

640: Nvidia Invades the PC, SpaceX is Really a Neocloud, Frontier Token Math, OpenAI = Dropbox?, RAM, Meta AI Insta Hack, Google's 64 Million Mosquitoes, and Led Zeppelin
"Without those juicy Anthropic bucks"

Self pity is the cause of many sorrows and the solution to none of them.
—Stoic Emperor
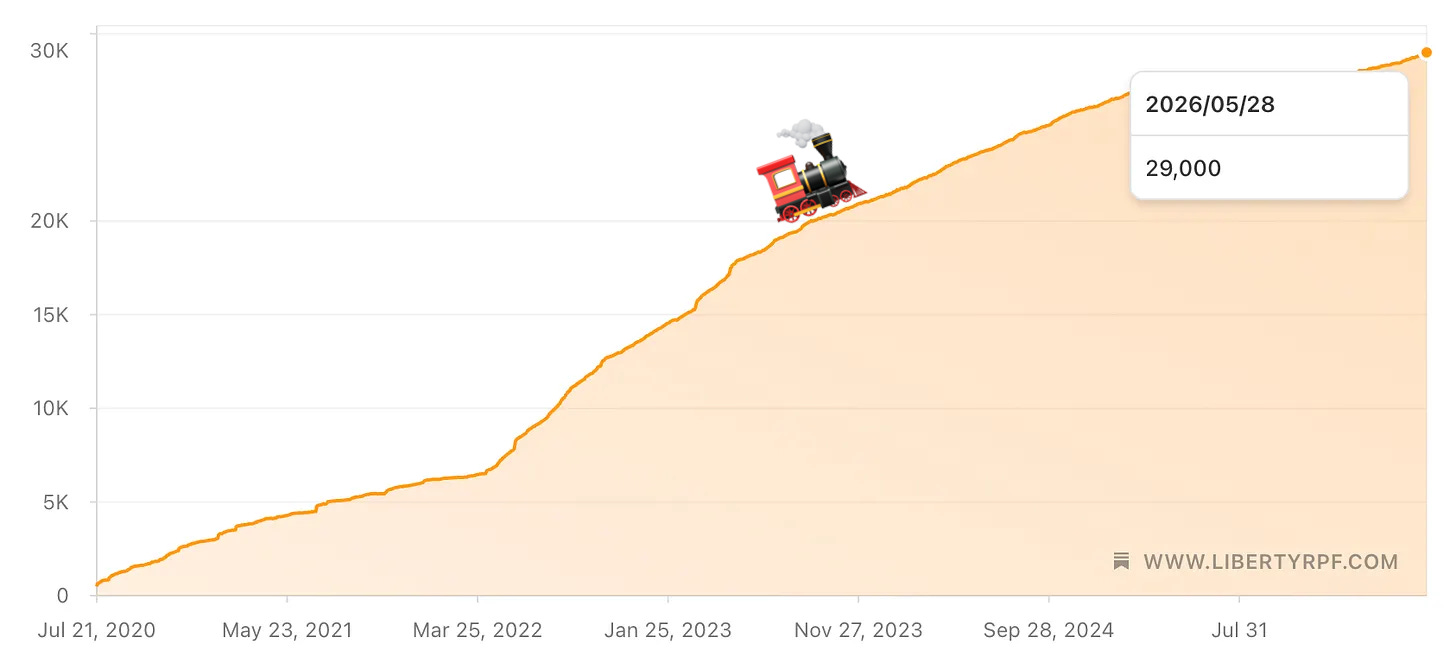
🚢 📈 Another arbitrary milestone.
Near the end of May, the crew on this steamboat reached 29,000. That’s 2.4 Hobarts!
I always think the graph is a bit funny. The least viral chart ever. No spikes, no hits, just chugging along and doing its thing.
It probably doesn’t help that you and I go in ALL the directions and it’s hard to share just one segment cleanly. But oh well, I optimize for what I find interesting, not for what travels smoothly ¯\_(ツ)_/¯
29k is a lot of people if, like, you’re hosting a backyard BBQ. But it’s not a lot of people in the grand scheme of things.
I looked it up, and there are about 1.5 billion people who understand English (380 million native speakers and 1.1bn+ as a second or nth language). Of course, only a tiny fraction of 1% of these are nerdy enough to fit the psychographics of our crazy Venn diagrams, but that’s still quite a big potential crew.
So we’ll see. I’m curious how many inboxes will be on the receiving end of my keyboard at Edition #1,280 🤔
👨🚀🚀⭐🦠 Last week, I published one of the most fun podcasts I've ever recorded. If you missed it (and have read or seen Project Hail Mary, because it’s spoilerific), check it out:
I’m still reading the book out loud to my kids, and they’re enjoying it SO MUCH. During the big moments, they are literally on the edge of the sofa. I love to see a good story have that effect. I hope that in many years, they’ll look back fondly on these moments together.
I’m also looking forward to watching the film together once we’re done with the book.
🔎📫💚 🥃 If you want Liberty’s Highlights to continue, this is the moment. Become a paid supporter.
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Business & Investing 💳 💴

⚡💻 RTX Spark: Nvidia Puts Data-Center Silicon in a Laptop
We knew it was coming, one of those badly kept secrets. But now it’s here for real.
Nvidia announced a system-on-a-chip (SoC) designed to power Windows laptops and give them the vrrooomm vrroooom necessary to run AI agents and heavy workloads locally.
The RTX Spark superchip features an NVIDIA Blackwell RTX GPU with 6,144 CUDA cores and fifth-generation Tensor Cores with FP4 precision, connected via the NVIDIA NVLink-C2C chip-to-chip interconnect to a high-performance, 20-core NVIDIA Grace CPU.
You can bet that the next version will have Vera CPU cores and a Rubin GPU.
It’s kinda wild that you can pack chips from the same family as what’s in hot data-center racks into a laptop (though of course, they aren’t exactly the same chips, otherwise you’d have molten aluminum on your lap).
They want to do this with a mix of new Windows security primitives (for stuff like identity and containment policy) and Nvidia’s OpenShell, which is a kind of sandbox environment around agents like OpenClaw.
A big selling point, like with the DGX Spark and Apple’s Macs, is the unified memory available to both the CPU and GPU (in most PCs, the GPU and CPU have separate memory pools, and the GPU doesn’t have enough to run larger LLMs).
Nvidia has announced ‘up to 128GB of unified memory.’
In theory, that’s enough to run a 120-billion-parameter model with 1 million tokens of context, locally 🤯 (but it may struggle with complex agentic tasks, since they take so much more memory because of the very extensive reasoning and fast-growing multi-agent context windows).
Aside from waiting for the benchmark numbers to come out, the biggest ❓ is about Microsoft’s support for the Arm ISA. Windows and its ecosystem of apps are still mostly x86. While they have an emulator called Prism that translates from x86 to Arm on the fly, its reputation isn’t as good as Apple’s Rosetta, which does the same thing (to be fair, Apple had a much less heterogeneous ecosystem to deal with).
Intel and AMD’s x86 moat is getting a new breach attempt.
🚀 “SpaceX is officially a neocloud” (With a Space Side-Business) ☁️
Turboblitz posted a chart showing SpaceX’s revenue by source, and then Racketboy/Nick updated it to include xAI+Twitter:

I’m mostly sharing because I think it’s funny. But also, let’s give some kudos to xAI’s infrastructure team.


The model team may have dissolved and never really got much traction (and is in the process of being rebooted with Cursor’s transplant), but the infra team will likely turn out to have made a huge difference for SpaceX’s IPO.
It’s hard to know exact capex numbers invested in Colossus 1 and 2 (which add up to about 1 GW of compute together), but the AI Segment level numbers show $26.5B cumulative AI capex from 2023 through Q1 2026.
By comparison, SpaceX disclosed $19.9B of cumulative capex for its core Space + Starlink/Connectivity businesses from 2023 through Q1 2026. If we go back to the foundation of the company in 2002, cumulative capex isn’t disclosed, but if we take the consolidated gross PP&E and remove what we know is the AI capex ($26.545bn), we get a napkin ballpark proxy of $42bn.
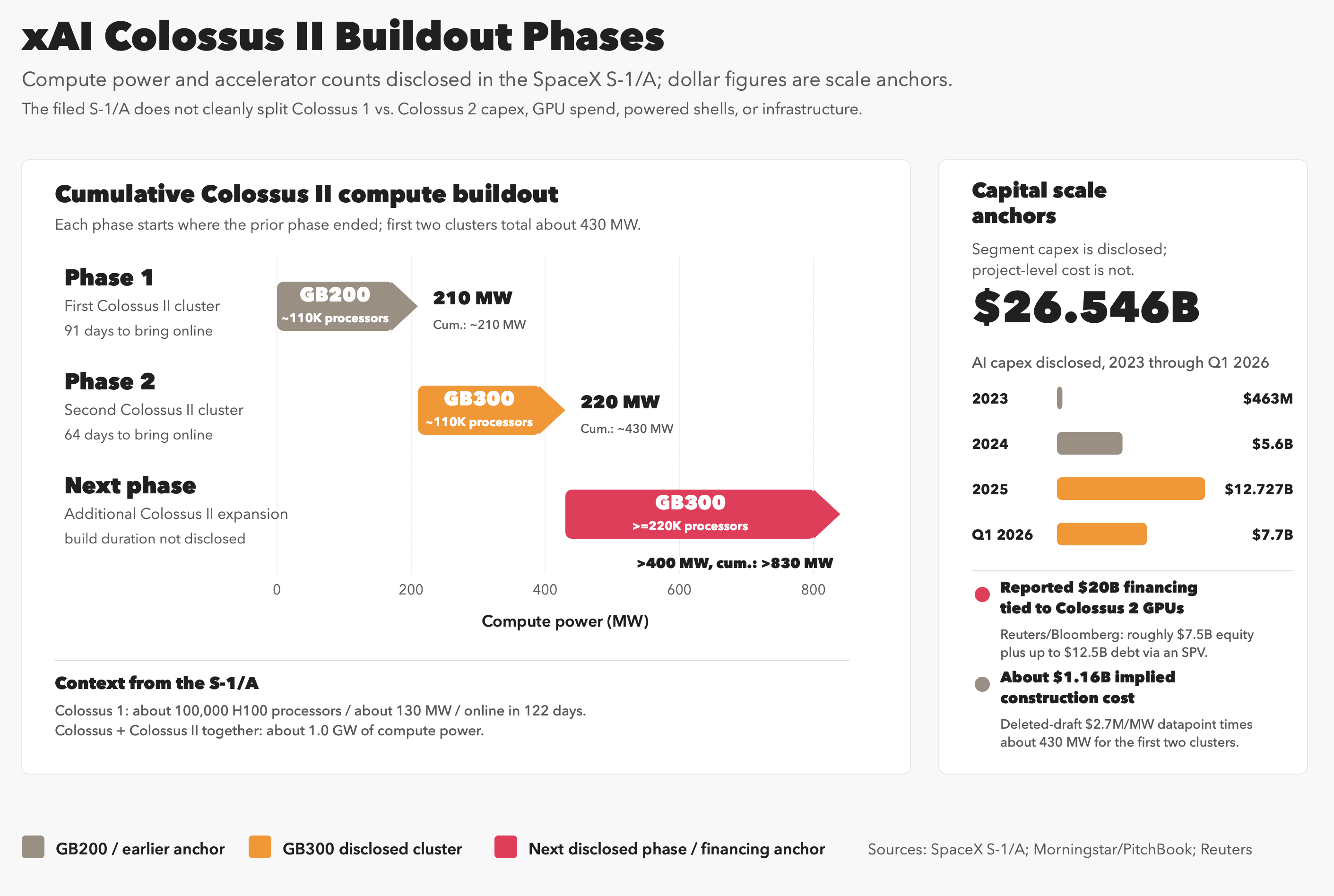
And Colossus 2 isn’t completed yet. As far as I can tell, the first phase was for ~110,000 Nvidia GB200s (~210 MW), the second was for ~110,000 GB300s (~220 MW), and the next one will add ~220,000 GB300s (>400 MW). The first phases have been brought online in record time. We’ll see if they keep the streak going. ⏱️
But one thing is certain: Without those juicy Anthropic bucks, the picture for SpaceX would look a lot worse.
🤖 Why Frontier Models Capture So Much Value (aka When 10-20% Better Is Worth 10x More) 🍰
The main reason is that for many AI workflows, quality is nonlinear.
A model that is 10-20% better on the right dimension may not be 10-20% more valuable. It may cross the line from ‘toy’ to ‘usable,’ or from ‘assistant’ to ‘autonomous agent.’ Coding is the best example of that right now, and we saw that shift happening last December (circa Opus 4.5 and GPT-5.2 Codex).
The likely equilibrium is not ‘frontier wins everything’ or ‘open source commoditizes everything.’ If I had to guess, I’d say that open models will win volume, frontier models will win the work that people can’t afford to get wrong (the stuff that is high-risk, high-reward, high-trust… by far the most valuable), and the app layer will eat some margin in between.
Here's the part that trips people up: token cost usually isn't the binding constraint.
If an engineer is using AI to avoid shipping a bug that costs a week of cleanup or makes a customer angry, the gap between a few cents and a few dollars of inference is noise vs the cost of getting it wrong. In those cases, buyers are rational to overpay for the best model.
Is there such a thing as ‘good enough’?
The answer depends on the task.
For bounded, verifiable, low-risk tasks, you can find ‘good enough’ and leave it at that. Once a model can reliably extract fields from invoices, sort support tickets, and summarize meeting notes, you move on to optimizing for stuff like cost, latency, privacy, and integration.
For tasks that are open-ended, high-leverage, high-risk, ‘good enough’ is always kind of just over the horizon. Coding agents, legal and medical reasoning, anything that runs unsupervised. With that stuff, you could always use fewer errors and better quality. A model that fails 8% of the time may be unusable. A model that fails 2% of the time may be transformative.
Something that fails 0.5% of the time may expand the TAM and spawn a whole new industry.
The State of Token Subsidies: $2,180 of Tokens for $200 🪙
I currently subscribe to the $100/month Max plan from Anthropic and the $100/month Pro plan from OpenAI. If you are a heavy user of coding agents these plans are a fantastic deal. I just ran the ccusage tool on my laptop to get an estimate of how much I would have spent if I were to pay for API tokens in the past 30 days and got:
$1,199.79 for Anthropic Claude Code
$980.37 for OpenAI Codex
That’s $2,180.16 worth of tokens for $200—not bad at all! I’m a moderately heavy user of these tools, but I’m certainly not running agents every hour of the day and night.
Ccusage allows you to track how many tokens you use and do the math on how much it would cost at API pricing. For example:
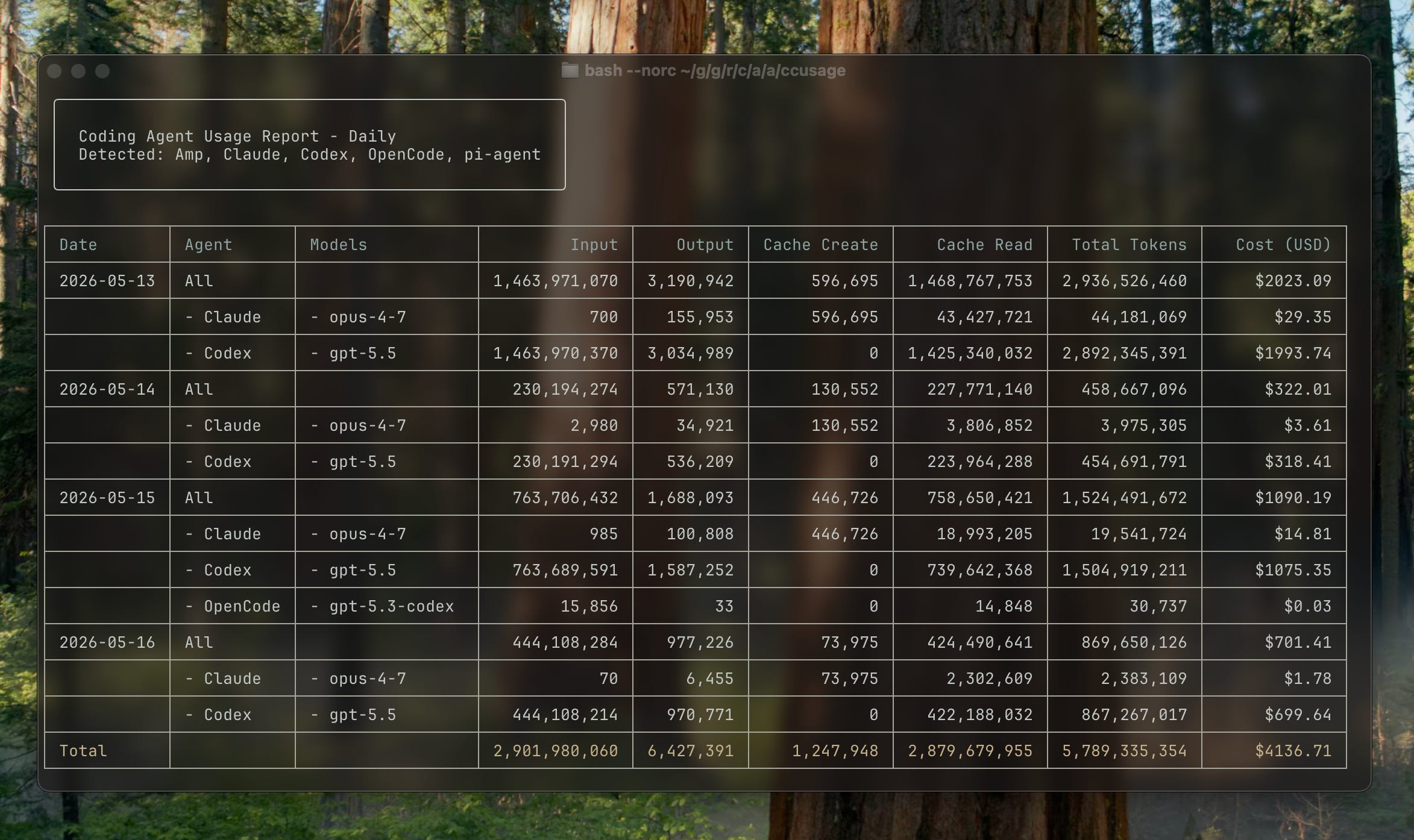
Now, of course, the math is always a bit more complicated than it seems. Flat rate pricing is great for getting new users in the door who might not have tried otherwise, or would have limited their use too much to find their own product-market-fit… which then makes their usage explode, and they end up paying for extra tokens at pay-as-you-go rates.
There’s also the fact that for every whale who will completely max out every 5-hour-window and weekly allocation on Claude Code Max, there are a lot of other users who only use a fraction of that yet still pay the same rate. In the end, it’s the average that matters most, and light users subsidize the whales 🐳🐋
But even with that said, seeing the large disparities between flat and API pricing, I don’t think the situation is sustainable, and we’ll keep seeing the end of the all-you-can-eat buffet era of AI.
OpenAI = Dropbox? 📦 🤔
Finally, here’s an interesting part of last week’s Sharp Tech where Ben Thompson (💚 🥃 🎩):
Dropbox tried to push for a long time to be a consumer company, and they had to pivot because consumers don’t pay for productivity. It’s like the initial version of OpenAI: “We’re going to monetize through consumer subscriptions.” No, you’re not. You won’t make money. Consumers are emailing themselves documents as opposed to paying for storage.
This is such a fundamental error that OpenAI is the latest one to make, but Silicon Valley makes it again and again and again. People in Silicon Valley are obsessed with productivity. People in the rest of the world don’t want to be productive at all—they want to be entertained.
This is why Meta wins. They provide entertainment. […]
The reason why enterprises pay for productivity is because they’re paying people to come to work, and they want to get more value from the dollars they’re already putting in. So they will buy them new computers, they’ll pay for software, and they’ll give them a Dropbox because they’re getting more value from what they’re already paying their people.
Enterprises care and pay for productivity, and consumers don’t. And Silicon Valley continually doesn’t learn that lesson. Dropbox used to be the canonical example. I think OpenAI took that one over.
To be fair, OpenAI has grown revenue faster than almost any other business in history…
BUT
The point is a good one, and they’ve had a much harder time monetizing the non-enterprise, non-productivity side of the business while carrying large infrastructure costs that Anthropic has been less burdened with.
It doesn’t mean that the future will 100% rhyme with the past, and it could be that someday this large consumer pool of users will become a highly monetizable asset, but apparently that day isn’t today.
🧪🔬 Science & Technology 🧬 🔭
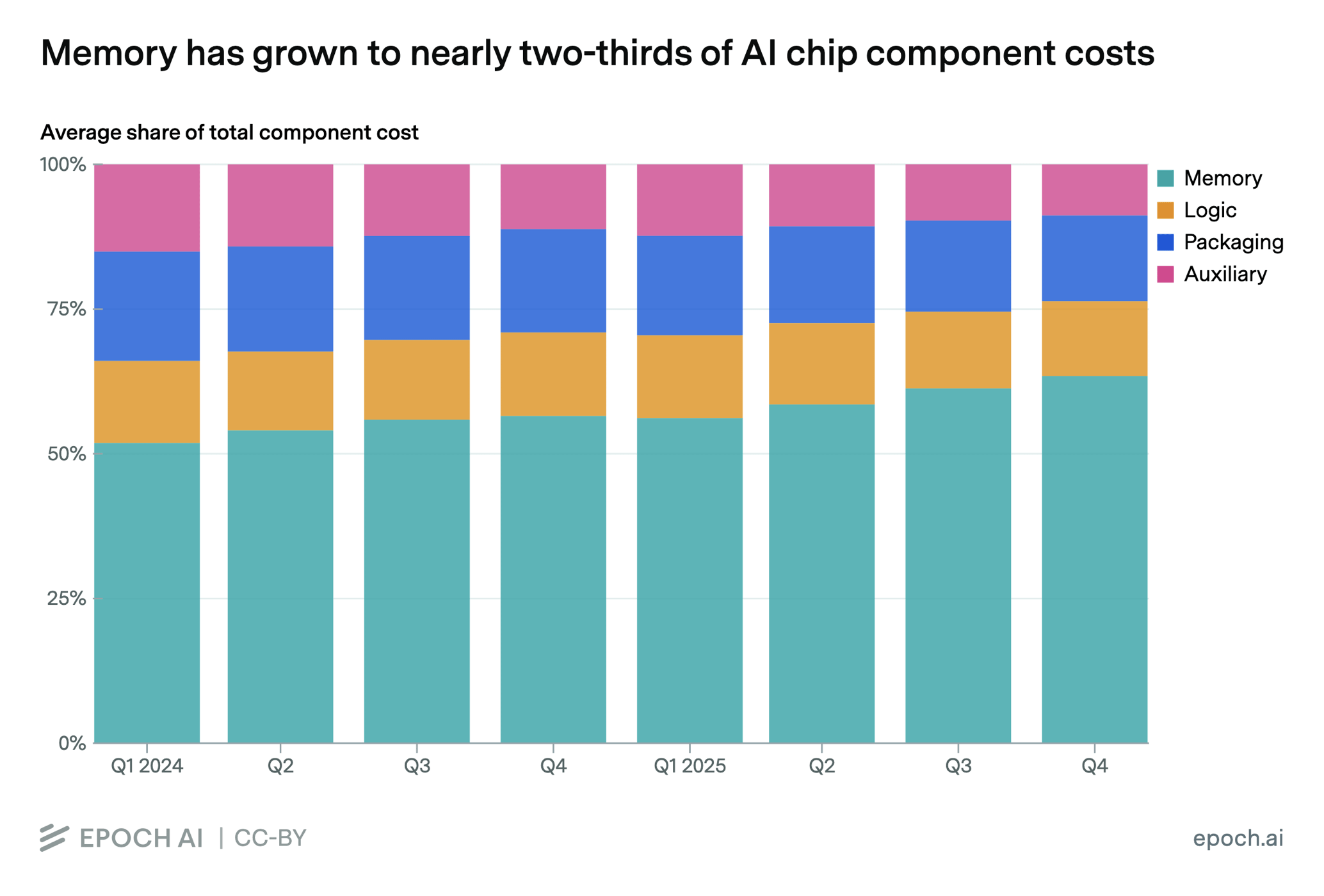
Memory is Now Almost 2/3 of AI Chip Component Costs
Everyone’s talking about memory. You’re probably talking about it with your Uber driver right now!
High-bandwidth memory (HBM) has grown from 52% to 63% of total AI chip component spending between Q1 2024 and Q4 2025. These estimates are an average across all AI chips designed by Nvidia, AMD, Google, and Amazon, weighted by production volume.
As a share of spend, logic dies stayed roughly flat near 13%, while advanced packaging fell from 19% to 15% and auxiliary components fell from 15% to 9%. In absolute terms, HBM spend across these four designers grew from roughly $12 billion in 2024 to $32 billion in 2025, a faster year-over-year increase than any other component. (Source)
And 2026 is set up for even more of it.
🏴☠️📲 Meta's Support AI Hijacks Instagram Accounts If You Just Ask Nicely 😬
A bunch of Instagram accounts got hacked recently. They include some big ones like the Obama White House account and Sephora, and some short ones like ‘@hey’ that are valuable in the same way that short web domain names are.
So far, nothing too unusual. Damn these sophisticated hackers, right?
Then you read how this was done, and it’s not a great look for Meta:
Look, I’m no spring chicken. I’ve spent almost a decade and a half identifying vulnerabilities and exploits at unicorn scale, but this is hands down the most unserious, “almost too stupid to be true” of them all.
The Takeover Flow
Step 01: Faking the Location & Initiating Support
All the attacker needs to kick this off is your account username. Then, they hop on a VPN or proxy close to your city so Instagram’s security algorithms don’t suspect a thing. (You can quite easily get this from your public profile or “About” section or a hundred other ways.) Once it looks like the request is coming from the correct region, they tell the Meta support AI that the account is hacked and ask it to send the verification codes to an arbitrary email address they control.Step 02: That’s It
Really, that’s it. The first proper zero auth password reset I’ve seen in production. There appears to be no additional check as to whether the email being given is actually something the user has used before. Once the AI sends the security code to the attacker’s email, the attacker passes it right back to complete the verification. The platform hands over a fresh password reset link, granting full ownership to the attacker.
What about 2-factor authentication? The thing that everybody tells you will protect you?
This bypasses it entirely 🤦♀️
Existing sessions are revoked and the password changed with no email, text, or push notification. The actual owner can’t initiate recovery because the email and phone numbers now map to the attacker. There’s no human to escalate to, it’s just you arguing with a chat hoping to take control back while praying they don’t do it again.
What’s ironic is that Meta pitched these AI systems as a way to prevent account issues and hacking.
In this March announcement, they said the support assistant was a way to "resolve account problems for you from start to finish" and said that its AI could "prevent an account takeover by noticing it was suddenly accessed from a new location, the password was changed, and edits were made to the profile." That's almost move-for-move what the attacks did.
One Meta AI was supposedly watching for exactly this, but a different Meta AI waved it through.
It looks like Meta has patched the issue, but it was active for months, with Telegram groups offering stolen accounts on the black market.
Who needs Mythos when you can just ask the Meta assistant to hack for you? 😅
Google Wants to Release 64 Million Mosquitoes Carrying Wolbachia Bacteria in Florida and California 🦟🦠
Back in Edition #457, I wrote:
Personally, I’m in favor of heavy mosquito control anywhere humans are present in any concentration. Mosquitoes can have the rest of the world — the planet is plenty big for everyone — but they’ve been annoying me for too long…
Alternatively, I’d take a shoulder-mounted automated laser mini-turret that shoots down any mosquitoes in a 30 feet radius 🤔
No luck yet on the laser turret, but it looks like Google’s Project Debug is working on this.
The plan reads like a Bond villain's opening monologue: release 32 million mosquitoes into California and Florida per year for two years.
BUT
This is the anti-villain plan. The goal is fewer infections and, if it works, fewer of the little vampires ruining your evenings outside.
The CDC calls mosquitoes the deadliest animal on Earth, and the one Debug is targeting this round is Culex quinquefasciatus, the southern house mosquito behind West Nile virus and St. Louis encephalitis. West Nile is the most common mosquito-borne illness in the US, with 1,300-plus severe cases and over a hundred deaths in a typical year. (Worth noting: Debug started by attacking Aedes aegypti, the Zika and dengue mosquito. This proposal is a pivot to a different 🧛♂️.)

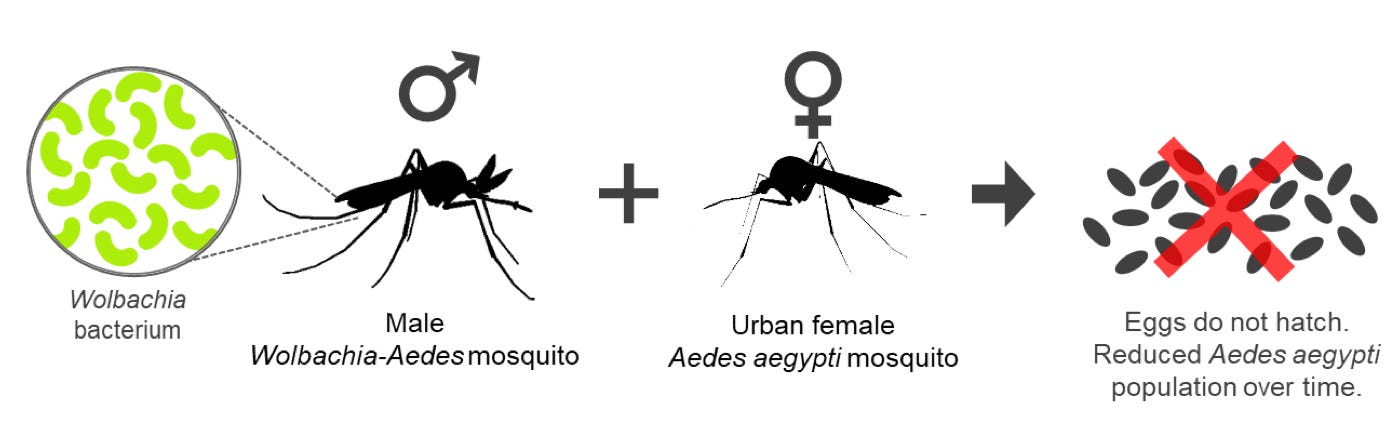
The method is older than it sounds, and it works because of one biological quirk: male mosquitoes don't bite. Only females need a blood meal to make eggs, so releasing males adds zero bites to your summer.
Debug raises males carrying Wolbachia, a bacterium found naturally in loads of insects, and when one of those males mates with a wild female that lacks the same strain, her eggs never hatch. Repeat at scale and each generation comes out smaller than the last.
No genetic engineering required. Google didn’t invent Wolbachia. It, uh, borrowed it. This is the Sterile Insect Technique, a 1950s idea that already cleared screwworms and fruit flies off the board. Mosquitoes were just too delicate to mass-produce until the robots showed up.

And that's the part that makes this a tech story rather than a bug story. You cannot release the females (they bite, and they'd grow the population you're trying to shrink), so the whole thing rises or falls on sorting males from females accurately, tens of millions of times, cheaply. That used to be slow manual work; Debug built sensors, computer vision, and automated rearing to do it at industrial scale, which is the actual hard part.

One catch worth flagging: it's self-limiting. The released males die, nothing propagates through the wild gene pool, and the population drifts back unless you keep releasing. Reassuring if you worry about irreversible meddling, less so if you wanted one-and-done.
It's maintenance, not a cure: stop releasing, and they come back.
Does it actually work?
The Fresno field trials knocked biting females down 68% the first year, then 95%-plus, with the most isolated neighborhood hitting 99%. And in February, a randomized trial in Singapore covering 700,000-plus people found Wolbachia releases cut symptomatic dengue by more than 70% (published in the NEJM). Debug says it's now released over a billion mosquitoes across four continents.
If you're on team fewer mosquitoes, the EPA's taking public comments until June 5. 📩
(The main objection is ecological: collapse a population and you may affect the birds, bats, and dragonflies that eat them. My guess: real in general, overstated here, since both target species are invasive in North America to begin with, anything that eats mosquitoes also eats a lot of other (juicier) insects, and the Earth is a really big place. There will be plenty of mosquitoes left even if we treat near human population centers.)
🎨 🎭 The Arts & History 👩🎨 🎥
🔊 Eddie Kramer on Hendrix, Zeppelin, the Beatles, and the Happy Accidents in the Studio 🎤🥁🎸
I didn’t even know who Eddie Kramer was before I watched this interview, but I enjoyed it enough to share with you. His anecdotes from the studio with Hendrix, Zeppelin, and even the Beatles a few times were super interesting.
He made me notice the glockenspiel on Little Wing in a totally new way. Apparently, Hendrix saw it lying around the studio, had never played it before, and added those well-placed notes to the song in a way that totally transformed its texture. He also has some anecdotes on Jimi’s cover of All Along the Watchtower.
The anecdote about the “woman” pre-echo on Whole Lotta Love is crazy. Zeppelin fans spent the 1970s lying on their beds with headphones, so they’ve noticed that during the middle part, the echo follows Robert Plant’s vocals on every word except one, where the ‘echo’ comes first.
Here, lemme pinpoint the moment using the timestamp feature (it’s quiet, so you may have to crank it up to hear):
It sounds almost supernatural, and people had theories that it was done with studio trickery. But Kramer says it’s accidental. A past take’s vocal recorded on another channel on the same tape bled through while they were recording, and landed in just the right spot! What are the odds of that?
Anyway, it’s a fun one. I just like these stories that tell us a bit of what it must’ve been like on the inside as some of these great records were being made.