

628: Apple’s Air Traffic Controller Strategy, Anthropic's $30bn ARR + TPU Deal, Meta's Leaderboard, Berkshire Hathaway’s Mountain, Visa, Moody's & S&P Global, Max Life Expectancy, and Andy Weir
“are you competing against Costco’s hotdog?"

Every skill you have today was once unknown to you.
—James Clear

📅🌭🚢💸 I was discussing newsletters with a friend who’s better at this stuff than I am. He said, and I quote: “are you competing against Costco’s hotdog? 😅 I think you should definitely raise price.”
I thought, when’s the last time I did that? 🤔
Oh, right, never.
So after not touching it since 2020, I’ve decided to adjust subscription prices for the first time to catch up with inflation. According to official CPI, each dollar now only has 79.2% of the value it had then.
Here’s the deal:
I’m making the change on May 1, 2026. ⏳
Monthly goes to $15 and annual to $150, from $12 and $120.
If you want to lock in the old prices for a year, you can get an annual subscription before May 1st, and for 12 months, you’ll get the old, 2020-era price. 🔐
If you’re an existing supporter, the new price kicks in at your next renewal. If you’re monthly, you can also switch to annual before May 1st to lock in the old price (on top of the usual 17% discount for going annual).
Thank you for your support 💚 🥃
Without you, I’m just a guy in pyjamas going clickety-clack on the keyboard, sending bits into the void 🌀
🏦 💰 Liberty Capital 💳 💴
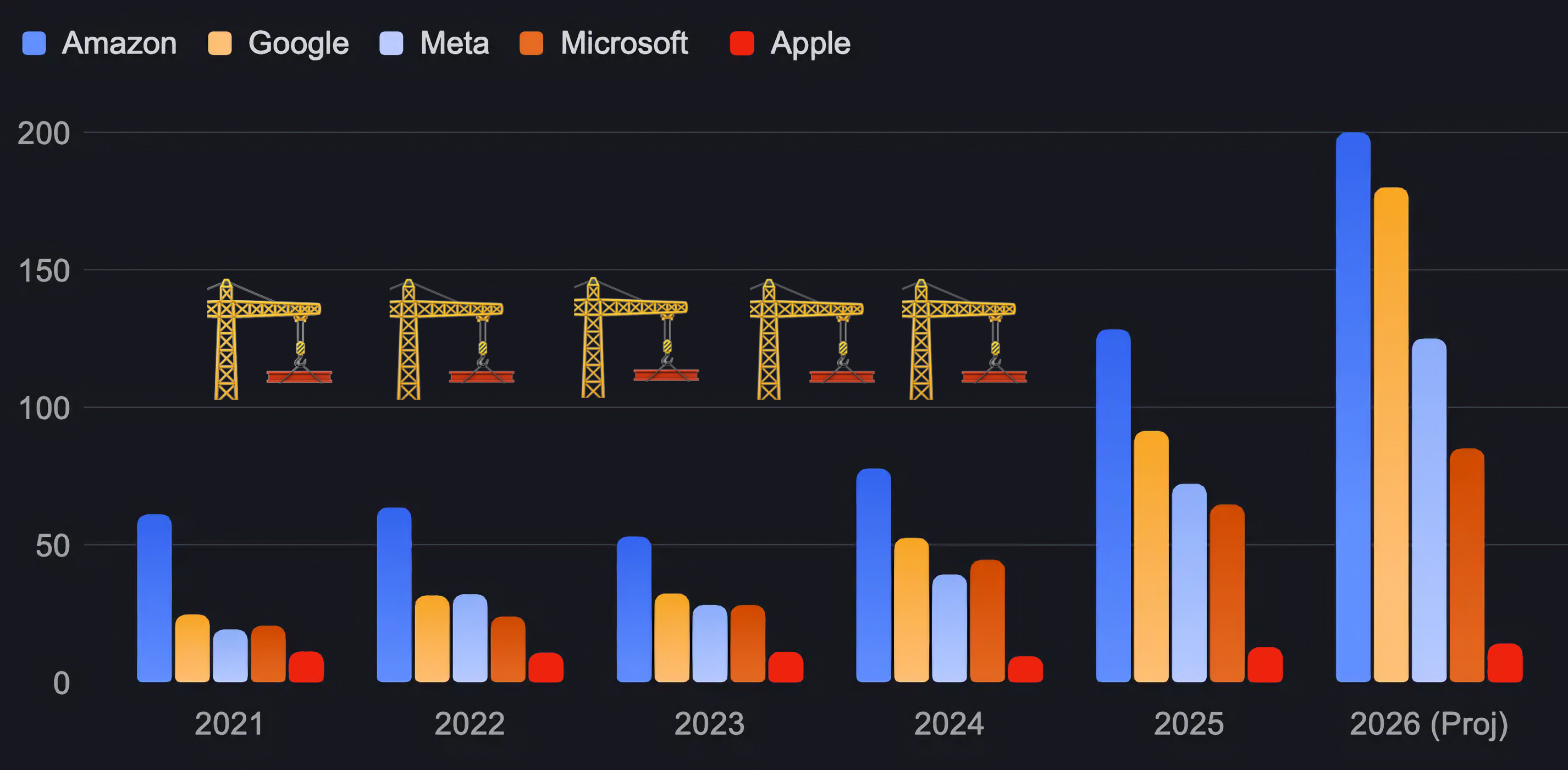
🍎 Is Apple’s Air Traffic Controller Strategy Working? 🧑✈️✈️
One of these is not like the others 👆
Did Apple go from AI loser to potential AI winner by… Thinking Different? 😬
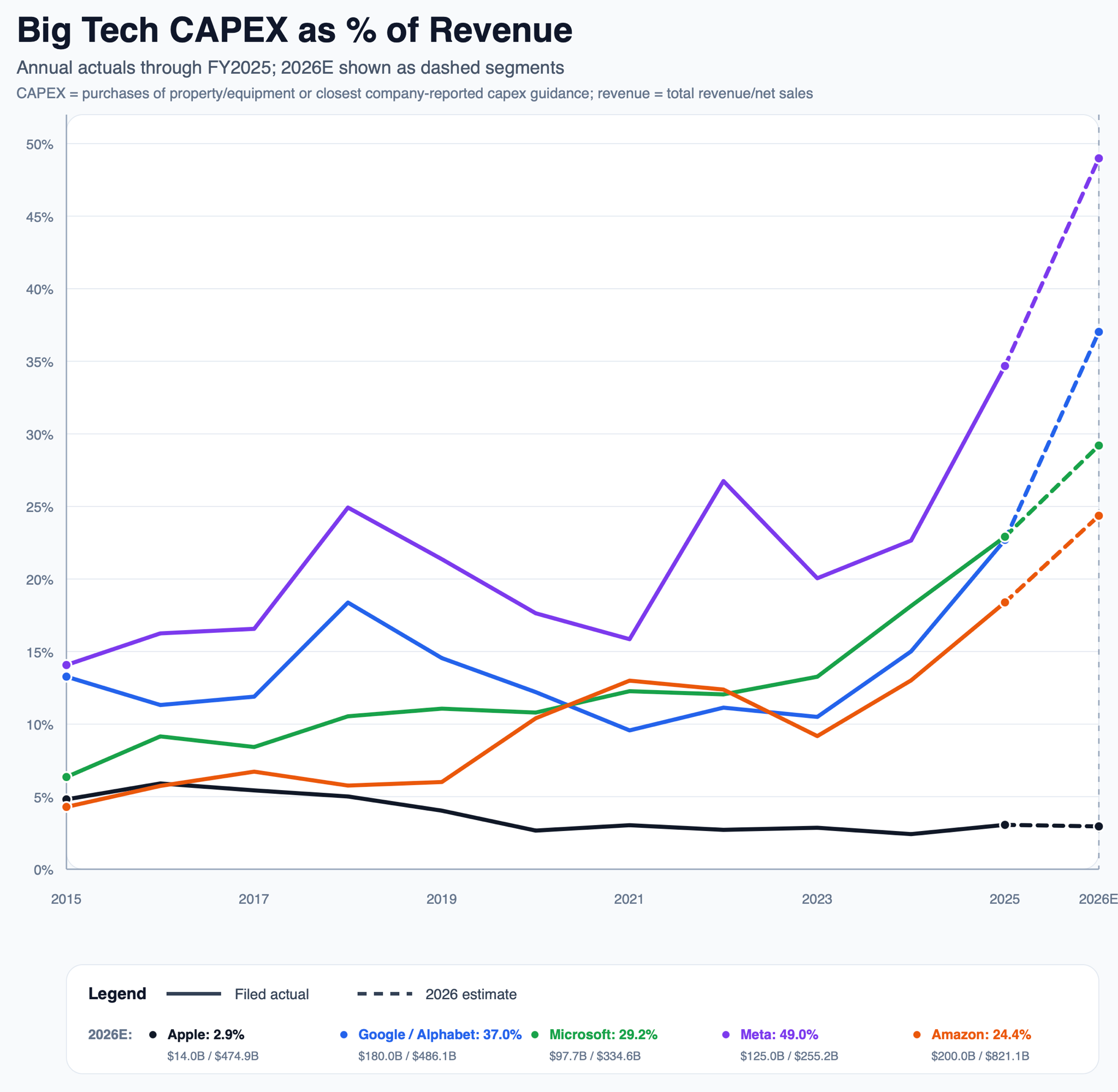
Everybody else is turning free cash flow into compute capex as fast as they can. Jensen is smiling. 😎 Apple is doing almost none of this. If we’re in a world where the first to AGI gets rewarded with World Domination™️, that strategy looks crazy.
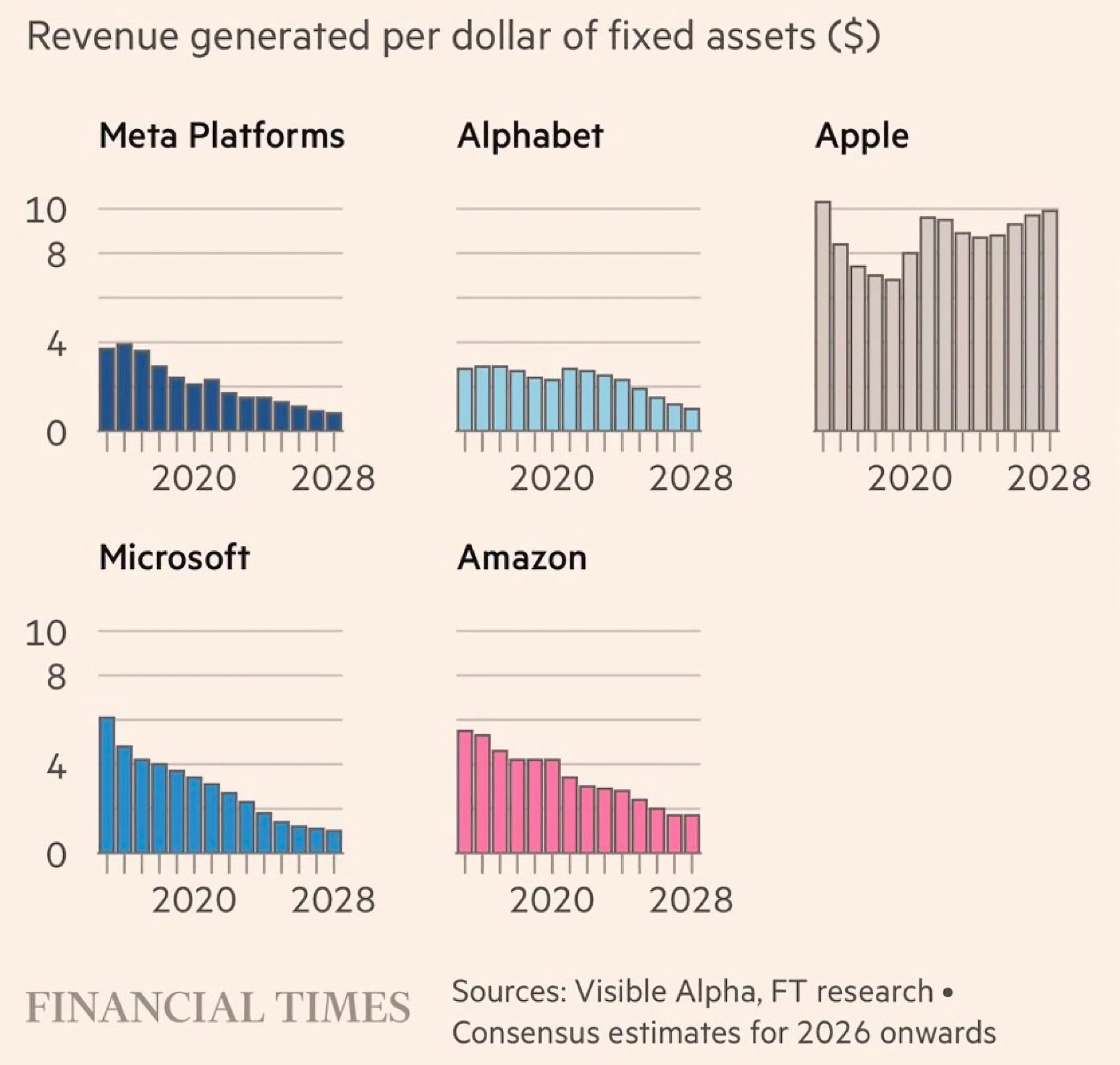
BUT
If Ben Evans is closer to correct, and the models — as useful as they are! — are commoditized and function as more of a sustaining innovation, maybe it will pay more to own a differentiated chokepoint elsewhere in the value chain. Say, a software/hardware platform with a lock on the top end of the market, like the iPhone and Mac.
If you can’t own the planes, own the airport 🛫
Recent news suggests that Apple will open up Siri to multiple AIs in iOS 27, turning them into suppliers who compete for access to valuable customers.
It has also been reported, though not confirmed, that Apple would not only use Gemini, but that their deal with Google also allows them to distill it into its own custom models.
This reminds me of Edition #487 (all the way back in the Mesoproterozoic era of 2024!), where I wrote:
“In the tradition of commoditizing complements, I expect Apple to view AI as something that makes a product better, not the main course. Their priority is to sell more iPhones, not monthly subscriptions (those will come if they sell products).
They should frame it something like this:
Others are great at making foundational models. We want to focus on the *experience* of using these models. So we’ve created Apple Air Control™️, an AI that sits on top of other models, abstracts them away, and picks the best tool for the job, all with a beautiful and intuitive interface!
Do most users care which model is under the hood as long as it is really good and useful? [...]
If I were Apple, I’d go with a constellation of models. Fully modular.
I’d start with small models that can run on-device to take advantage of the very powerful silicon in iPhones and ARM Macs. They have fast GPUs and Neural Engines that are great at accelerating generative AI and their unified memory architecture means that more RAM is available for genAI than for most of the competition.
If simple tasks are run locally, you get lower latency and save on cloud inference costs.
Anything complex can be sent to larger models in the cloud. That’s where an Apple traffic cop model 👮🏻♂️ would do triage: some tasks would go to open-source models like Mistral or LLaMA and others to OpenAI, Anthropic, or Gemini. 🤖🤖🤖🤖
By using multiple models, they could probably get better pricing and potentially better performance by selecting the model that is best at any one moment or for a specific task. Things change so fast that today’s leader may be tomorrow’s laggard.
This would also keep the spotlight on Apple’s brand, not on the models (ie. from a user’s perspective, you’d think of going to Siri AI, not ChatGPT or Gemini).”
A lot has changed since 2024, but this approach could still make sense, especially in the consumer area where Apple is strongest (they won’t compete with Anthropic for coding in the enterprise, even though they’ll be very happy for all vibe coders to run Claude Code from MacBook Pros 💻 and OpenClaw on Mac Minis 🦞).
😲🚀 Anthropic “Surpasses” $30bn ARR + Signs 3.5 Gigawatt TPU Deal with Google & Broadcom 🐜
Speaking of big capex, Anthropic went from about $9bn ARR at the end of 2025, which is less than four months ago, even though it feels like more because of recent time dilation, to >$30bn ARR today 🤯
That’s more revenue than Google had in 2010 (though run-rate vs actual, tbf). Except that at the time, Google was growing 20-30% per year, not per month.
Even if the way they recognize revenue is a bit different from OpenAI, it’s clear who’s the unstoppable bullet train right now 🚅
When we announced our Series G fundraising in February, we shared that over 500 business customers were each spending over $1 million on an annualized basis. Today that number exceeds 1,000, doubling in less than two months.
Even on a log graph, it looks almost like a non-log graph 😅
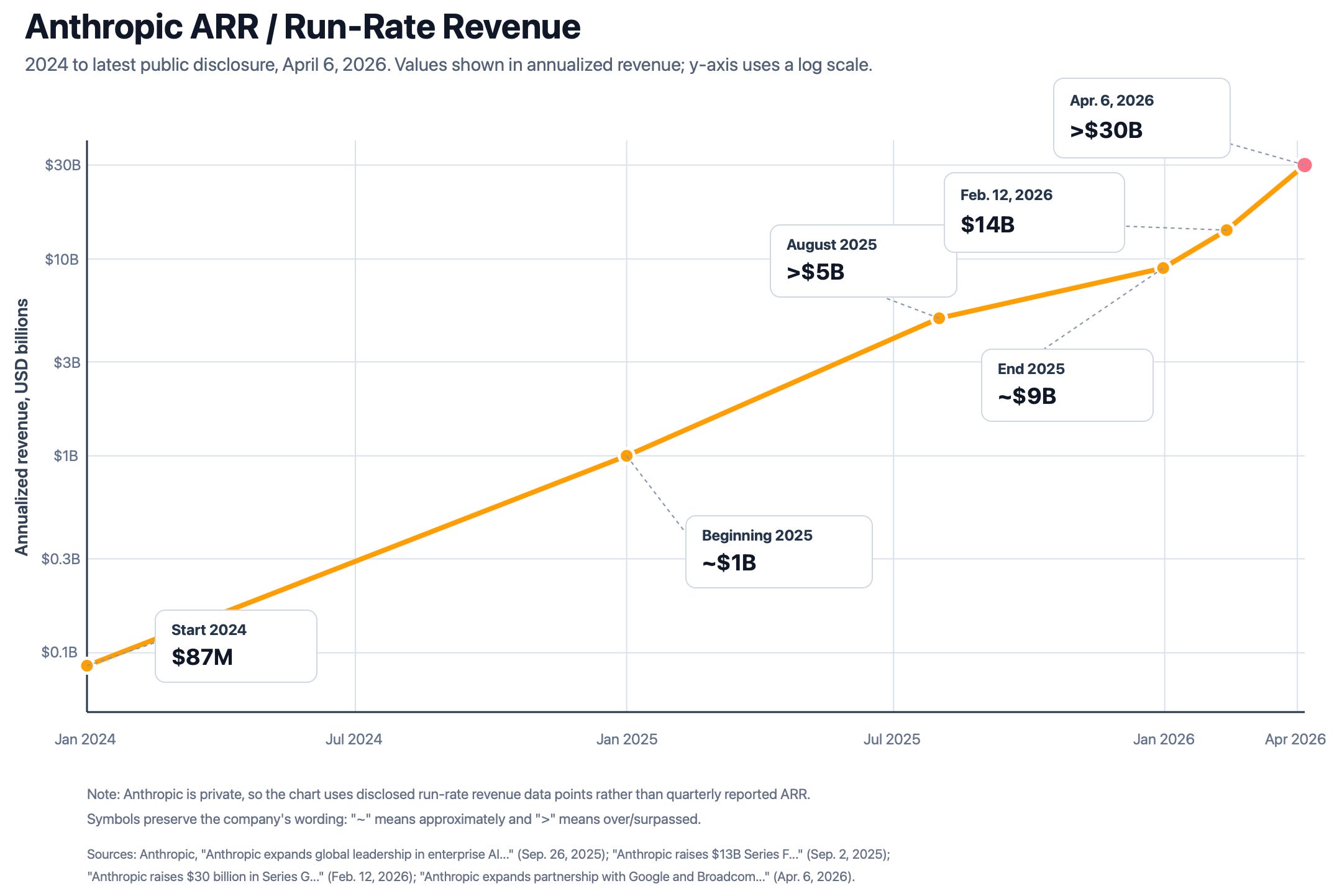
Obviously, the Pentagon declaring them a supply chain risk has supercharged their growth, which is probably the exact opposite of what someone would have expected if you had told them 2 years ago that, like ZTE and Huawei, a major US company would be blacklisted ¯\_(ツ)_/¯
Anthropic has clearly been suffering from a compute crunch. Their usage limits have long been SIGNIFICANTLY less generous than OpenAI’s, and that has just gotten worse lately, with time-of-use restrictions that make limits melt faster during peak time. 🧊
So, who has compute capacity to sell by the gigawatt right now?
Two days ago, Broadcom filed an 8-K:
Separately, Broadcom, Google and Anthropic PBC (“Anthropic”) have expanded their current strategic collaboration under which Anthropic, beginning in 2027, will access through Broadcom approximately 3.5 gigawatts as part of the multiple gigawatts of next generation TPU-based AI compute capacity committed by Anthropic.
This seems win-win-win.
Broadcom loves the big new customer. 💰
Google would ideally love to win it all directly with Gemini, but if they can’t, especially in the enterprise, they’d rather it be Anthropic that wins (they own about 14% of it) running on TPUs in GCP than OpenAI, probably running on Nvidia GPUs not on GCP (OpenAI also has compute deals with Google, but they’re not as close to them as Anthropic is). It also helps Google that OpenAI has to divert resources from consumer to the enterprise to compete with Claude.
Anthropic gets more compute and further diversifies, which may give it more leverage during its next negotiation round with Jensen. They also have a deal with AWS for Trainiums, and I wouldn’t be surprised to see them do something with AMD soon.
But it won’t come online soon enough to ease the current compute crunch, and with Mythos waiting in the wings… 🤔 (more on that in the next Edition)
🥇📋 Meta's Token Use Leaderboard (What could go wrong?) 🏆🤔
When I saw this, I immediately knew what was wrong with it:
The rankings, set up by a Meta employee on its intranet using company data, measure how many tokens—the units of data processed by AI models—employees are burning through. Dubbed “Claudeonomics” after the flagship product of AI startup Anthropic, the leaderboard aggregates AI usage from more than 85,000 Meta employees, listing the top 250 power users. [...]
Workers are maximizing their prompts, coding sessions and the number of agents working in parallel to climb internal rankings at Meta and other companies and demonstrate their value as AI automates functions such as coding.
Some people have reported hearing that token use is also part of employee performance reviews 🤔
Employees can track their personal consumption, compare themselves against colleagues and earn gamified rewards ranging from bronze, silver, gold, platinum and emerald badges to achievement titles, which also include “Model Connoisseur” and “Cache Wizard.” Some workers are instructing AI agents to carry out research for hours on end to maximize their token usage, according to two current employees.
Goodhart’s law:
“When a measure becomes a target, it ceases to be a good measure.”
Campbell’s law:
The more a quantitative indicator is used for decision-making, the more subject it is to corruption pressures, and the more it distorts the process it’s meant to monitor.
Over a recent 30-day period, total usage on the dashboard topped 60 trillion tokens… The highest-ranked individual user averaged 281 billion tokens, which could cost millions of dollars, depending on the type of model used.
60 trillion tokens a month puts Meta as one of Anthropic’s biggest customers, if not THE biggest.
It reminds me of measuring programmers by how many lines of code they produce 😬
The real thing you want is some technical or business outcome. You want better code, not more of it. If you reward quantity, you will encourage a lot of wasted tokens/compute, and more bloated/complex solutions to problems.
💳 Visa Launches AI Tools to Manage Charge Dispute Process
This isn’t as sexy as AGI headlines, but considering how much of the economy Visa touches, this is probably one of the largest-scale and most economically important real-world deployments of AI:
[Visa] announced six new dispute resolution tools designed to reduce the billions of dollars lost annually to inefficient, outdated dispute processes. The expanded suite of dispute resolution services is being designed to help merchants and financial institutions cut administrative costs, reduce fraud-related losses and redirect those resources toward growth, innovation and customer experience.
Disputes remain one of the most persistent friction points in commerce, driving rising costs for merchants and financial institutions while simultaneously leaving consumers frustrated and confused. In 2025, Visa processed 106 million disputes globally, a 35% increase since 2019. (Source)
I expect all financial players to have similar things (banks, insurance companies, etc).
I just hope it’ll work better for their customers than the incredibly annoying automated phone systems that leave you stranded the moment your case falls outside the decision tree.
💰💰⛰️💰💰 Berkshire Hathaway’s Cash Pile Mountain

Berkshire's market cap went from ~$15bn in 1991 to a trillion today. So naturally, the absolute cash pile has grown. But cash as a percentage of market cap has also been rising, which is more interesting (Brooklyn Investor has written great stuff about this).
But capital deployment takes place in absolute dollars, and clearly it has become harder to put money to work at high expected rates of return. Buffett has been quite clear on that.
Most of the other Trillion Club companies — except Apple, as we saw above — have been plowing their cash into AI capex lately (and it’s not yet clear what kind of ROIC they’ll get over time). If they weren’t doing that, they’d probably spend most of their FCF on buybacks and dividends.
Will Greg Abel be able (accidental pun) to figure out what to do with the mountain? ⛷️
📊 Moody’s and S&P: Wide Moats vs. AI Disruption 🤔
My friend David aka Scuttleblurb (check out our most recent annual interview) wrote good pieces about these two classic wide-moat companies and how they might face the new risks caused by AI. I recommend reading both, but I have a few highlights below:
Here are my highlights:
The durability of their credit ratings have less to do with the relative accuracy of default and loss assessments than by the role they play as a ubiquitously adopted benchmark across the financial ecosystem. A startup could conceivably use AI-powered algorithms to create a ratings methodology that was just as accurate and Moody’s and S&P’s would still remain entrenched.
A similar logic holds for S&P’s equity index business.
The network effect of standards is very hard to dislodge, especially when you save more by using the standard than by not using it (the old saw about rated debt being less expensive, so whatever you pay in fees, you get back in lower interest).
Speaking of debt:
The credit ratings business should be buoyed by several durable growth themes over the foreseeable future. Some $5tn of debt needs to be refinanced over the next four years, roughly double the dollar volume seen in 2018. The swelling stock of private credit will increasingly demand risk scores too, as regulators and investors press for comparability with public debt markets; Moody’s private credit ratings revenue grew 60% last year. Infrastructure funding, including AI data centers, supplies a further tailwind. Ratings revenue is lumpy and unpredictable year to year, but over extended periods has reliably tracked the high-single digit growth rate that management has long guided to. I don’t expect the future to look much different from the past.
🌊
I like the idea of not thinking about these companies as monoliths:
When thinking about S&P's data estate, I see a hierarchy of AI defensibility. At the top is data that you alone create and wouldn't exist without you, like a credit rating. Below that is data obtained through private sources, like the loan price data that S&P gets fed to it from dealers or shipping data sourced through bespoke commercial agreements. Further down still are curation activities – like entity matching and de-duplication, and data normalization – which I see as jobs that AI will eventually perform better and cheaper than any human team. I don't consider those capabilities a moat long-term. What does matter at that layer, however, particularly in compliance or regulatory driven domains, is governance infrastructure and SLAs. Where S&P controls the chokepoint, whether in the form of proprietary or near proprietary data or contractual assurances that clients cannot do without, AI should be a source of leverage rather than fear.
And finally, a devastating meta-observation coup de grâce:
I find it a bit absurd that we're entertaining the notion that a dominant global franchise like S&P is at risk of AI disruption even as we blithely labor under the delusion that we investment analysts will be safe.
😅
🧪🔬 Liberty Labs 🧬 🔭
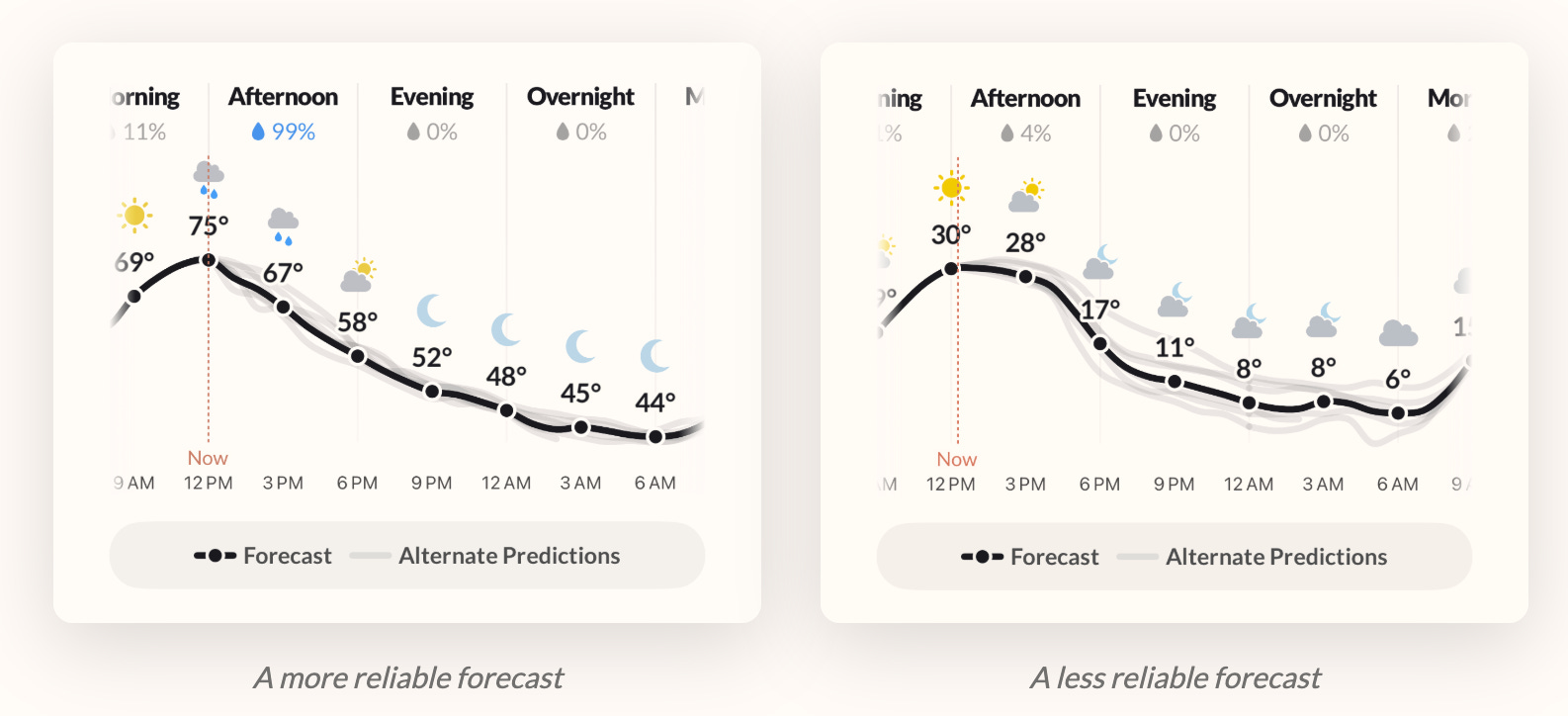
☔ Error Bars for Weather Predictions (Finally) 🌈☀️
My favorite weather app is still Mercury. It fits how my brain thinks about weather. The UX is just clean and well thought out.
But I gotta admit that this new feature from Acme Weather, which is made by some of the people who made Dark Sky weather before it was acquired by Apple, is really cool. Their weather line makes the forecast uncertainly visual by showing the spread widen or tighten depending on various factors.
It’ll take a lot to make me switch from Mercury, but I’ll give Acme a try.
🏴☠️🔓 Websites Can Show AI One Thing and Humans Another
Well, this isn’t great. A paper published by Google DeepMind details a vulnerability of AIs that feels obvious in retrospect, but hasn’t gotten nearly enough attention.
They identify six kinds of attacks:
Content Injection Traps that exploit the gap between human perception, machine parsing, and dynamic rendering
Semantic Manipulation Traps, which corrupt an agent’s reasoning and internal verification processes
Cognitive State Traps, which target an agent’s long-term memory, knowledge bases, and learned behavioural policies
Behavioural Control Traps, which hijack an agent’s capabilities to force unauthorised actions
Systemic Traps, which use agent interaction to create systemic failure
Human-in-the-Loop Traps, which exploit cognitive biases to influence a human overseer.
For example, the first one could be a website that embeds commands via CSS, HTML comments, or metadata attributes invisible to humans but parsed by agents. 👀
Or maybe a dynamic website that detects when the “reader” is an AI and serves it different content than when it’s a human, making it even harder to detect. It’s like a parallel reality that only AIs can see, or maybe only certain targeted AI clients to make it even harder to detect.
Hidden commands could take advantage of agentic workflows to spawn sub-agents that then go on to do the attacker’s bidding while the main agent appears to be doing just normal stuff.
Defenses will need to be hardened, but as usual, the defender needs to be right every time while the attacker only needs to get through once, so it’s an asymmetric combat dynamic.
👵🧑🦳 The Steady Rise of Maximum Life Expectancy Since 1840 📈
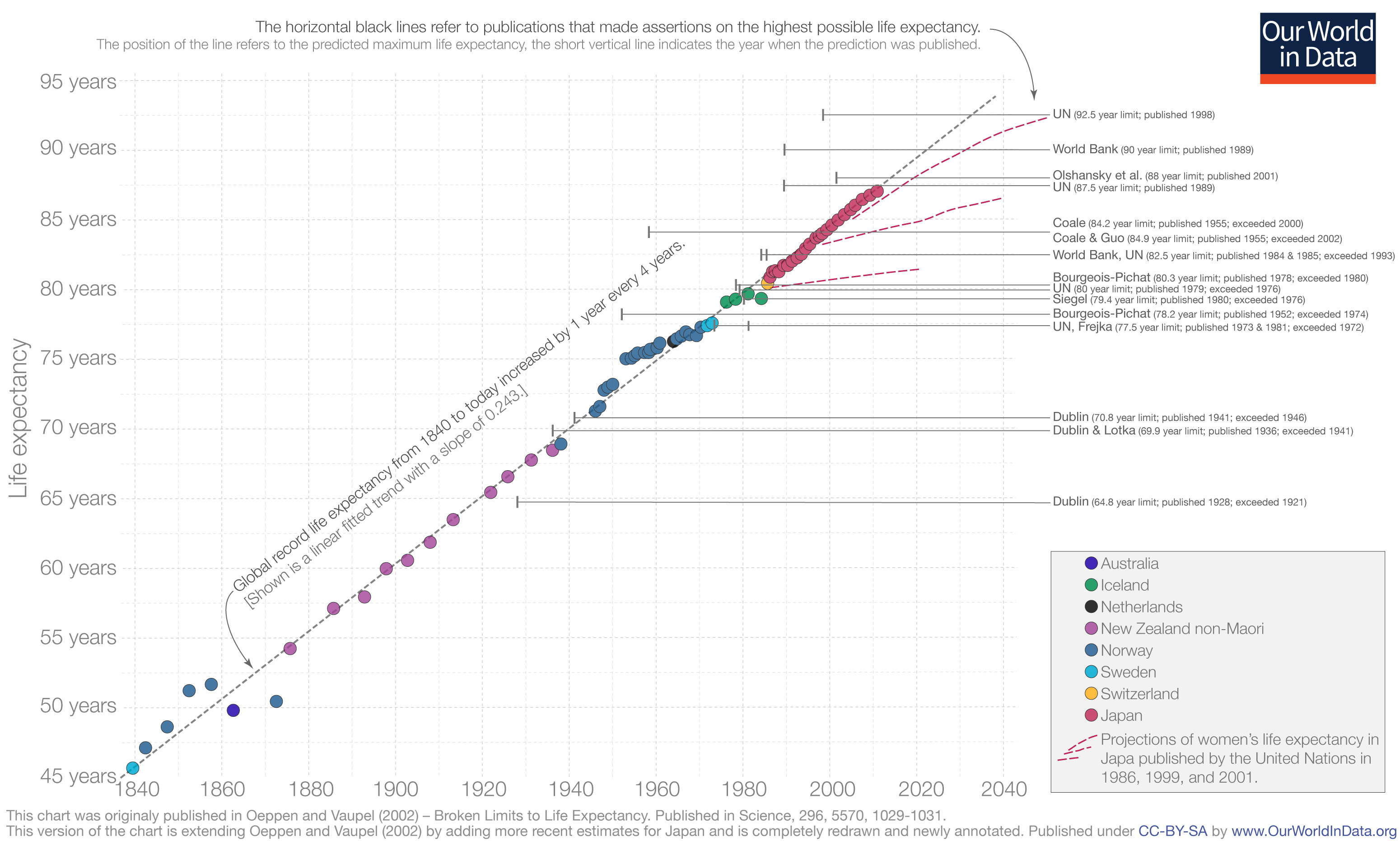
A lot of stuff has been stagnating (especially since 1971), but we gotta celebrate the wins too. 🥳
Experts have called the biological maximum multiple times since 1840. They've been wrong every time. Global record life expectancy has increased by 1 year every 4 years since 1840.
As you can see from the pink dotted lines, predictions have been exceeded multiple times (from 1986, 1999, 2001..). Let’s keep it going and accelerate it by curing the diseases of aging to extend robust health. But the goal isn't just to push the record higher, it's to broaden the base. More people living healthier for longer, not just record-setters
🦠 40 Years of Multiple Myeloma Cancer Survival Rate Improvements 🧫
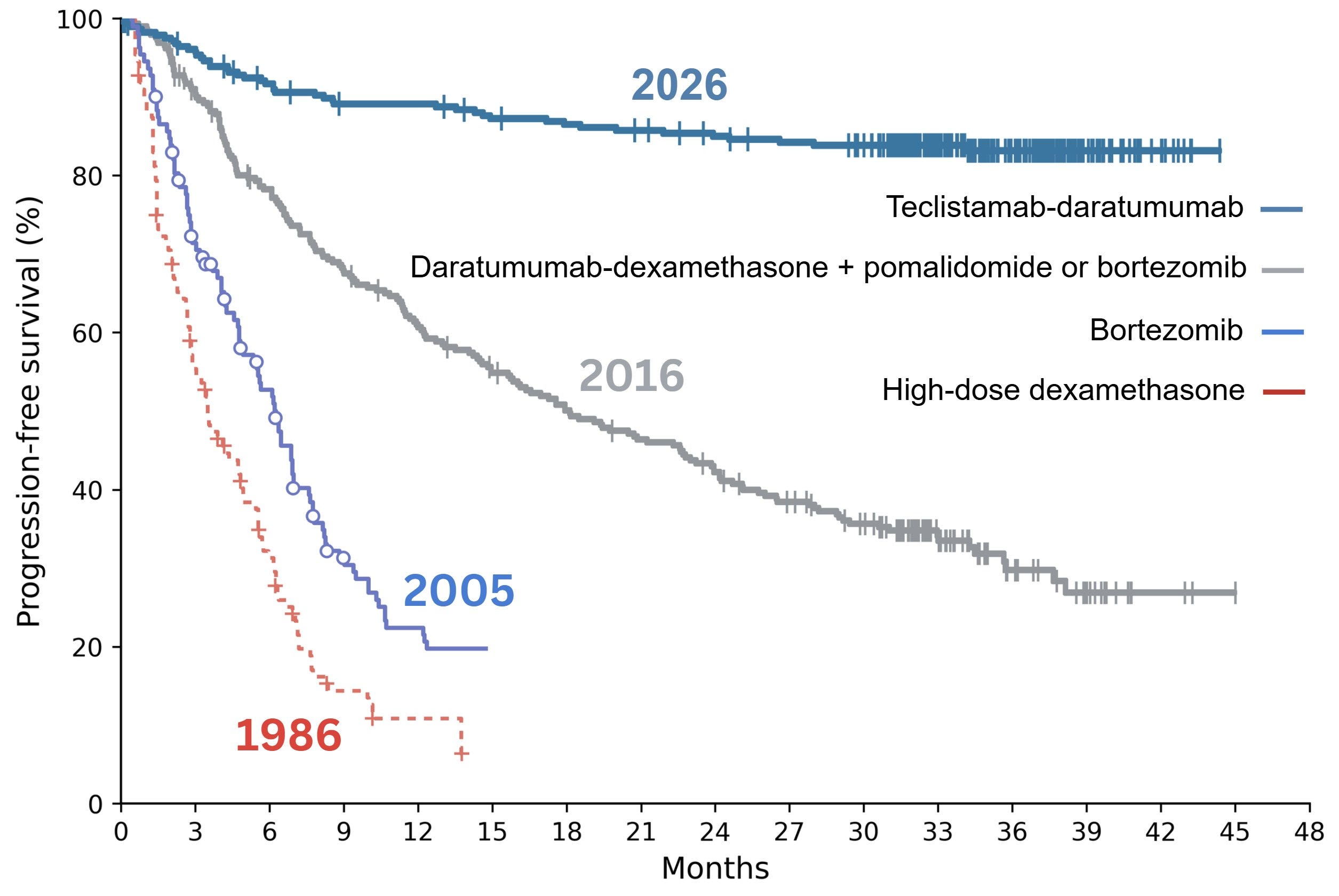
Speaking of celebrating victories, I love this graph.
It shows the survival duration in months for Multiple Myeloma over the past four decades. From less than 20% survival after a year in 1986 to more than 80% survival after three years today! Science FTW!
The Mayo Clinic describes it like this: “Multiple myeloma is a cancer that forms in a type of white blood cell called a plasma cell. Healthy plasma cells help fight infections by making proteins called antibodies. Antibodies find and attack germs. In multiple myeloma, cancerous plasma cells build up in bone marrow. In the bone marrow, the cancer cells crowd out healthy blood cells. Rather than make helpful antibodies, the cancer cells make proteins that don’t work right. This leads to complications of multiple myeloma.”
A different cancer, a similar story: The improvement for Stage 4 melanoma (stage 4 means that it has spread to other parts of the body) is also dramatic:

Remember that these aren’t just lines, they are people, and what happens to them affects a wider circle of family and loved ones.
h/t Dr. Samuel Hume
🎨 🎭 Liberty Studio 👩🎨 🎥
👨🚀🥔 Andy Weir in 2017: How I Became a Writer on the Side
Weir is the man of the hour, thanks to the success of the Project Hail Mary adaptation. He has an interesting and non-traditional path to success: A programmer by trade, he decided to publish his fiction online for free and built up a small but enthusiastic core fanbase over a decade+ before getting traction.
I like the “scratch your own itch” approach to being as scientifically accurate as possible in his fiction. Most people may not care, but the ones who do — they really do. And it makes him stand out since most other writers handwave most of that stuff.
It reminds me a bit of why I run this steamboat the way I do. I write the way I want to read, and hope that there are others like me out there who may find it hits the spot. To me, that’s a better approach than trying to imagine some theoretical audience out there and trying to guess what they may like. 🤔💭
The last part of this talk, where he talks about his involvement with the Martian’s film adaptation and what NASA and JPL subsequently did after he published, was really fun. I wish he would do a follow-up talk or podcast about his experience with Project Hail Mary’s adaptation.
h/t Friend-of-the-show Trung Phan
📙🔭 The Science of Not Giving Up 🚀
Speaking of Andy Weir, my friend Jameson just released part 1 of an episode of Becoming the Main Character on Project Hail Mary (the book).
I love the bit about better health. We won't know we are living in the golden age until after its gone.
Really like the content but such a big increase in one big swoop doesn't really take into account your readers wallets.