

639: Nvidia's Q1, TSMC as the Accidental Central Bank of AI, Jensen Wants the CPU Market Too, Anthropic’s CFO Krishna Rao, Gavin Baker, Jane Street, Cloudflare + Mythos, Drone Wars, and Apollo 13
"if we don't get a bubble, we need to throw a party for them"

You can get far in life just by being extremely curious.
Passionate inquisition will lead you down paths most people never take & are completely unaware of.
You can be most well rounded experienced person you know just by being curious.
“Interested people live Interesting lives.”
—Brother Lobo

🧍⌨️🖥️ I wanted to show you my standing desk, so I took a photo and had AI redraw it (to anonymize it). And yes, I’m standing as I’m typing this.
Years ago, I read about the benefits of standing desks and figured I’d try.
My prototype was simply stacking a bunch of boxes on my desk to raise my monitor and keyboard to standing height. I tried a few days and liked it, so I bought a used IKEA Fredrik desk for $30. Some online forums recommended it as a cheap way to go standing.
The desk wasn’t designed to be standing, but because it had those top shelves and side posts with holes every few inches, you could mount the desk surface to standing height.
I used that as my main desk for a few years and got used to standing while working, and walking around the office as soon as I had something to think about. But then in 2014, my wife and I had our first kid, and oh boy, he didn’t sleep very well for 18 months.
Survival mode. I went back to a sitting desk 🥱
That situation got better… then we had our second boy, and he had the same sleeping genes. So I didn’t go back to standing, and inertia being what it is, I’ve been sitting ever since.
But during that decade, standing desks got WAY more popular. Many motorized models came on the market, and I started thinking about going back, but this time with a hybrid that could do both.
I bought a motorized frame from MotionGrey (on sale around $300CAD), and I asked a friend who’s great at woodworking if he could make me a hardwood top (👋 Fred! Thanks again 💚 🥃). He suggested a few possibilities, and we ended up going with white oak (it’s beautiful).
I’ve not been using it for that long (my wife can attest to how slow I’ve been to assemble it, even after the frame and top arrived). But I have to say: It’s a real quality-of-life improvement.
Without having to force myself, I end up working standing up at least 2-3 hours per day on average, and over the years and decades, I think that will add up to all kinds of benefits.
If you spend your day at a desk and haven’t got a standing desk yet, I recommend it. And if you have young kids, get a motorized one. Fixed-height is a commitment you may come to regret at stupid o'clock.
🔎📫💚 🥃 If you want Liberty’s Highlights to continue, this is the moment. Become a paid supporter.
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Liberty Capital 💳 💴

🏭🤖 Nvidia Q1 Highlights: Compute Is Revenue, Demand Goes Parabolic, and Jensen Wants the CPU Market Too 😎
Humans get used to things really quickly. I was watching Apollo 13 with my family last weekend (🚀🧑🚀🧑🚀🧑🚀). One of the plot points is that Apollo 11 (first time on the moon) had the whole world watching, but by Apollo 13, going to the moon had become seemingly so routine to most people that the major TV networks didn’t even bother carrying the crew's live broadcast. 😅
Sometimes it feels like this with Nvidia.
They have some of the best quarters any public company has ever had, and everybody goes 🥱 and takes it all for granted. I don’t necessarily mean that the stock should have moved more, because that’s the expectations game (yes, they beat “consensus”, but in the Keynesian beauty contest, beating consensus is itself the consensus, so it’s not really a beat 🔁). Mr. Market is clearly skeptical of the duration of growth (🤨).
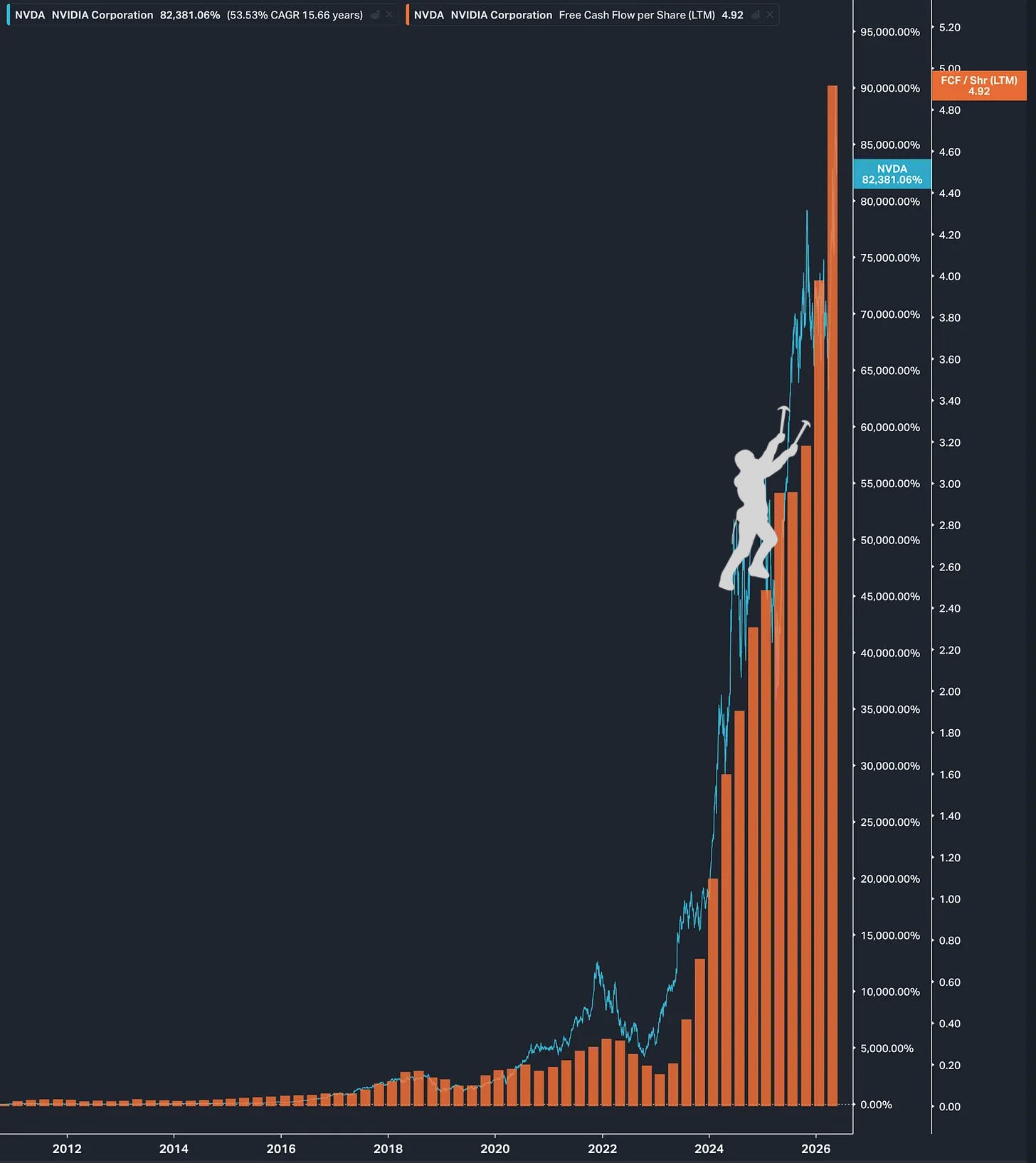
But we’ve become blasé about these numbers very quickly.
85% revenue growth at that scale, selling physical products!
Jensen described it this way: “This was an extraordinary quarter, demand has gone parabolic.”
For comparison, the last time Google grew revenues at that pace was in Q4 of 2005. But at the time, its market cap was $120bn, not $5.2 trillion.
And Google’s gross margin back then was ~60%. That’s a purely digital business (at the time), vs Nvidia’s 75% gross margins, and they ship metal.
Nvidia’s net income was $58.3bn in Q1, up 211% year-on-year 🤯 (GAAP, which includes $15.9bn of gains from equity securities, to be fair)
For most of its 33-year history, Nvidia was a gaming company. Now it doesn’t even report gaming separately. 🎮
They lumped everything that isn’t “Data Center” into “Edge Computing”, and all of it added up to $6.4bn last quarter compared to $75.2bn for DC. One big downside of that, IMO, is that networking isn’t broken out as a segment anymore. It’s now part of DC, which is too bad, though we did get specifics in the CFO commentary:
“Networking revenue was a record $14.8 billion, up 199% from a year ago and up 35% sequentially.” 🛜
Let’s dive into management’s commentary to see what’s going on underneath those numbers:
One thing they try to do is convince the market that they’re not only selling to a handful of hyperscalers. They will report two segments within DC, with the hyperscalers on one side, and what they call ACIE on the other (AI Clouds, Industrial, Enterprise, which also bundles in sovereign, on-prem, and any odds and ends):
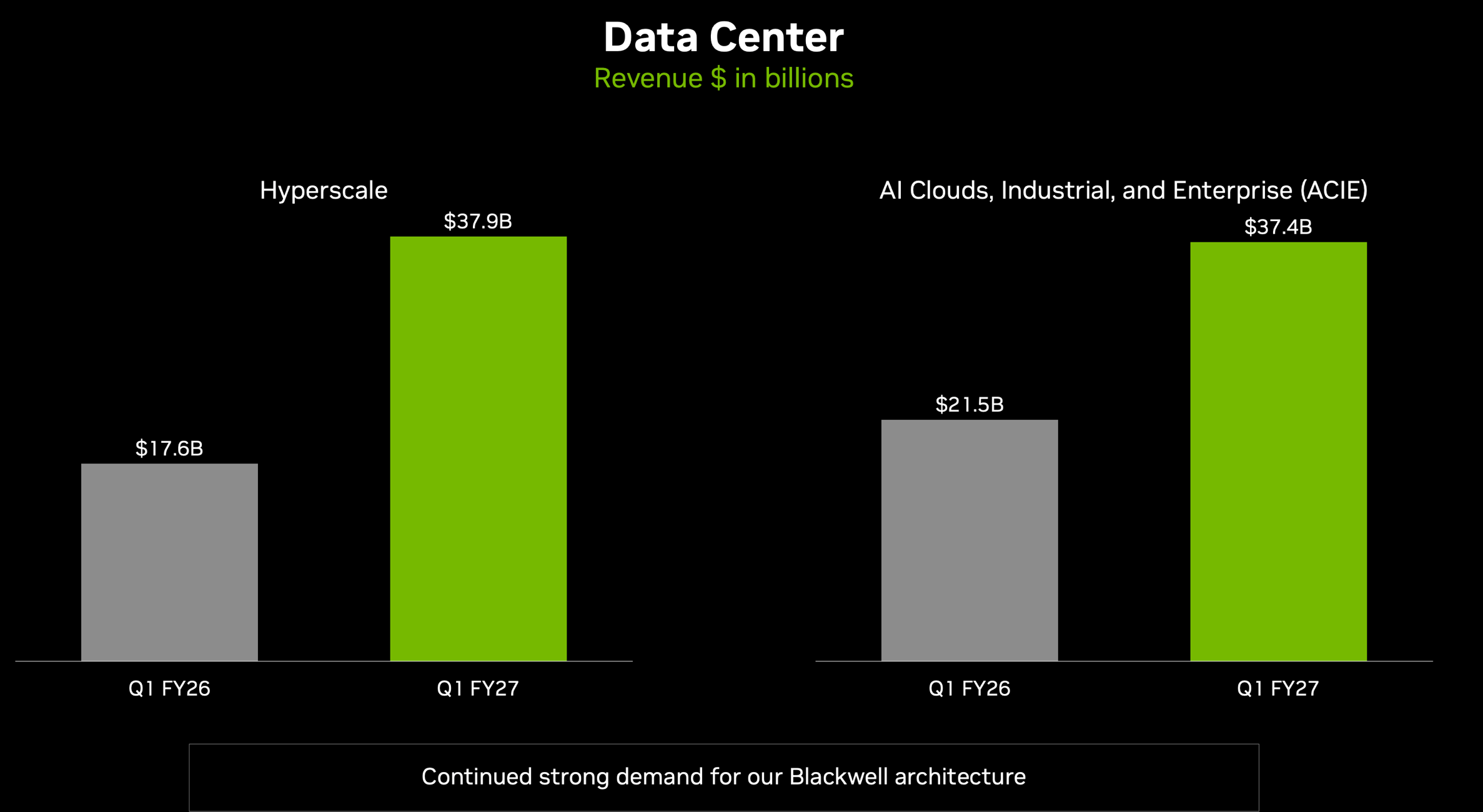
Colette Kress (CFO): Hyperscale revenue of $38 billion was approximately 50% of Data Center revenue and increased 12% quarter-over-quarter.
ACIE revenue was $37 billion and grew 31% quarter-over-quarter, including AI cloud revenue that more than tripled year-over-year. Our customers have enabled rapid stand-up of AI compute capacity.
The number of partner data centers exceeding 10 megawatts has nearly doubled in just 1 year, now surpassing 80 sites.
Sovereign revenue increased more than 80% year-over-year.
Hyperscale grew 115% YoY, faster than ACIE's 74%. Doesn’t quite fit the "hyperscaler AI spend is maturing" narrative. In fact, hyperscalers are accelerating faster than the new diversified base Nvidia is trying to highlight.
Kress also made a pitch against the 'Nvidia is more expensive' refrain:
Today’s data centers are revenue-generating AI factories […] Customers do not buy GPUs. They build AI factories and the right economic metric is not the purchase price of the GPU. It is the lifetime cost of an AI factory producing intelligence, token per watt, tokens per dollar, uptime, utilization, time to production, software durability and asset life.
Constrained by power and capital, AI factory operators must choose the right architecture. With our extreme codesign approach, we deliver the industry’s lowest token cost, the highest token throughput and the highest ROI. MLPerf Inference results are in, and once again, we swept every benchmark as Blackwell Ultra delivered the highest throughput across the broad set of models and deployment scenarios.
Full stack innovations drove the 2.7x increase in throughput and a 60% reduction in the cost per token on GB300 compared to just 6 months ago.
That's the moat many people miss. Even if you catch up to last quarter's Blackwell, this quarter's Blackwell is 2.7x faster on the same chips. Software optimizations ftw.
They also announced a “deepened” partnership with Anthropic, but I'm unclear what that actually means. I’m guessing they sweetened their offers to them to pull them away from TPUs and Trainiums a bit ¯\_(ツ)_/¯
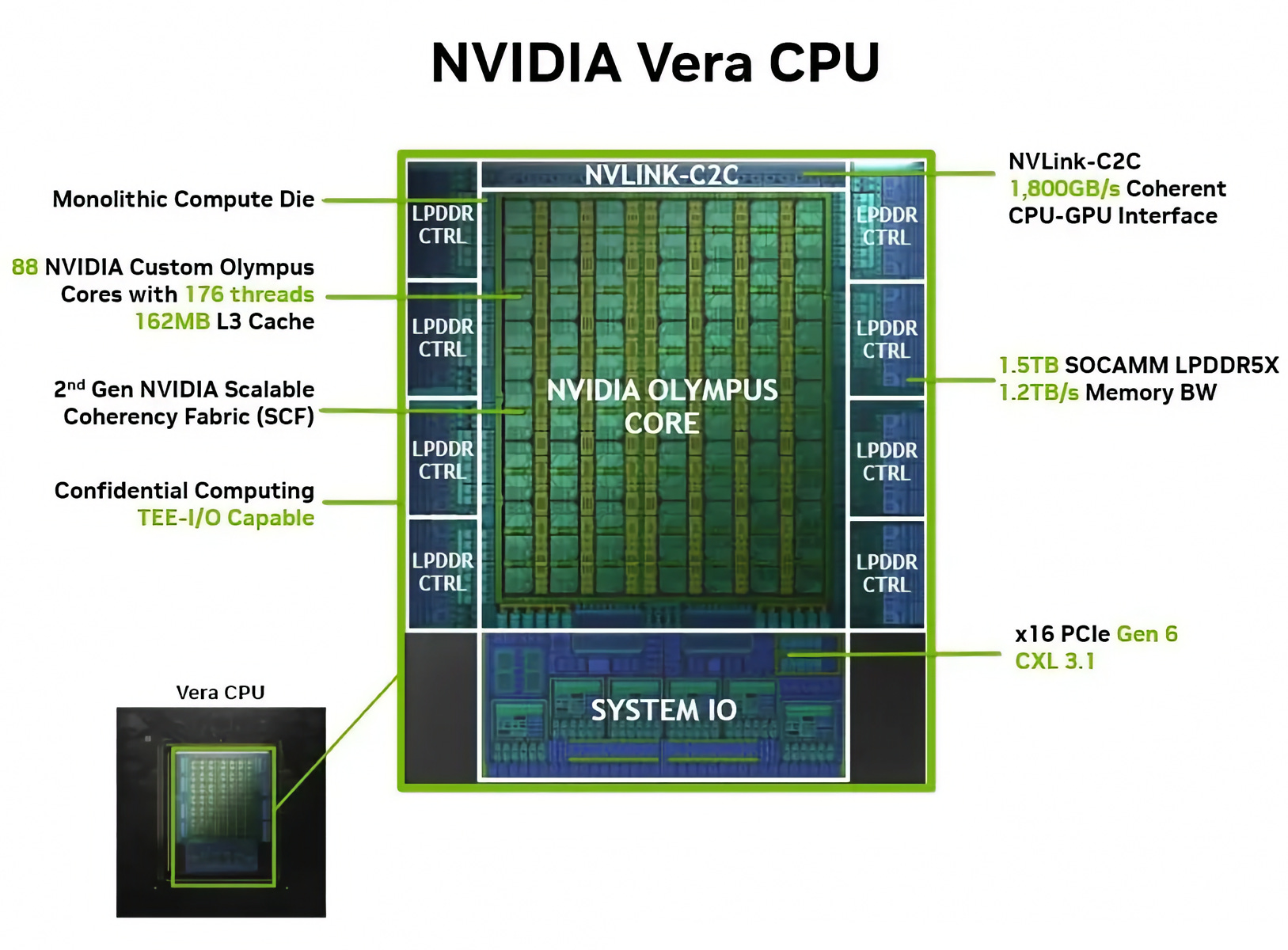
After years of GPUs getting all the love, CPUs are back in the spotlight, and Nvidia wants its big slice of the 5-layer cake (🍰) there too:
Colette Kress: Agentic AI and reinforcement learning represents new growth opportunities for CPUs. Building on the success of our Grace CPU, Vera is arriving just in time to meet this inflection. Built on custom ARM cores and codesigned end-to-end with Rubin GPUs and NVLink, Vera will deliver up to 1.5x faster performance per core, 2x performance per watt and 4x density per rack compared to x86-based alternatives.
Vera CPU opens a brand-new $200 billion TAM for NVIDIA, a market we have never addressed before, and every major hyperscale and system maker is partnering with us to get it deployed.
I’m always wary of large TAM numbers, but in the AI world, big numbers have had a tendency to materialize.
We have visibility to nearly $20 billion in total CPU revenue this year, setting us up to become the world’s leading CPU supplier.
More from Jensen on why demand for CPU is exploding:
Jensen: Claude Code is essentially a harness around Claude. OpenAI's Codex is a harness around the GPT-5.5 model… these harnesses provide for things like I/O, orchestration, memory management, tool use connected to tools, for example, browsers and things like that, C compilers, python compilers.
the harness runs on CPU. And the tool use runs on CPUs. So for example, if the AI were to do a search or do a browser, use a browser, that would run on the CPU. The world has 1 billion users, human users. My sense is that the world is going to have billions of agents.
Not today, I mean, we’re going to grow into it, but we’ll have billions of agents. And those billions of agents will all use tools. And those tools can be like PCs, just like us humans using PCs today.
Grace (which was bundled) and now Vera (which can be purchased standalone) allow Nvidia to sell the whole stack, rather than relying on AMD and Intel CPUs. They’ll still offer them, but it probably feels good not to have to sell your competitors’ products.
Morgan Stanley had an estimate of the impact of rising memory prices on Vera Rubin, Nvidia’s next generation:
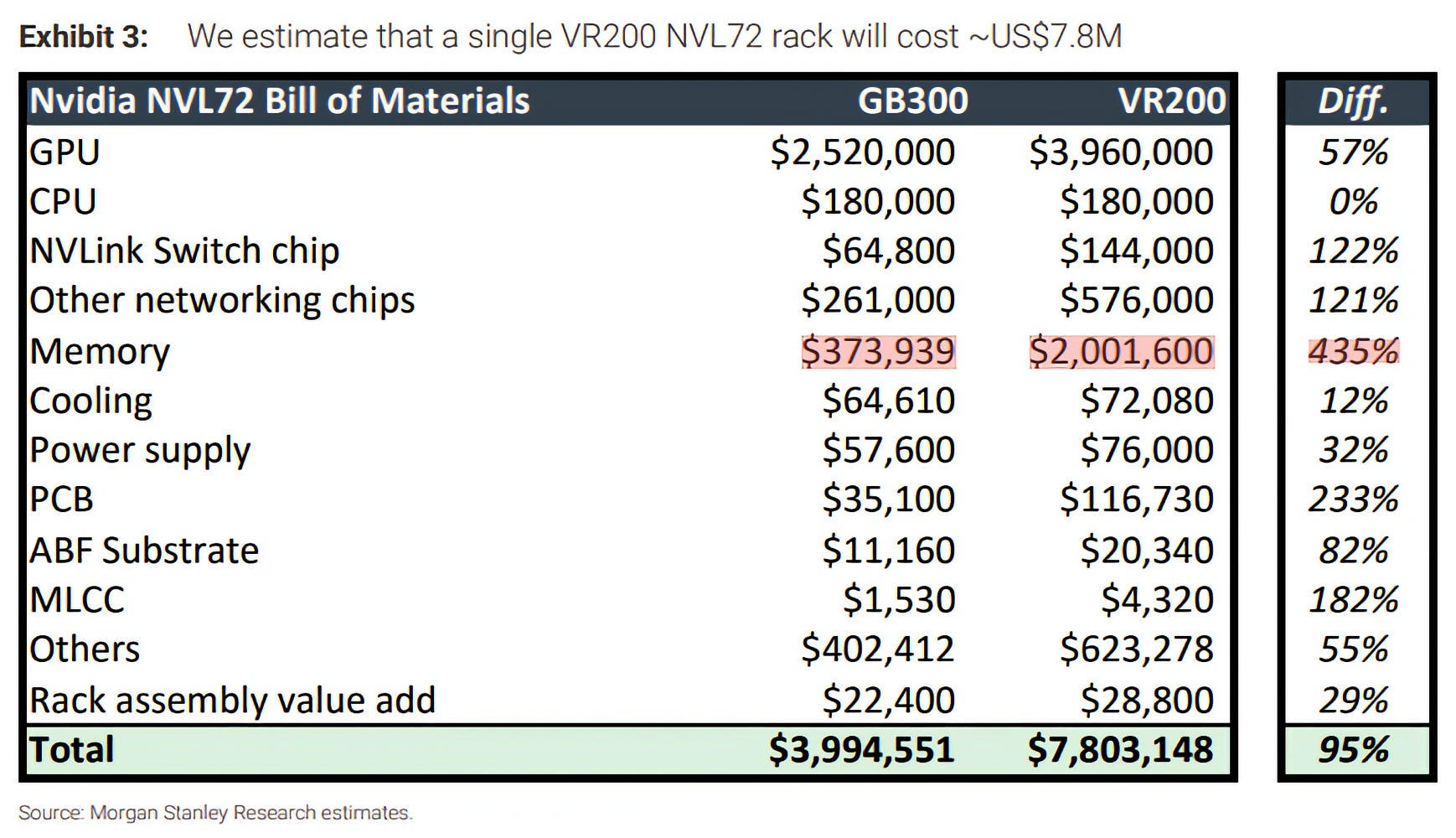
Bonkers, no?
It'll be interesting how long they can keep passing on those COGS to customers without taking a margin hit. And whether less differentiated competitors get squeezed harder by the same memory inflation. 🗜️

On China, it’s still Schrödinger's market. 🇨🇳🐈
Q1 FY26 had $4.6B in Data Center Hopper shipments to China.
Q1 FY27: zero.
And they still grew 85% anyway.
They got approval from the U.S. side for H200, but got blocked from the Chinese side. For a while, they were blocked from the U.S. side but got demand from China. Who knows where this will go, but they say that they aren’t including any revenue from China in their forecasts.
Despite that, they're guiding $91bn next quarter, another sequential acceleration on top of a record base.
Finally, on the capital allocation front, since it doesn’t look like they’ll plough tens of billions into the frontier labs anymore (Jensen said the recent $30bn OpenAI check and $10bn Anthropic check are probably the last big ones, since they're heading toward IPOs), they announced an $80bn buyback authorization + raised the dividend from $0.01 to $0.25. Not moving the needle that much, but at their scale, options are limited.
They generated $48.6bn in free cash flow just last quarter. The question becomes: what do you do with it? 💰💰💰
🗣️💬 Gavin Baker: When Software Becomes Labor, TSMC as the Accidental Central Bank of AI, GPU Racks in Space, Etc
Interesting interview on the state of the markets and AI.
Here are highlights:
-The Vertical ARR Curve: AI Revenue Has Entered the Weird Zone 🛸
Gavin Baker: what [is] happening in AI was the most extraordinary moment in the history of capitalism, the history of American business. What I mean by that is Anthropic added $11 billion of ARR. What is astonishing to me about this, is the SaaS and cloud revolution created, we’ll call it, between $5 and $10 trillion of value. Arguably the 3 highest-profile SaaS companies in the last 10 to 12 years are Palantir, Snowflake, and Databricks. These 3 companies employ thousands of people, tens of thousands collectively. They’ve all spent 10 years building their businesses, and Anthropic added their combined businesses in 1 month.
Nothing like that has ever happened in the history of capitalism — forget my career, just the flat-out history of capitalism, the history of business. It’s wild.
So what explains this? How can AI labs grow at a rate that would’ve sounded fake in almost any previous cycle?
I think it’s because software revenue used to be tethered to humans, even when the software itself scaled beautifully. I mean, it’s great that copying bits has zero marginal cost, but if to get more usage you need more employees, more seats, more workflows getting approved, more training, more integrations, more sales people and more steak dinners, more people changing their habits… there’s still a lot of friction in the system.
Or to put it another way: Even the best SaaS companies had to pass through the narrow straw of human adoption. 🥤
With AI agents, that straw turns into a firehose.
If you give a company 1,000 AI agents, you don’t need to hire 1,000 people before they can start consuming tokens. They can scale from 10 active tasks to 100,000 tasks overnight. Compute consumption can ramp up instantly by orders of magnitude without waiting for Debbie from HR to give orientation to a single person.
Software used to amplify labor. Now software is becoming a kind of labor.
This doesn’t mean that things won’t ultimately be limited by other factors, including ROI on all those tokens, which are increasingly expensive (and as I wrote in Tokens Schmokens, a bad metric).
-TSMC as the anti-bubble central banker 🐜🏗️🇹🇼🫧
Gavin Baker: I have been optimistic that this fundamental shortage of wafers, which today is controlled by Taiwan Semi, will prevent one. If Taiwan Semi did what Jensen wanted, I think Nvidia could sell $2 trillion of GPUs in '26 or '27, maybe $2.5 trillion, maybe $3 trillion. But there is a limit where consumers would consume so much, that you probably would be in an overbuild. So Taiwan Semi — if we don't get a bubble, we need to throw a party for them, because they will have single-handedly prevented a bubble.
Usually when people ask “is AI a bubble?”, they look at demand: hype, valuations, capex plans, extrapolated revenue, etc. 📈
What if the answer is on the supply side?
TSMC’s multi-year lead times and conservative capital expenditure are acting as a hard ceiling on global wafer output. Even if you have the cash, you can’t overbuild, or at least, not as much as if supply was freer.
It’s almost like TSMC is the accidental central bank of AI, and they have a “wafer monetary policy” trying to keep the AI economy from running too hot. 🏦
What will be a secondary effect of this?
Forced Capital Efficiency: Because hyperscalers cannot buy all the raw compute they want, they are being forced to innovate at the algorithmic and optimization layers much earlier in the cycle than they normally would.
Kind of similar to what is likely to happen because of memory supply constraints. Expect optimizations to come that will reduce memory usage, possibly significantly (it’s impossible to predict breakthroughs, but we can look at incentives and know that they have changed A LOT in recent times, and the Eye of Sauron has turned to RAM 👁️).
-When Junk Companies Become Cash Machines 🗑️➡️💰
Gavin Baker: Because we are in shortages, the lowest-quality companies are doing the best. If you’re an oil and gas investor, a mining investor, natural resources investor, and you’re well-versed in thinking of costs, this is very intuitive to you. In a real bull market for a commodity, the commodity suppliers with the highest costs go up the most because it’s the most beneficial to them. They go from on the verge of bankruptcy to gushing cash. This is one reason commodity investing is really, really hard. Because quality outperforms during the cycles, but you get all of the outperformance during the downturns when the high-cost guys who mooned during the shortages and the commodity bull markets go bankrupt or whatever.
You’re seeing that happen in every industry. The lowest-quality players — companies that are hated and detested by the hyperscalers and the buyers because they have high costs, they’re unreliable, the parts fail at a high rate — they’re sold out and raising prices. And then that activity gets the interest of these retail accounts on X, and these stocks get bid to the moon. Whereas some of the higher-quality expressions have actually really underperformed. As an investor, it’s hard because you know within a shadow of a doubt that the thing that’s mooned 10x in 3 months or 6 months is going to go right back down, subject to what they do with all the cash.
That can be counterintuitive if you’re used to thinking “better business = better stock.”
Anyone who has looked at levered equity stubs with high risk of bankruptcy knows that operating leverage cuts both ways. And when the direction of travel reverses rapidly, the results can be pretty crazy. 🚀
🗣️💬 Anthropic’s CFO Krishna Rao: Compute is our lifeblood 🩸
I rarely feature two interviews by the same interviewer at the same time, but Patrick was on a roll recently and I enjoyed both enough to highlight.
There’s more interesting stuff in this one than I can fit here, so I recommend that you listen to the whole thing to get a better idea of how one of the most consequential companies operates and thinks internally.
Oh, and maybe it’s just me, but it’s a little weird to listen to the audio version because Krishna’s voice has a timbre that sounds a little like Patrick’s (at least, it does at 2x).
Here are my highlights:
-Compute Allocation > Capital Allocation 🤖🤖🤖
Krishna Rao: The compute that we procure is the lifeblood of our business.
It is the most important thing in the company. It’s the canvas on which everything else gets built. The decisions we make on how much compute to buy are some of the most consequential and hardest decisions to make in the entire company. [...]
Thinking of it as not just something that is a variable cost over some time period, but really this resource that’s so fungibly utilized. We run workloads on one day in the morning on a chip for inference, and in the afternoon or evening, we use it for model development.
That paradigm does not exist in a company like a software company or a factory. You can’t repurpose — if you have a bunch of people doing R&D and that’s your R&D expense, they can’t go and become COGS, and vice versa, in most traditional companies. Here, you really have that fungibility. That’s possible.
That’s where the return on compute is so important, and I think people are beginning to understand that. But there’s still a tendency towards treating it like, “Oh, I have to separate these two costs,” when in actuality they’re very self-reinforcing, and that flexibility is what helps to drive revenue short term and long term.
He also drops a crazy stat:
“Our net dollar retention rate is over 500% on an annualized basis.” 🫡
Elite SaaS sits at maybe ~130%. Some exceptional ones have been at ~150-170%.
500% is unprecedented.
And then this:
“On the way here, I was in an Uber, and I signed two double-digit million-dollar commits in the car ride, which was 20 minutes.”
Reminds me of the anecdote about how in eBay’s early days, one guy’s job was just to open envelopes full of checks. This is the AI-era equivalent 😅
-Frontier models unlock TAM, not just better benchmarks 🔓🔑
Krishna Rao: Every time we have a new model, there’s a set of capabilities that are different. People tend to think about model intelligence as IQ — a single number. “Okay, this model was at 110, and then it goes to 125.”
We think of it differently.
Intelligence for us is multidimensional. It’s not just a score. We find that, yes, everyone publishes their model benchmark cards. We find that a lot of those benchmarks are saturated. We publish it too, but our measurement is what the customers tell us. What is the real-world capability of this model?
As we’ve released better and better models, what we’ve seen is it’s not just the outright intelligence. It’s also the ability to do long-horizon tasks. It’s the ability to use tools, or computer use. It’s the ability to do agentic tasks that have specific value even faster. […]
What we’ve found very consistently is that by releasing new models, the TAM is unlocked in a unique way. More TAM gets unlocked. More use cases are possible.
A good illustration of that is this last four months that we’ve had at the company. We started the year with about $9 billion of run-rate revenue, and we ended the quarter with north of $30 billion of run-rate revenue. That kind of a change is enabled by these model intelligence leaps, and then the products that we build around them. That’s what I mean by the returns to frontier intelligence are really high.
I think that’s an important reframing.
It may not seem like a big deal at first, but going from “same thing but better” → “new use cases, new possibilities” matters if we want to understand what is likely to keep happening.
A better model doesn’t just take share inside the existing market. It can colonize whole new corners of the economy.
And what’s 🤯 is that just by the time this interview was recorded, edited, and came out, Anthropic’s run-rate went from $30bn to roughly $45bn, based on the latest reporting.
In fact, there are reports in the WSJ that Q2 is predicted to show $10.9bn in sales, up from $4.8bn in Q1, as well as their first operating profit ($559M). But Anthropic isn't guiding to sustained profitability, they expect to keep losing money for a while longer as compute spend ramps. It’s almost an accidental profit ¯\_(ツ)_/¯
-Anthropic’s Escher Hands Moment 🔁🪞🤖 ⌨️
I wrote about the Escher Hands Era, and clearly we’re going deeper and deeper into it:

Krishna Rao: I can’t speak for other companies, but for us, the scaling laws are alive and well, and we’re seeing that with releases more recently like Mythos. But right now, within the company, 90-plus percent of our code is actually written by Claude Code. A lot of Claude Code’s code is written by Claude Code.
Why do we allocate compute internally? Why would we forgo revenue for it? It’s because the models themselves are helping us build that next generation of models.
Clearly they’re not building with Sonnet.
It’s obviously Mythos that is coding the next version of Claude, and the fact that they haven’t released it widely (which means it can’t be distilled or studied by competitors) probably also has to do with extending that recursive advantage for a bit longer (not just cybersecurity and compute constraints).
There’s also good stuff on how they think about compute allocation, how fungible it is between different use cases, and how they are the only lab more or less agnostic between using Nvidia/TPU/Trainiums.
🧪🔬 Liberty Labs 🧬 🔭
🐜 From Six Dells to 4,032 x GB300s: Inside Jane Street’s New Datacenter 🛜
Caveat: Jane Street is a Dwarkesh sponsor and produced this video. It’s marketing, so treat it accordingly (🧂). With that said, it’s fun to get a tour of one of their datacenters.
“Twenty years ago, our “cluster” was just 6 Dells stacked on the floor of our office. Today, come tour our new Texas datacenter: 4,032 GPUs, liquid cooled.”
It’s a recent one in Texas that they use for training AI models, running liquid-cooled Nvidia GB300s (!). They talk about how much work went into making the DC liquid-cooled, and how many sensors and failsafes they have to detect and isolate leaks (you don’t want to short out millions of dollars of equipment because of a leaky pipe!).
Compared to what hyperscalers are building, this is a tiny cluster, but even with just 4k GPUs, there’s over 8,000km of fiber in that deployment (the distance from Lo Angeles to Tokyo)!
After the DC tour, they sat down to discuss some of the stuff JS does:
This part is 🤯:
There are trading systems we build, and trades that we do, where in order to be competitive you actually have to turn around a packet in under 100 nanoseconds.
That’s a very different regime, right?
People sometimes ask, “Can you write high-performance stuff in OCaml?”
And the answer is: we can. But for this kind of speed, it doesn’t matter whether you write in OCaml, Rust, or C++. You can’t use a CPU.
You’re going to be on an FPGA that’s directly attached to the network, and you’re going to be turning around the packet so fast that if you attached an oscilloscope to the wire on the way in and the wire on the way out, you would see the packet start to leave before it’s done being consumed.
So it’s a very different, very specialized regime. And when you’re in that time regime, you really can’t do very much computation.
This made me curious how much throughput came from the raw feeds from the various exchanges (equities, options, FX, crypto). This is what I found with the help of both Claude and GPT-5.5 (with multiple rounds of them fact-checking each other in extended thinking mode, but errors can remain):
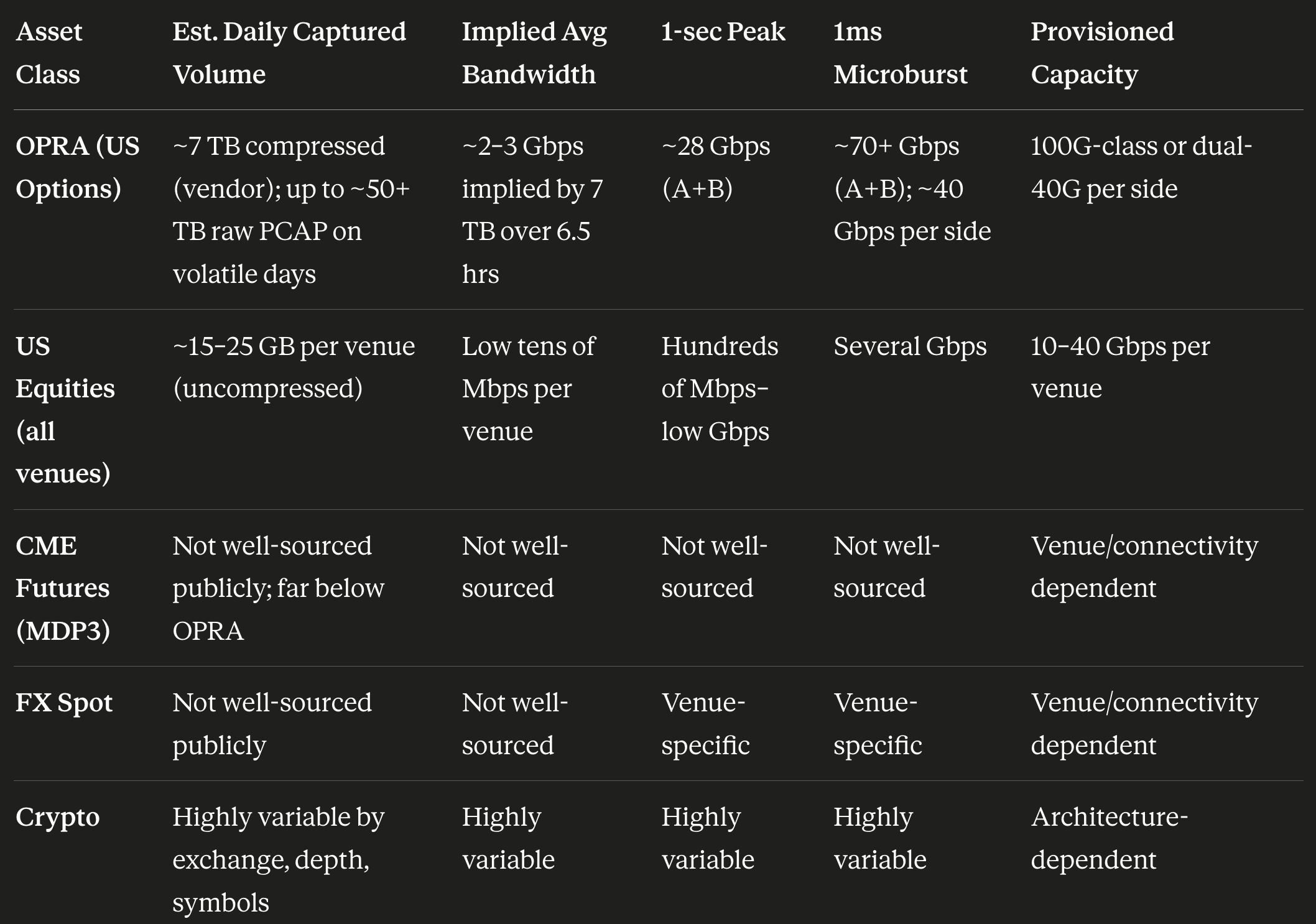
Man, Options are not just bigger than equities… they're in a different weight class. ⛰️
Nasdaq's April 2025 systems commentary has a useful reference point: roughly 165 billion options messages per day versus 7 billion equities messages per day on its systems. A ratio of about 24:1.
So the guesstimate (because this isn’t public info) is that for a tier-1 multi-asset firm like Jane Street, total provisioned inbound market-data capacity is in the hundreds of Gbps range.
And then what kind of compute do you apply to all this raw data... That’s another question entirely.
Cloudflare’s Experience Hunting Security Flaws with Mythos 🔐 🏴☠️
It’s starting to feel like Mythos is building a separate brand from “Claude.” The longer Anthropic keeps it unreleased and separate, the more it’ll feel like its own thing 🤔
Anyway, back to the cybersecurity beat, Cloudflare shared its experience using it:
We soon pointed [Mythos] at more than fifty of our own repositories – to see what it would find, and to see how it works. [...]
Mythos Preview is a real step forward, and it’s worth saying that plainly before getting into anything else. We’ve been running models against our code for a while now, and the jump from what was possible with previous general-purpose frontier models to what Mythos Preview does today is not just a refinement of what came before.
It’s a different kind of tool doing a different kind of work, and that makes a clean apples-to-apples comparison to earlier models difficult.
Mythos isn’t just acting like a better static analyzer. Cloudflare says the big leap is in exploit-chain construction and proof generation.
In other words, it can find several individually unimpressive bugs, reason about how they combine into something more dangerous, then write and run proof-of-concept code to test whether the exploit actually works. 😬
And even if you can use tools like Mythos to find vulnerabilities faster, and then fix your code faster, if the rest of the pipeline for deployment remains the same, it won’t be able to handle this new work. Cloudflare explains:
The loudest reaction to Mythos Preview from other security leaders has been about speed - scan faster, patch faster, compress the response cycle. More than one team we have spoken with is now operating under a two-hour SLA from CVE release to patch in production. The instinct is understandable: when the attacker timeline shortens, the defender timeline has to shorten with it.
Faster is not going to be enough, and we think a lot of teams are about to spend a lot of time, effort, and money learning that the hard way.
Patching faster does not change the shape of the pipeline that produces the patch. If regression testing takes a day, you cannot get to a two-hour SLA without skipping it, and the bugs you ship when you skip regression testing tend to be worse than the bugs you were trying to patch.
🎧🇺🇦 Ukraine: Update from the Frontline of the Drone Wars
The latest episode of WarTalk has guest Rob Lee reporting from Kyiv on how things are these days in Ukraine. Drone tactics, how both sides are organizing operations, what's likely next, and why Rob Lee thinks Starlink is the game-changer of this war.
The part about how Vampire drones are used for logistics is very sci-fi. They airdrop medical kits to wounded soldiers, lay mines, and carry infantry packs so the guys can sprint all out across open ground until they reach cover, where the drones drop their gear off, like flying sherpas.
Rob Lee also says that only about 2% of Ukrainian casualties in one area came from small arms. The 'forward line of troops' has been quietly replaced by a forward line of drone teams.
🧠📊 The Two-Thirds Decline in Dementia Risk, and Why Cases Keep Climbing
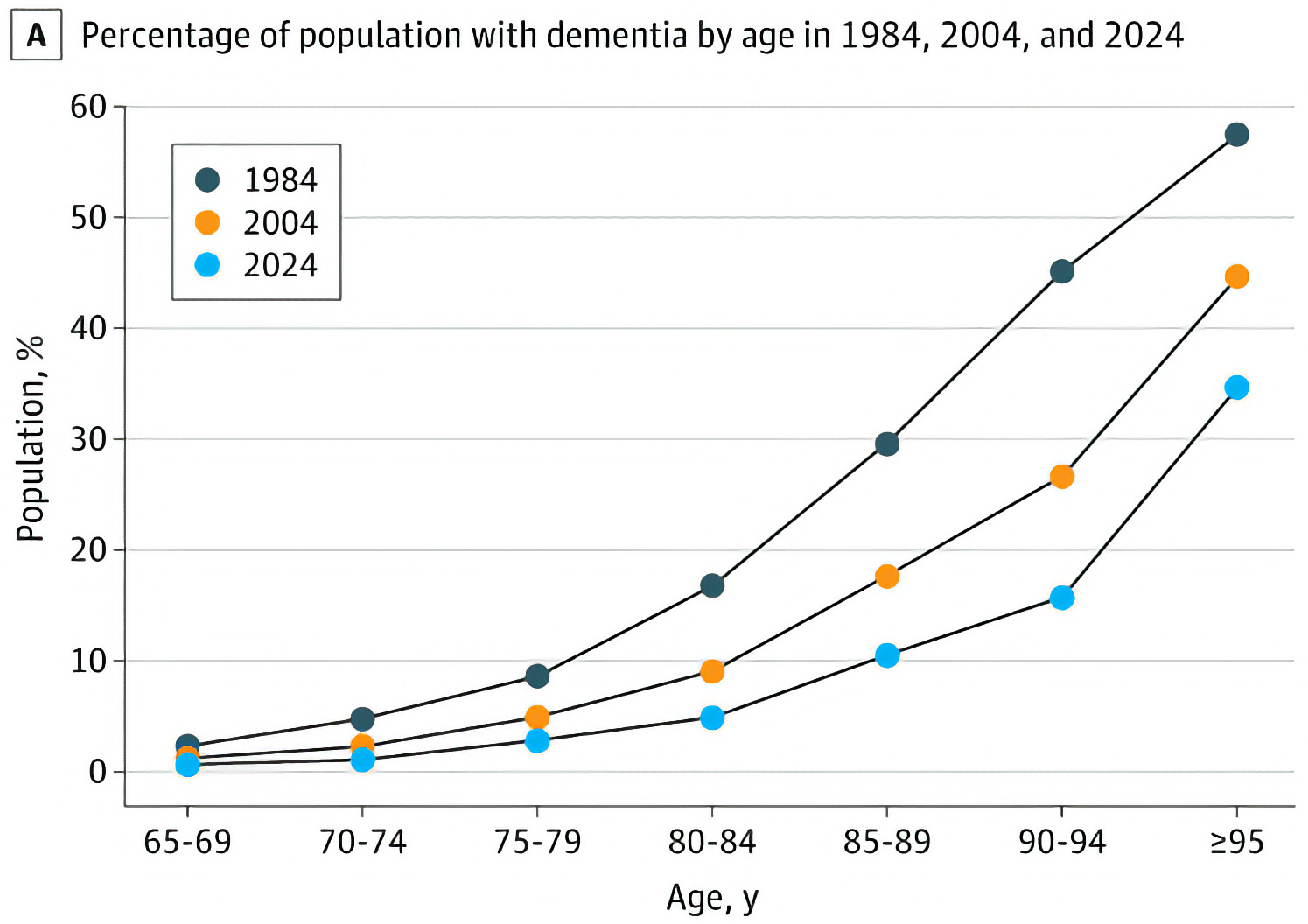
We still need to figure out how to bend that curve down, but at least we can clearly see some progress over the decades.
The good news first:
A comprehensive analysis of three large population-based studies found that the age-adjusted prevalence of dementia has decreased by two-thirds over the past 40 years (Stallard et al., 2025). The data revealed a staggering 67% drop in dementia risk at any given age over this period.
For instance, in 1984, 30% of people aged 85–89 had dementia; by 2024, this figure had fallen to just 10%. Additional analysis of the data also revealed that each successive five-year birth cohort has a lower risk of dementia at a given age than did their predecessor.
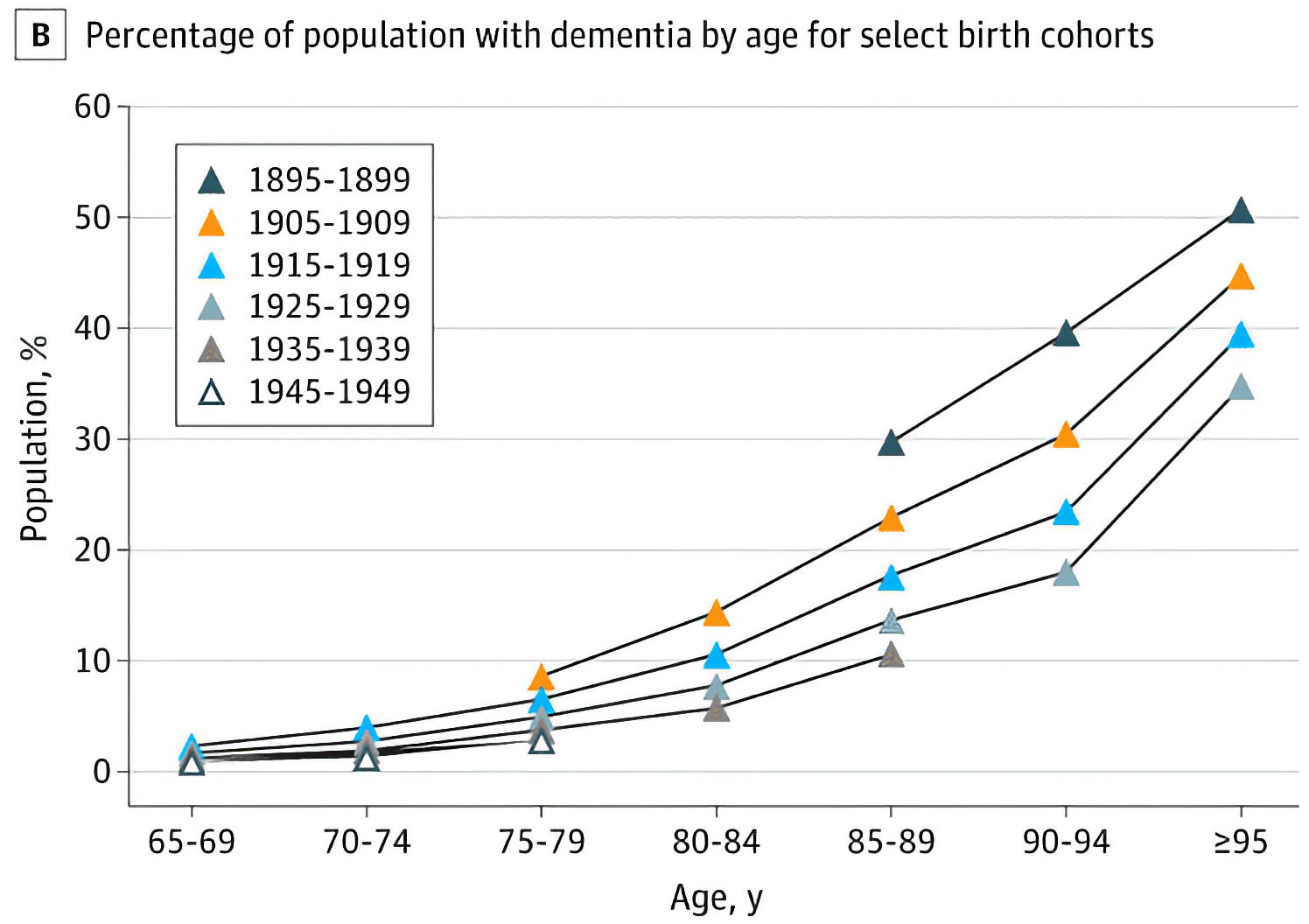
But still:
Dementia is one of the biggest healthcare challenges of the 21st century, affecting millions worldwide. In the UK, nearly 1 million people are currently living with dementia, a figure projected to rise to 1.4 million by 2040. In the United States, more than 6 million people suffer from dementia, and the condition is responsible for over 100,000 deaths annually.
Dementia also carries a substantial economic burden, with total costs exceeding $600 billion annually in the United States. (Source)
Despite the encouraging decline in dementia incidence, the absolute number of people living with dementia continues to grow because the average age of the population keeps going up (as fertility keeps going down).
🎨 🎭 Liberty Studio 👩🎨 🎥

🚀🔧🌕🧑🚀🧑🚀🧑🚀 Apollo 13: The Hard Way Ages Best 🌎
Rewatched this with the family last weekend. First time in years for me, first time ever for my two kids. It was even better than I remembered. Probably my favorite Ron Howard film.
About halfway through, one of my kids asked “Wait, all this happened?”
Yep, pretty much. They worked really hard to keep it accurate.
The zero-g still looks amazing.
This is a 1995 film, so the effects should look dated. They don’t, because Ron Howard refused to fake it with wires. He talked NASA into letting them use the KC-135 reduced-gravity training plane (affectionately known as the “Vomit Comet” 😅). It flies parabolic arcs that produce about 25 seconds of free fall at a time.
The eleven-person cast and crew flew 13 days over a four-week period, did 612 parabolas, all that to get probably no more than 15-20 minutes of usable zero-g footage that ended up in the film.
Kevin Bacon described it: 40 parabolas in the morning, lunch (which someone, foolishly, decided should include Mexican food 🌮🌯), 40 more in the afternoon. 🤢

There’s a reason other sci-fi productions don’t do this! You have to be a little crazy.
My kids never even questioned it. They just took it as given that they were watching people in space.
A few other things that made me appreciate it more this time:
It’s a systems movie, not an action movie. The hero isn’t a person, it’s a process: checklists, communication loops, simulations, redundancies, inventory. Everyone solving small problems in the right order. The heroes are not saved by one genius epiphany. It’s dozens of small correct decisions made under pressure.
The CO₂ filter scene (make this square thing fit into that round hole) is probably the nerd ideal of constraint-driven engineering on film. 🤓🛠️
Both famous lines are slightly off from the historical record.
Jack Swigert actually said “Okay, Houston, we’ve had a problem here.” Past tense. The film changes it to present tense (”Houston, we have a problem”) because it’s punchier.
“Failure is not an option” was invented for the screenplay. The real Gene Kranz never said it. The line stuck because it captures the culture perfectly, which is what the movie is faithful to, even when it isn’t transcript-perfect (but a lot of the other dialogue comes fromt recordings and transcripts).
A sadder note: Jim Lovell, the real commander whose book the film is based on, died in August 2025 at 97. He has a cameo near the end as the captain of the USS Iwo Jima, the recovery ship. Ron Howard apparently wanted him to play an admiral, but Lovell said: “I retired as a Captain; a Captain I will be.” 🫡
If you have kids who haven’t seen it, this is a great family watch. Suspenseful, clean, historically rooted, full of adults behaving like adults under pressure… which is rarer than people admit.

Want more?
I knew it!
Here you go:
re-asking from 2025.
why has the market for (inexpensive!) inference chips on PCs been a bust?
i expected something remarkable via better privacy and offloading workloads.
instead we get cerebras.
Great post. Loved your section TSMC being the accidental central bank of compute capacities. And therefore ASML is an accidental central bank also?
For some of the new build data centers, is it power availability that is the bottleneck? Is that another “central bank“? Yikes.