyped that everyone goes in expecting the Best Thing Ever. When it’s ‘merely great’, they rate it more harshly than if they had walked in cold.
So when you look at a rating, you have to ask “Who’s doing the rating?” and compare your own taste and preferences with the likely taste and preferences of the average reviewer who self-selected into watching/reading that thing.
It’s not so much that the ratings are wrong. It’s that they’re measuring something closer to “did this satisfy the people who showed up?” than “is this objectively high quality?”
Fourth Wing by Rebecca Yarros has better Goodreads scores than any Shakespeare. All it means is that the people who picked it up got more of what they came for on average than the people who picked up Shakespeare.
Once you see it that way, ratings become a lot more useful. A high score on something with broad, non-self-selected appeal (Shawshank, Forrest Gump, Breaking Bad) is a stronger signal than a high score on something where the audience pre-filtered for fans (Captain America). And a “low” score on a classic might just mean it keeps getting read by people it was never trying to reach.
🔎📫💚 🥃 Exploration-as-a-service: your next favorite thing is out there, you just haven’t found it yet!
If this newsletter adds something to your week, consider becoming a paid supporter 👇
🏦 💰 Business & Investing 💳 💴
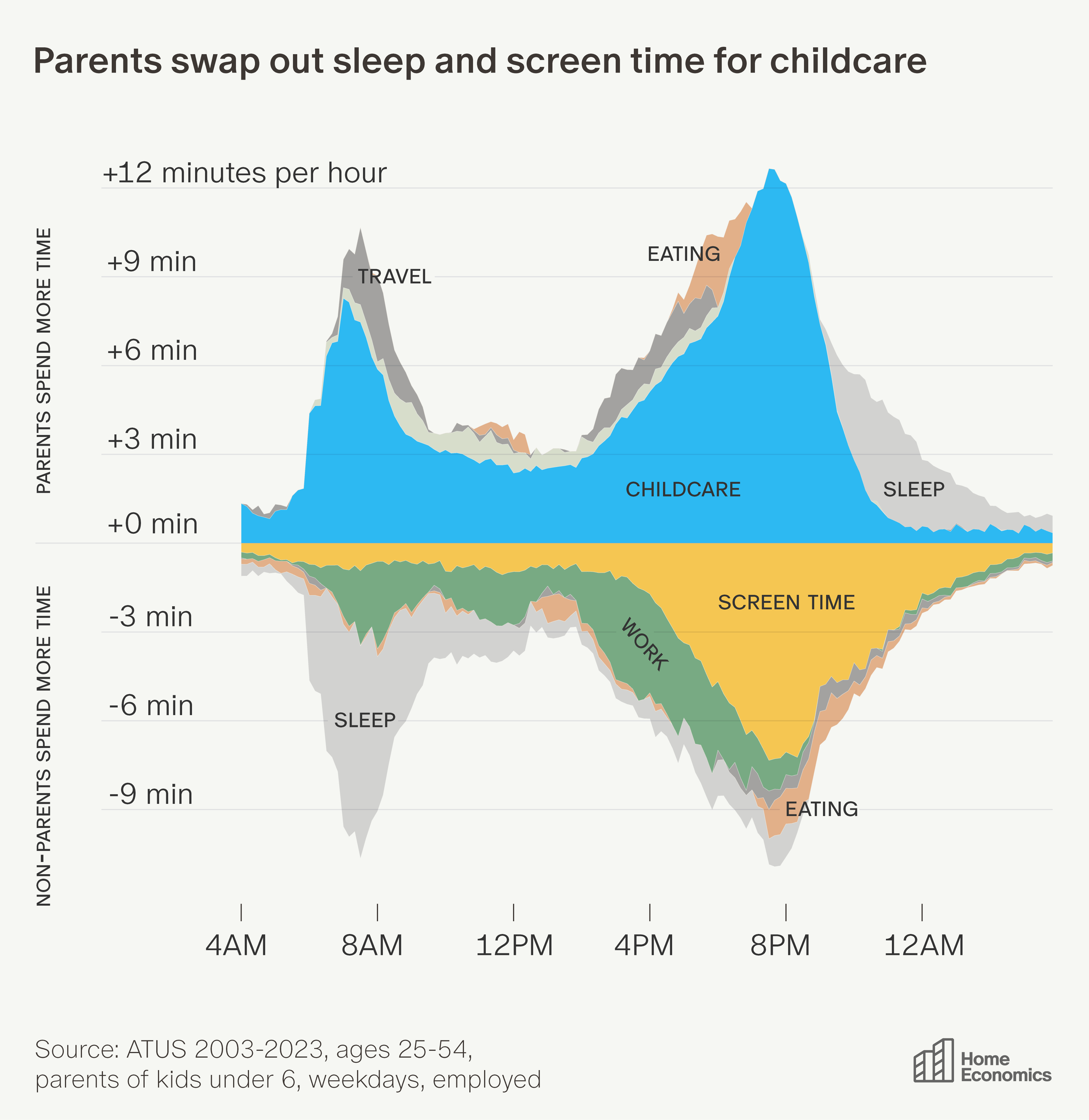
🏡 Time at Home for Parents vs Non-Parents 🚸
Aziz Sunderji created this great graph by looking at the U.S. Census Bureau’s American Time Use Survey.
“Areas above zero are activities parents do more of; areas below are what they give up.”
The morning childcare wave comes mostly from sleep: parents of young children sleep 16 fewer minutes between 4 and 9 a.m. They also do less work in the morning—which continues throughout the day (by 6 p.m. they will have done 24 fewer minutes of work).
Parents recoup the time needed for childcare in the evening from TV and other screen time: parents do 28 fewer minutes of phone/TV time between 5 and 10 p.m., redirecting nearly all of it to childcare (43 extra minutes over those five hours).
By 9 p.m., parents have accumulated a sleep deficit of 28 minutes compared to non-parents. They claw some of it back by going to bed earlier, but still end the day 16 minutes short (parents to infants end the day with 32 minutes less sleep).
Sounds like a good trade to me for the joys of unconditional love and having a clear purpose in life. Nobody ever said on their deathbed that they wished they’d watched more TV and doom-scrolled more.
🇨🇳🔎🤖 Chinese AI Labs Built a 24,000-Account Operation to Clone Claude (and what this reveals)
Anthropic published a detailed forensics report this week alleging that DeepSeek, Moonshot (Kimi), and MiniMax ran coordinated campaigns to extract Claude's capabilities through model distillation. 16 million exchanges. Roughly 24,000 fraudulent accounts. That's not a few interns copy-pasting prompts. That's infrastructure.
When you train a smaller model on the outputs of a stronger one, the smaller model absorbs capabilities that would have taken years and enormous compute to build from scratch. Frontier labs do it to their own models constantly to build cheaper, faster versions. What Anthropic alleges here is the same technique pointed at someone else's model, using fake accounts and proxy services to access Claude at scale and extract what they needed, in violation of terms of service and regional access restrictions.
MiniMax ran over 13 million exchanges. When Anthropic released a new model while MiniMax's campaign was still active, MiniMax pivoted within 24 hours, redirecting nearly half their traffic to start capturing capabilities from the latest version. That looks like an exfiltration pipeline with an ops team watching a dashboard. Anthropic traced Moonshot's campaign back to metadata matching the public profiles of senior staff at the lab.
The second-order point is the one getting buried.
The best argument in favor of export controls came from the people trying to route around them. The argument against chip export controls has always been: other countries will just innovate around them, so the controls mostly disadvantage American companies without doing much. Distillation attacks undercut that narrative directly. If Chinese labs need to run industrial-scale covert operations to close the gap, they weren’t getting there as fast without shortcuts.
You don't build a 24,000-account covert extraction operation for something you could just build yourself. The operation is the admission that the gap is real and hard to close legitimately.
Without visibility into these attacks, the apparently rapid advancements made by these labs are incorrectly taken as evidence that export controls are ineffective and able to be circumvented by innovation.
Worth flagging: Anthropic has obvious incentives to publish something like this, and I can't independently verify the forensics. They're making the case for export controls. My guess is that making this public is partly about establishing a public record before policy debates in Washington get more heated. The “export controls don’t work” argument has real traction in some circles.
But if the forensics hold up, the conclusion writes itself: that's not evidence the controls failed, it's evidence they worked well enough that someone decided to drink Claude through a straw. 🥤
📊 Private vs Public Markets (The No-Marks Premium) 💵
In theory, it doesn’t take that many buyers and sellers to get a pretty efficient price discovery mechanism. All else equal, more is better, but enough is… well, enough.
Remember when ‘Unicorns’ were a big deal? 🦄
Private companies being valued at ONE BILLION DOLLARS were making headlines. Then a few years later it was Decacorns…
But today, we’re seeing private companies raise money at valuations in the hundreds of billions with a few approaching the trillion-dollar level (OpenAI, SpaceX).
In fact, Anthropic's latest valuation makes it larger than most of the Mag7 just 10 years ago, and larger than all of them 15 years ago. And these businesses were already considered huge back then, with many doubting that they could maintain such large market caps going forward.
How efficient are private markets at valuing these assets?
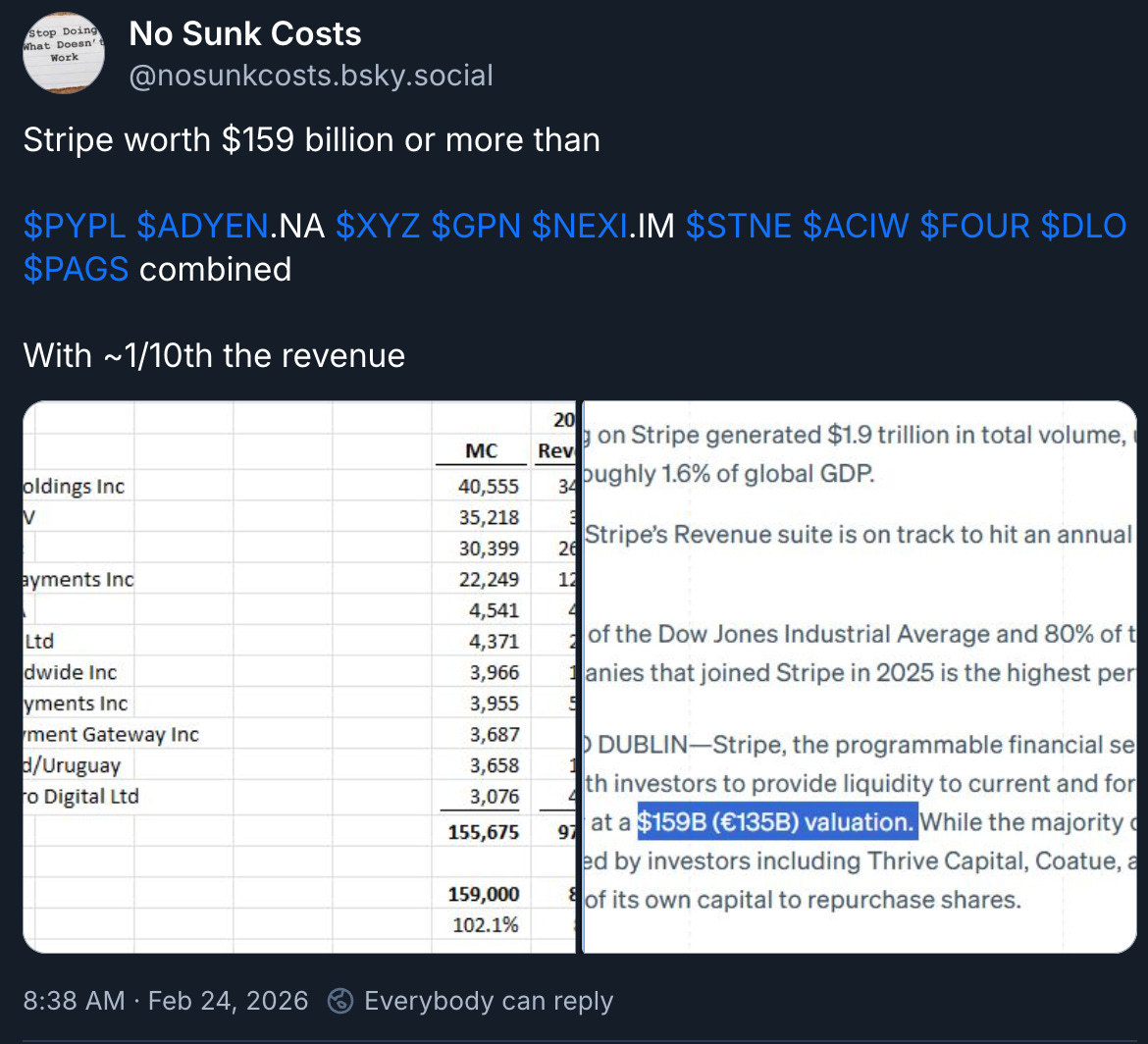
As No Sunk Costs writes, is Stripe really worth more than all these other payment companies combined, with a fraction of the revenue?
Stripe is strong, but if it was public, would it really trade completely differently from the rest of its industry? How much of the disconnect comes from sources of capital putting a huge premium on NOT getting daily marks and pretending that their assets don’t suffer from volatility?
Update: After I wrote the above, Bloomberg published that Stripe was considering an acquisition of PayPal, making the stock jump 7%. It would be messy, but if Stripe could arbitrage the huge delta between public vs private multiples with an all-stock deal, why not?
What happens when OpenAI and Anthropic go public?
¯\_(ツ)_/¯
Meta 🤝 AMD for 6 Gigawatts of Compute, Zuck Gets Warrants for Up to 10% of the Company
The ink is barely dry on the ‘long-term infrastructure partnership’ between Meta and Nvidia that I wrote about in Edition #613, and they are already making a monster deal with AMD. But there’s an important difference!
This has echoes of what happened between OpenAI and Nvidia, and then OpenAI and AMD (see Edition #594), and shows who has leverage.
When OpenAI bought a ton of compute from Nvidia, it was Jensen who got a piece of OpenAI equity. When they bought compute from AMD, it was Altman who extracted warrants that can be worth 10% of AMD’s equity (if all milestones are reached).
I wrote:
From OpenAI’s side, those penny-strike warrants behave like a contingent, back-end rebate paid in AMD stock. Or in other words, if the AMD GPUs were full price, OpenAI probably would have preferred to stick with Nvidia, but at what is functionally a large discount, hey, why not, we need all the compute we can get!
If they end up being exercised, it means AMD is doing well and OpenAI is getting part of its compute expenses “refunded” in equity. [...]
It signals that AMD is in a weak position, and if you’re considering a big order from them, maybe you should try not to pay full price. It makes me wonder if it wouldn’t have been better for AMD to offer OpenAI a secret discount instead of that equity, but it’s possible that Sam Altman really wanted the equity to capture more of the potential upside.
Well, Meta was paying attention. Why pay full price to AMD when there’s precedent that you can get an equity rebate?
Zuck’s not going to get a worse deal than Sam…
Meta Platforms has agreed to buy 6 gigawatts’ worth of artificial intelligence computing power from Advanced Micro Devices in a deal valued at more than $100 billion that could result in Meta owning as much as 10% of AMD’s stock.
The deal includes warrants for 160 million shares of AMD at $0.01 each, contingent on delivery milestones, and with the last tranche needing AMD stock to reach $600 or more.
Isn’t it interesting that these days, a $100bn+ deal is kind of 🥱 while just a few short years ago, it would have been a historic blockbuster. How fast things change (see also what I wrote about private markets and unicorns…).
Under the agreement, Meta will buy enough of AMD’s latest chips, known as the MI450 series, to power data centers using up to 6 gigawatts of computing power over the next five years. Each gigawatt of computing power means several tens of billions of dollars in revenue for AMD, the company said. Meta is expected to deploy the first gigawatt starting later this year.
The order is large enough that AMD will create custom versions of the MI450 for Meta, optimizing them for their specific stack (ordering off the menu, once again 👨🍳).
This isn’t just about GPUs, though. Meta needs a lot of CPUs too:
In addition to the collaboration on GPUs, AMD and Meta are expanding their AMD EPYC processor partnership. [...] Building on deep roadmap alignment, Meta will be a lead customer for 6th Gen AMD EPYC CPUs
As AI agents start doing more tasks, demand for CPUs is likely to increase rapidly because agents can use more application software in parallel, more rapidly, 24/7 in ways that humans can’t.
Even if most model work stays on GPUs, agentic systems drag a growing stack of CPU-heavy orchestration behind them.
As part of the arrangement, AMD has agreed to give Meta warrants to buy up to 160 million AMD shares—or roughly 10% of the company—for $0.01 apiece, as long as certain milestones are met.
One of the biggest benefits of the deal with AMD is probably that it gave Zuck the leverage to negotiate better prices from Nvidia, because they were no doubt using that as a bargaining chip as they worked out the terms of that other deal. So equity in AMD + probably better pricing from Nvidia.
Not bad if you can get it!
🤷♂️ Perplexity Abandons Ads Monetization Dreams 💸
After being one of the earliest AI companies to implement ads:
The move marks a major change for the company, which was one of the first AI firms to start experimenting with ads in 2024. CEO Aravind Srinivas said on a podcast that year that he predicted ads would eventually be the company's core monetization engine. "I think with advertising we could be really really profitable," he added.
It seems like they just never reached escape velocity. They were early at having an effective web search and had massive user growth until everybody else got good at search (more on that later in this edition). This kneecapped their growth and prevented them from reaching the scale at which advertising makes sense.
Who’s going to buy ads on Perplexity’s immature platform to reach a small audience in an unproven way when they can just spend on Google and Meta?
I guess we got the answer…
It’s too bad because I really liked Perplexity. But the lesson here is that even if you have really good execution, if you’re trying to build something on other people’s models and prove there’s demand for it, the labs can usually just add those features themselves.
What kind of defensible, durable differentiation can AI startups even have these days? Either they do something so niche that the labs don’t care about it (but the functionality may still get incidentally absorbed by the big general models as they become smarter), or they hit on a rich vein and attract the attention of some PM at OpenAI or Anthropic.
It’s a tough game if you don’t own a frontier model!
🧪🔬 Science & Technology 🧬 🔭
📄🔍🤖 Anthropic is Teaching Claude What to Ignore in Web Search
Here’s a problem I hadn’t thought much about until I read Anthropic’s blog post: web search is absurdly token-expensive for AI models.
When an agent needs to answer a question by searching the web, it pulls in full HTML pages. That means navigation sections, banners, sidebar ads, headers and footers, the whole mess. Then it tries to reason over all of it.
Most of that context is irrelevant noise.
And here’s the thing: it doesn’t just waste tokens, it actively degrades the quality of the answer. The model is essentially trying to find a needle in a haystack after someone dumped in extra hay for no reason. 🪡
Anthropic’s fix is clever, in the classic way where it feels obvious the moment you hear it. In fact, anyone else who wasn’t already doing this must be working on implementing it now… I doubt it’ll stay a competitive advantage for long, but users of the models will benefit.
They call it dynamic filtering. Their updated web search and web fetch tools now have Claude write and execute code during the search to filter results before they hit the context window. Instead of dumping raw HTML into the model’s working memory and hoping for the best, the model dynamically writes little Python scripts to parse, extract, and discard useless stuff and keep only what’s relevant.
Context is precious, like RAM (especially these days!). If you treat it as an unlimited dumpster, you get worse reasoning; if you treat it as a tight working set and push the messy intermediate work into code execution, you get both higher accuracy and lower token burn. The model becomes its own pre-processor.
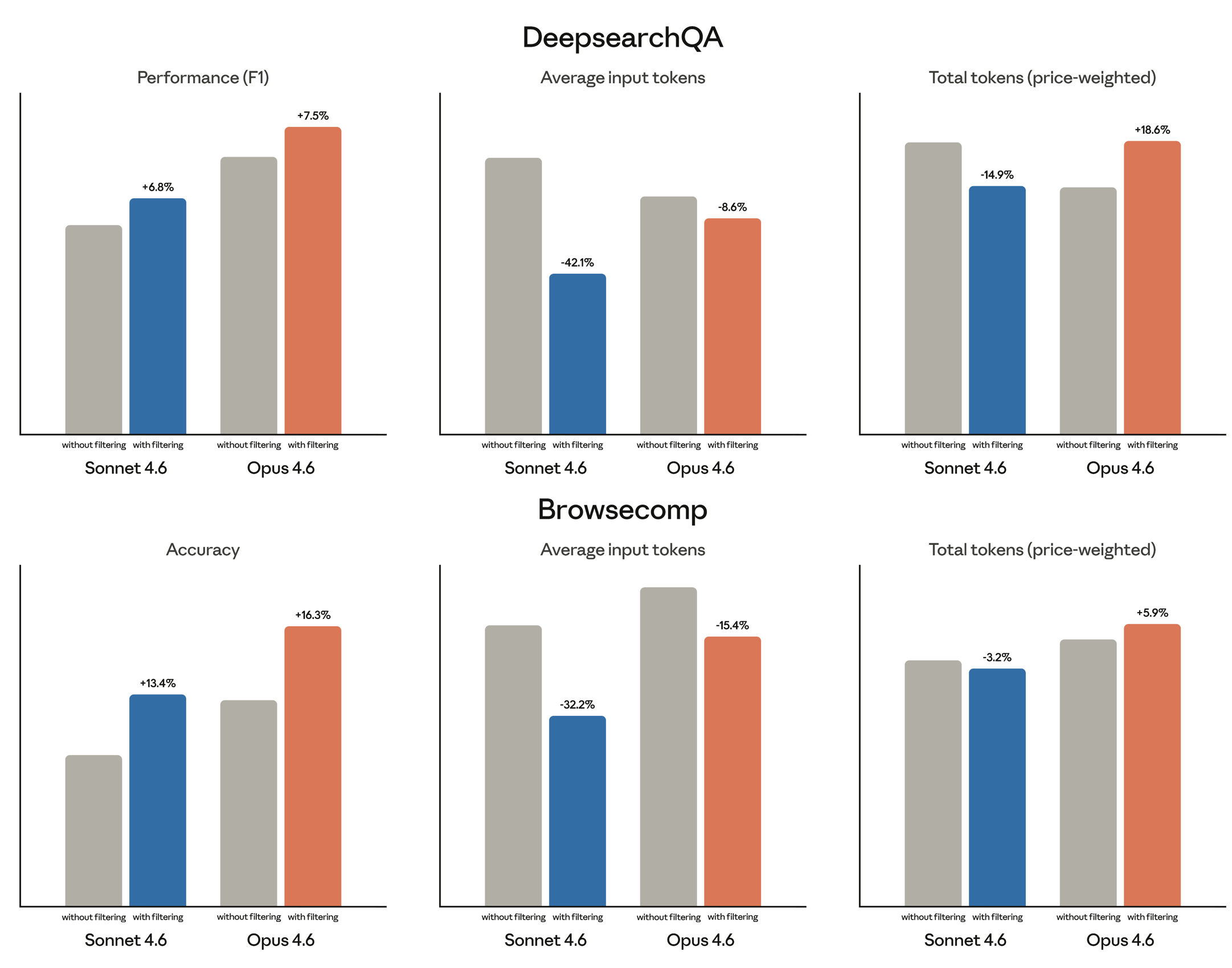
Anthropic claims the benchmarks improved meaningfully.
On BrowseComp (find one hard-to-locate fact) dynamic filtering moved Opus 4.6 from 45.3% to 61.6% accuracy. That’s a 36% relative improvement from what is essentially a workflow optimization, not a model architecture change. Sonnet 4.6 went from 33.3% to 46.6%.
On DeepsearchQA (multi-step research queries with many correct answers) Opus went from 69.8% to 77.3%. And all of this while using 24% fewer input tokens on average.
That last part deserves to be highlighted.
In AI, “better AND cheaper” is rare. Usually, you’re trading compute for quality or quality for speed.
If these gains hold in production, getting 11% better accuracy while burning 24% fewer tokens is the kind of efficiency gain that compounds. Every API call costs less and returns better results. For developers building agents that search the web thousands of times a day, that math matters a lot.
But token counts aren’t the same as token costs! Anthropic said that Opus’s price-weighted tokens actually increased on some benchmarks, because the model writes more elaborate filtering code. So this is not a free lunch in every situation.
What I find most interesting here is the meta-pattern.
This isn’t a bigger model or a new training technique. It’s the model using tools on itself, writing code to clean up its own inputs before reasoning over them.
My guess is we’ll see a lot more of this “selective attention via tooling” approach across agentic systems, for a simple reason: context windows aren’t getting cheaper fast enough relative to how much information agents need to process. The models that get good at not reading the internet — at quickly deciding what to ignore — will be the ones that feel most reliable in the real world.
It’s the AI version of an old research skill we used to teach in school: knowing what to ignore is at least as important as knowing what to read. 🎓
Hallelujah: ‘Single vaccine could protect against all coughs, colds and flus’ 🦠🚫🫁
As a parent of young kids who has been sick countless times since they were born, this is the kind of stuff that I want science to do for me!
A single nasal spray vaccine could protect against all coughs, colds and flus, as well as bacterial lung infections, and may even ease allergies, say US researchers.
The team at Stanford University have tested their “universal vaccine” in animals and still need to do human clinical trials.
But how could a single vaccine cover such a wide range of viruses? Are they cramming multiple vaccines into one? Wouldn’t it be impossible to get all strains in there and up to date?
There’s a clever solution, and it’s not “one bottle with 47 antigens.” It’s more like temporarily changing the lung’s default security posture.
Here’s the core idea:
The new [nasal spray] vaccine doesn’t try to mimic any part of a pathogen; instead, it mimics the signals that immune cells use to communicate with each other during an infection.
Every vaccine developed in the last century trains the immune system to recognize a specific enemy. Basically, here's the mugshot, watch for this guy. This one doesn't bother. It just tells the guards to be on high alert.
Mechanistically, the formulation combines TLR ligands (immune “alarm” signals) with a harmless antigen that helps recruit and sustain memory T cells in the lung. The specific antigen doesn't really matter, which is part of what makes this approach so unusual. Those T cells, in turn, “imprint” alveolar macrophages to stay ready for longer than usual.
The result (in mice):
Protection for at least ~3 months after dosing
Viral burden in the lungs dropped roughly 700-fold. That's not a rounding error!
And when pathogens did get through, the adaptive immune response kicked in unusually fast
And as a bonus, they showed the vaccine also protects against two species of bacteria - Staphylococcus aureus and Acinetobacter baumannii, notorious hospital-acquired pathogens, particularly dangerous when drug-resistant. It even reduced allergic airway responses to a house-dust-mite protein!
Pulendran told the BBC: "This vaccine, what we term a universal vaccine, elicits a far broader response that is protective against not just the flu virus, not just the Covid virus, not just the common cold virus, but against virtually all viruses, and as many different bacteria as we've tested, and even allergens.
We’re not there yet. Mice are not humans, etc. 🐁
Anything that keeps innate immunity revved up raises obvious questions about the safety/inflammation tradeoff in humans. But it’s not like getting sick isn’t without downsides, so let’s figure it out!
If it works, it’ll be such a boon for humanity. Grandparents who get to see their grandchildren grow up. Billions of sick days that never happen. And just... fewer miserable Tuesdays for everyone. It's hard to think of many medical interventions with a better "misery removed per dollar" ratio.
Here’s the study if you want more details.
🎮 Manage a Data Center… in a Video Game?!
I’ve seen trucking and farming simulators, but this is a first.
I wonder if some kids will get lucrative jobs in a few years partly based on the experience they got playing this 🤔
🎨 🎭 The Arts & History 👩🎨 🎥
⚔️🐉 A Knight of the Seven Kingdoms Debrief 🛡️🎪
🚨 SPOILER WARNING 🚨
Watch the video above ONLY if you’ve seen the show, as there are spoilers for multiple episodes.
But if you’ve seen the show, you gotta check it out. It’s a beautiful way to show the kind of attention to detail that a good director puts into their work.
Think of all the planning that went into getting certain shots to echo each other and create certain visual metaphors. Most viewers probably never notice consciously, yet it enriches the emotional language of the show.
Now that I’ve seen all episodes, I can say: Man, that was good. It’s tight, it’s human, it never forgets the personal stakes. One of my favorites shows of the past few years. 👍👍
I need to find some time to read the novella soon.
The relationship between Dunk and Egg reminded me of something we discussed on the White Mirror podcast, about the importance of friendships in fiction. The example we discussed was Andy Weir’s excellent Project Hail Mary, which I’m hoping will get a good adaptation (signs are good so far 🤞 — mark your calendars for March 20, 2026).
The friendship isn’t fully formed yet, but there’s potential for a great one over the next few seasons.
The quality of the craftsmanship on the show made me want to watch ‘making of’, and thankfully, there’s pretty good stuff on the official Game of Thrones Youtube channel.
If you want to go even deeper, the House of R podcast has reaction and analysis for each episode, somehow turning 35 minutes of screentime into 3 hours of discussion.