

634: The AWS Chipmaker IPO, Tokens Schmokens, Apple's TSMC Problem, Unreasonable Hospitality, YouTube's Terrible Parental Controls, Datacenters, Knife-Making, and Tricks to Fool You
"Some boxes are made from solid gold"

You cannot find peace by avoiding life.
—David Hare

🗓️😮💨 It’s funny: whatever time of year it is, my brain can always come up with reasons why life is ‘temporarily’ hectic… and then that season ends, and it’s something else.
Spring (🌱🌷🌧️🐦) is busy because there’s so much to do around the house. The pool, yard work, etc. And then there’s the kids’ birthdays, personal and corp taxes to file, and all that fun stuff.
Summer (☀️🌲🛶🔥) is crazy because the kids are out of school, family vacations, trips to my parents’ cottage (the photos above are from there), various social events, camp drop-offs and pickups, and holidays.
Don’t get me started on the Fall (🍂🍁🎃🥧). Back to school, yard work, and adjusting to shorter days, eternal darkness, and the cold — it always takes a bit of time. At our latitude in Canada, November feels like the darkest month. Once the snow comes, even if the days are technically shorter, at least things are brighter (and the Xmas lights help).
Winter! (☃️❄️🎄🎁) Well, forget about it. School breaks, flu season, holidays, snowstorms, family events, and travel. Very busy.
¯\_(ツ)_/¯
❤️🩹 📖 🛒 Dispatches from Grief by Danielle Crittenden is out on Infinite Books (also on Amazon). Mother’s Day is coming up 🎁
🔎📫💚 🥃 If you want it to continue, this is the moment. Become a paid supporter.
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Liberty Capital 💳 💴

🐜🔍 The AWS Chipmaker IPO? 🤔
When Amazon first started breaking out AWS’ numbers, Ben Thompson (💚 🥃 🎩) called it the ‘AWS IPO’.
Are we starting to see the AWS chipmaker IPO?
We don’t have the full picture yet, but Q1 gave us more details to paint the outline. Andy Jassy had this riff on the most recent earnings call about this gigantic business hosted inside of Amazon:
Andy Jassy: Our chips business continues to grow rapidly and is larger than what a lot of folks thought.
We saw nearly 40% quarter-over-quarter growth in Q1, and our annual revenue run rate is now over $20 billion and growing triple-digit percentages year-over-year, but this somewhat masks the size.
If our chips business was a stand-alone business and sold chips produced this year to AWS and other third parties as other leading chip companies do, our annual revenue run rate would be $50 billion. As best as we can tell, our custom silicon business is now one of the top 3 data center chip businesses in the world, the speed at which we’ve gotten here is extraordinary. And we have momentum.
Clearly, any viable source of compute is getting sold out. That’s just the reality of the tidal wave of demand. 🌊
How well would Trainiums and Gravitons do in a more normal market where customers evaluate each option on its merit, rather than take all they can get, almost regardless of price or performance?
¯\_(ツ)_/¯
Amazon has enough workloads that could be run on its own chips that they probably would be a great asset in any case (eg. they run a lot of the software that they sell on their own chips, and customers don’t have to know that their database runs on Gravitons instead of AMD CPUs).
BUT
Let’s imagine a world where Anthropic isn’t so compute-constrained that their uptime chart looks like an autumn forest painting. Let’s also imagine that they have internal cashflows that they can use to pay for compute, and they don’t have to raise billions from hyperscalers like Google and Amazon that bundle use of their chips in the deal.
Would they still use gigawatts and gigawatts of Trainiums and TPUs, or would a bigger share go to Nvidia because the performance/$ or perf/watt is better?
I don't know, but looking at the incentives, my guess is yes, more would flow to Nvidia.
For our custom AI silicon, we’ve recently shared very large multiyear, multi-gigawatt Trainium commitments from the 2 leading AI labs in the world in Anthropic and OpenAI as well as an increasing number of companies like Uber betting on Trainium.
And we now have over $225 billion in revenue commitments for Trainium. Our Trainium 2 chip has about 30% better price performance than comparable GPUs and is largely sold out. Trainium 3, which just started shipping at the start of 2026 and is 30% to 40% more price performance than Trainium2 is nearly fully subscribed. And much of Trainium 4, which is still about 18 months from broad availability has already been reserved.
These are big bucks, but on the performance numbers, I can’t help but see the 30-40% improvements in price-performance as being a little low compared to the generation-over-generation improvements we’re seeing from Nvidia 🤔
(Nvidia claims roughly 2x performance/$ from Hopper to Blackwell for training, and the inference numbers are even more dramatic at rack scale, when you take into account the whole system that includes networking, software optimizations, etc.)
We also just announced that Meta is committed to using tens of millions of Graviton cores. Graviton is our industry-leading CPU chip, which allows Meta to run the CPU-intensive workloads behind agentic AI with the performance and efficiency they need at their scale. AI is commonly seen as a GPU story, but the rise of agentic workloads, real-time reasoning, code generation, reinforcement learning and multistep task orchestration is driving massive CPU demand as well. As AI systems shift from answering questions to taking actions and as post-training and inference scale up, the compute required pulls heavily on CPUs. That’s why Meta chose Graviton, which delivers up to 40% better price performance than any other x86 processors and now used by 98% of the top 1,000 EC2 customers.
Meta is truly the compute swing voter. They’ll use everything!
Nobody has a better set of chips across AI and CPU workloads than AWS with Trainium and Graviton, and we’re unusually well positioned for this AI inflection we’re in the early stages of experiencing.
He goes on to say that their partnership with Nvidia is also very important (and clearly it is).
But their ROIC will increasingly depend on their own silicon efforts. The key challenge: steering the big labs to get to a critical mass on their chips so they get past the friction of porting their stuff over AND so that AWS can get to a scale that allows their chips to be viable contenders and more attractive to other potential customers too. Or to go to the overused metaphor: Get that flywheel spinning faster.
Tokens Schmokens: We Need a Better Economic Unit of AI Work 🤔
Usage-based pricing measured in tokens is problematic because tokens are not a stable unit of anything, as I wrote about in Edition #630.
They’re not like kilowatts or gallons of gasoline.
And paying by the token creates perverse incentives for labs to slice the pizza into more slices. 🍕
By that I mean that the way models convert text and data into tokens is not a fixed process that is the same everywhere. Different models can have different tokenizers that will parse the same source into more or fewer tokens.
My friend MBI (🇧🇩🇺🇸) had this great metaphor:
It’s like two movers quoting you a rate per box. Mover A quotes you $10 per box but uses large boxes. On the other hand, Mover B charges you $8 per box, but uses small boxes. [...]
As you can see, tokenization is a non-transparent billing unit that each vendor controls unilaterally. If a provider bills for hidden reasoning or other opaque internal operations, the customer may be paying for a large share of compute they cannot directly observe or verify.
But the size of the box isn’t the only variable. Some boxes are made from solid gold and others from paper-thin recycled cardboard.
A token generated by a tiny model, from a simple query with minimal context, can be extremely cheap to generate. The small model can run on old GPUs, use little RAM, and the answer can be one-shotted quickly.
But a token generated by the largest model out there, on a very complex query with a huge amount of context (Dr. Evil voice: 1 million tokens!) can be a seriously expensive token that can only come from a beefy modern GPU with lots of scarce high-bandwidth RAM.
Add to that how many more tokens per query you get now that models are reasoning and agentic, and the cost variability compounds. And you have very different incentives with flat rates and usage-based billing.
For a flat rate, the lab is probably incentivized to generate fewer tokens, to spend less time reasoning, do fewer tool calls, and to load fewer sources (which increases context and thus cost, etc). 🗜️
But if you’re paying by the token, the lab has an incentive to have the model work for a long time, load a lot of data in context, and generate a lot of reasoning tokens because that will result in more revenue. 💰💰💰
It seems like tokens as a unit of work are not tenable for much longer, because it’s impossible to know what you’re talking about when you say “10,000 tokens” unless you add a lot of context.
Maybe the labs like it that way. It makes it easier to obscure things and pull levers to increase margins and revenue. 📈
But those who are spending billions on AI will probably push for a more transparent unit of work, a ‘slice of intelligence’ (🧠). Something that embeds all the variables I mentioned above into a clear number. For more vertical applications, outcome-based pricing may work (like how digital advertising tracks sales), but the labs are too horizontal and general for that.
I’m not sure what exactly that looks like. It’s tough to normalize when not everybody pays the same for GPUs, ASICs have very different performance profiles, electricity costs vary, and comparing across GPU generations isn’t just about FLOPs but also networking and scaling out. But maybe someone smarter than I am can figure something out that works well enough to be worth adopting.
Update: After I wrote the above, Ben Thompson (💚 🥃 🎩) published an interview where Sam Altman says the following:
Do you think we stick with pricing as far as — pricing is based on tokens, does that make sense in the long run?
SA: No. And in fact, like there was an interesting example of this with our model that just came out, 5.5. where the per-token cost is much higher than 5.4, but it requires a hugely fewer number of tokens to get the same answer, and you actually don’t care about how many tokens the answer takes, you just want the piece of work done, and you want again a price and an amount of capacity you can have for that.
So maybe I was wrong to say “token factory”, but we’re like an intelligence factory or something. We just want as many units of intelligence for the lowest price and whether that is a bigger model running fewer tokens, a smaller model running lots of tokens, whether a GPU or Trainium or something else, whether we do any of the other kind of number of things we could do about that creatively, I don’t think customers care.
So Altman agrees tokens are the wrong unit. The hard part is figuring out what comes next.
🍎 Apple Shops for a Second Chipmaker, Looks at Intel and Samsung U.S. Fabs 🐜🇺🇸
Apple Inc. has held exploratory discussions about using Intel Corp. and Samsung Electronics Co. to produce the main processors for its devices in the US, a move that would offer a secondary option beyond longtime partner Taiwan Semiconductor Manufacturing Co. [...]
Neither effort has resulted in any orders so far, and the work with both suppliers remains preliminary, according to the people, who asked not to be identified because the talks are private. Apple has concerns about using non-TSMC technology and may not ultimately move forward with another partner, the people added.
This last part is not nothing.
But Apple is already feeling the capacity squeeze: Tim Cook said on last week's earnings call that they have less supply chain flexibility than normal, largely because AI datacenter buildouts are eating TSMC capacity.
While on paper it’s amazing to have a second-source, especially one in the U.S., in practice what matters most is that iPhones are as good as they can be and that everything runs like clockwork. The annual release cadence is brutal, there’s little margin for error, and the scale required is large. 🏭→📱📱📱📱📱📱
The last thing Apple wants is delays, chips that don’t perform well, or dual-sourcing and having some iPhones or Macs with the “good chips” while the others have inferior ones. They had this exact problem when they dual-sourced LTE modems from Qualcomm and Intel during the iPhone 7 era. The Qualcomm modem was so much better that Apple actually throttled it down to match Intel's performance, so all iPhones would be the same. 😅
It wasn’t the end of the world, but I think it would be a bigger deal with the SoC, the package that includes the CPU + GPU + XPU (RAM is on the same package, though not same die).
Maybe the place to start would be a lower volume product, like some Mac chip 🤔
But even that could be a gamble. On the other hand, if they don’t start to find other suppliers now, if anything ever disrupts TSMC operations (I’m looking at you, China 👀)… yikes
🗣️ Will Guidara: Transferable Lessons from Hospitality 🍽️🌭
I enjoyed this one so much. Will’s voice and stories were like ASMR tickling my brain just the right way. 💆♂️
A lot of the wisdom he shares about hospitality applies to other jobs and aspects of life, but most people probably never think to make the transfer.
The anecdotes are great: the hot dogs served at Eleven Madison Park, a Michelin star restaurant, or the UPS store that requires employees to comp one customer’s order per day, or the pilot who gives tours of the cockpit to passengers when there’s a delay. I should do more of this kind of stuff in my life 🤔
Q: What are some of the other most unreasonable things that you’ve ever done for a guest?
Will Guidara: Oh my gosh, we did so many crazy things. One of my favorites is there was a family of four from Spain dining with us, parents and their children. We had these big windows. It started snowing. We learned that it was the kids’ first time seeing real snow. [We] somehow found a store still open at 8 o’clock on a Friday night selling sleds. And when they left the restaurant, we had an Uber SUV parked out front with sleds in the back [and] a big thermos of hot chocolate in the front.
Beautiful! 🛷
Here’s the UPS store one:
Will Guidara: This is something I learned from a guy who read my book and was inspired by it and tried to figure out a way to put it to work in his world, but his world is very different from the one I came from. He owns two UPS stores in Sarasota, Florida, which are not the places anyone would immediately think of as being the most hospitable in the world.
But he wanted to figure out how to put this into practice. And so he came up with an idea and he shared it with me because he said it transformed his entire culture. He made a rule that everyone that worked for him that worked, that worked the register, they were required to once a day, one time during their shift, comp someone’s order up to whatever, 30 bucks. That one change transformed the culture of his stores.
And it was a win, win, win.
It was a win for the person on the receiving end. Imagine if you went to a UPS store to like send something to your mom and they’re like, sir, it’s on us today. You’d be like, what the fuck is going on? It would blow your mind. And you would talk about that. Like, you’d be like, dude, the weirdest thing happened. I was at the UPS store.
It was a win for the people that worked there. Because, listen, I don’t care what you do. I don’t believe you can do it well if you don’t feel some level of genuine appreciation for doing it. […] the people that worked there, when they did comp someone, they’re like, oh my gosh, they really appreciated that. This feels great.
That’s what led to the third one. Because when he implemented the rule, they were required to do that. But after they started feeling that level of appreciation, now they were allowed to do it. But only one time a day. Which meant they had to now work to more deeply understand everyone that walked through the doors of that store to decide who deserved it the most.
Was it someone having a good day that needed a cherry on top? Was it someone having a bad day that needed something to go right? Every customer was receiving better service and hospitality in pursuit of figuring out who was going to get that one gift.
Such a clever incentive!
I bet it made the store perform so much better in all kinds of other metrics too, because once you have engaged employees who are paying attention, everything will improve 📦📦📦

If you’ve seen the TV show ‘The Bear’, a lot of what he says reminds me of my favorite episode, ‘Forks’.
🧪🔬 Liberty Labs 🧬 🔭
📺 Steel to Blade: Irish Knife Maker Fingal Ferguson 🇮🇪
This is a neat sub-10-minute mini-documentary that was produced by Stripe.
The theme of the series is tacit knowledge, something that I discussed with my friend Cedric Chin on this podcast. In fact, Stripe cites Cedric as inspiration for this series!
But regardless of high-concept ideas, it’s just really fun to watch a master craftsman turn an undifferentiated piece of steel into a beautiful artifact. 🪨→🔪
🔌 Global AI & Datacenter Electricity Consumption: Unevenly Spread ⚡
Hannah Ritchie looked into the latest available numbers (2025), and sliced and diced them all kinds of interesting ways. Here are my highlights:
Global data center electricity use is only about 1.5% of the total. But the U.S. is the epicenter of AI, hyperscalers, and the Internet generally, so the share there is much higher:
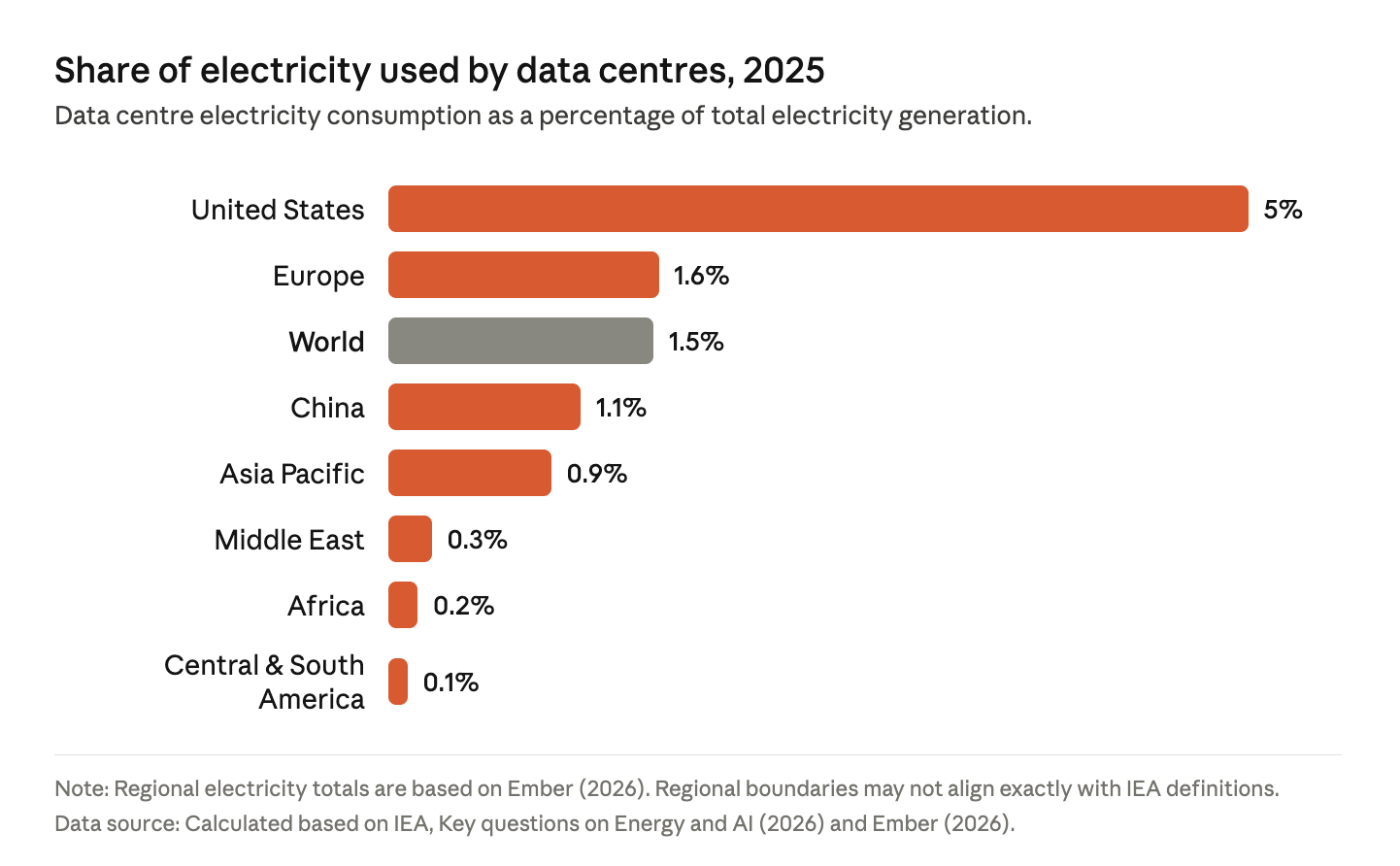
But even those numbers hide regions where the % are much higher:
this demand is even more locally concentrated. Beneath Europe’s 1.6% figure, we have Ireland, where data centres account for more than 20% of its electricity consumption. Beneath the 5% US figure, there are a number of states where data centres make up more than 10% of demand, and in states such as Virginia, it’s more than [25%].
The U.S. share of new electricity demand is growing much faster than elsewhere:
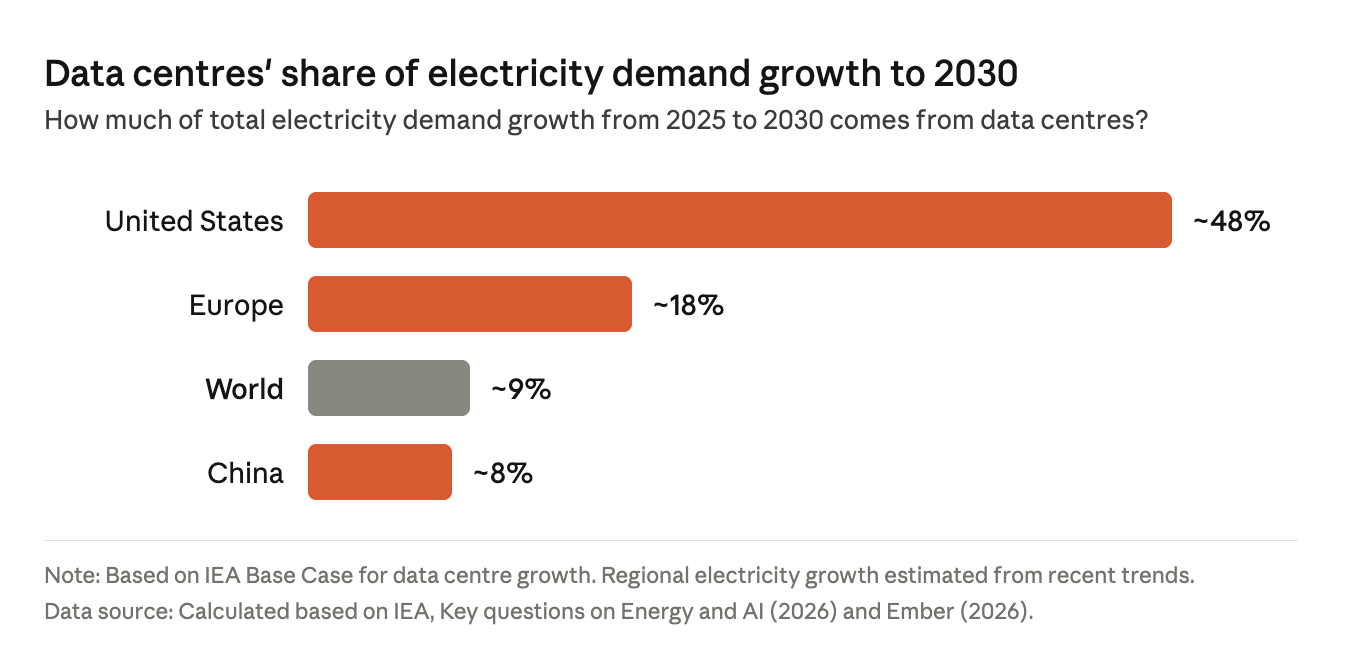
But these numbers also hide other factors. The share in the U.S. is so much higher in part because data-center growth is expected to be very high, but also because other sources of electricity demand are expected to grow more slowly than elsewhere.
Like what?
Well, EVs are not growing as fast in the US as in China, and A/C is already very common in the U.S. while it’s growing faster elsewhere. 🔌🚘🔋
Last one, the difference in energy use between typical one-shot LLM queries and longer-running agentic workflows:
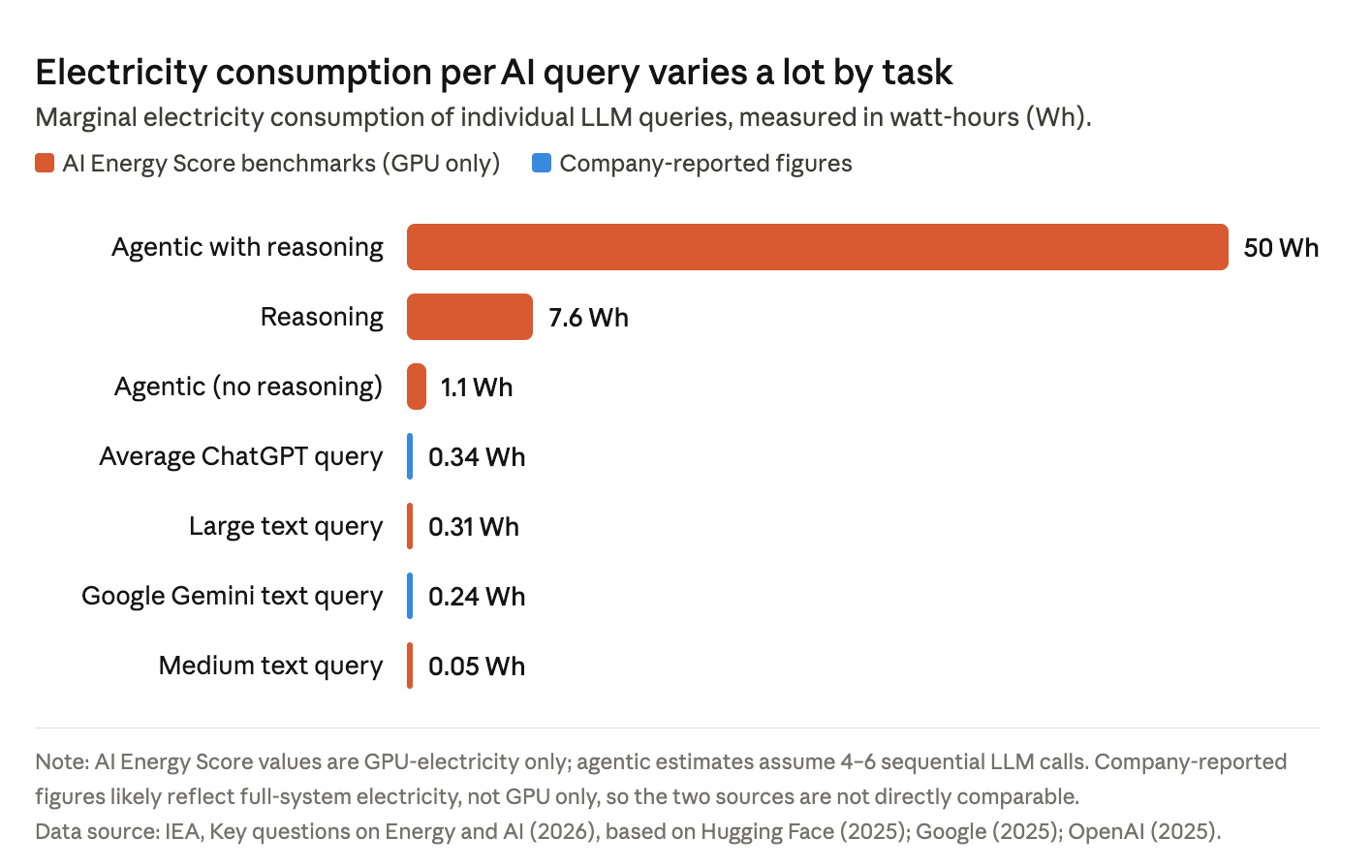
But this is in constant flux, so don’t take those numbers too literally. The software gets optimized, more efficient GPUs come out… But also, new workflows and capabilities come out that make users generate way more tokens. So there’s a push and a pull. ↔️
What matters more is probably the general orders of magnitude.
Check out Hannah’s full post for more details.
📺 😠 Google’s Terrible YouTube Parental Controls

You’d think a company as technically competent as Google would be able to create parental controls that work on one of their flagship platforms (YouTube), but that doesn’t seem to be the case.
My oldest son doesn’t have a phone or tablet yet, but he watches YouTube on a TV. In the past, it’s mostly been Minecraft and Zelda videos, but in recent times, YouTube has been pushing more short-form videos on him in all kinds of ways.
We’ve discussed it, and I’ve encouraged him to stick to more substantive things (even if they’re just entertainment), and he agrees. But these things are very engaging (that’s their whole point), and once you start, it can be hard to stop (just one more!).
So recently, when I saw that a new parental control setting had been added by Google to allow shorts to be time-limited or even set to zero minutes per day, I discussed it with my son. I expected us to figure out what a reasonable limit per day would be (15 minutes?), but he asked me to set it to zero. I was surprised, but happy that he had the introspection to realize that he wasn’t getting much out of these things, even if they were hard to resist.
WELL
That was a very nice theory, wasn’t it?
I set the limit to zero. I set it to 15 minutes. Doesn’t matter, it doesn’t work. 💣
Apparently, Google’s ‘Family Link’ parental controls are so broken that they work on some platforms and not others. On our smart TV and in the browser on a Macbook Air, *both* logged into my son's YouTube account, these controls do absolutely nothing.
I don’t even know where they work at this point. Only on Android? Come on, Google, you have hundreds of millions of users that aren’t on Android.
This is so stupid. Don’t people at Google even test these things? Or at least make it very clear on the settings page what the limits are, and don’t bury it in the small print.
How many parents like me are using parental controls, thinking they just did something, but they never go check, and things simply don’t work.
You can also try to set limits using other methods, like Apple’s ScreenTime, but that only works on macOS and iOS, not on a TV’s YouTube app, and it’s not as granular as allowing YouTube but not YT Shorts.
You’d think that maybe you could go into the TV’s YouTube app settings to tune things the way you want them, but nope, there’s almost nothing useful in there.
You can try to nudge the YouTube frontpage algo by hitting “show me less like this” and “not interested”, but shorts always come back.
Don’t you dogfood your own products, Google? Don’t your engineers have kids that aren’t on Android devices?!
🎨 🎭 Liberty Studio 👩🎨 🎥
How to Cheat at… Guitar?! (The Tricks that Fool You) 🏴☠️🎸
Wow, I had no idea some people were that sophisticated at pretending they’re great guitarists. I suppose that since there’s a lot of attention and money involved in getting engagement on YouTube, it was bound to happen.
I love how the video goes through various levels of cheating, from pretty benign to full-blown AI persona. The tricks of the trade to subconsciously convince you that something is real (like the visible laptop recording, the clock running in the background, etc) are clever.
But once you know what to look for, you’ll be a more skeptical viewer (not just for guitar videos, but for anything else online). 🧐 🤨

hi, speaking about blades... my son in law is also doing some stuff. Feel free to check https://www.youtube.com/watch?v=-2HIvmvB7So :)
There’s a typo in the text of your graphic. The part about YouTube should read: “YouTube’s Terrible”.