

645: How China's AI Punches Above Its Capex, Google's Brain Drain, Neural Software, SpaceX's $6.3B Compute Deal, A24, Five Gens of TPUs, Amazon's Robots Learn English, and Three Beams of Light
"Being really prolific is its own kind of genius."

You are only as young as the last time you changed your mind.
-Kevin Kelly

🇬🇧🎸🎤🎶 I recently listened to an interview with Eddie Kramer, the audio engineer who worked with Jimi Hendrix and Led Zeppelin, and it made me want to listen to those albums again.
So I played Led Zeppelin I this weekend while lifting weights in my basement, and it got me curious about the 2014 remasters. As I was looking up info about them and how the sound had changed from earlier versions, I noticed how close together the original release dates of those albums are.
The first three came out in the span of 18 months, 25 days.
The first four within 2 years, 7 months, 11 days.
What a legendary run.

Not quite as bonkers as the Beatles releasing Help!, Rubber Soul, Revolver, and Sgt. Pepper in just under 22 months, but still.
Being really prolific is its own kind of genius.
When someone or a group of collaborators has something special going on, they gotta strike while the iron’s hot and get the most out of that window.
It never lasts forever.
Dean Simonton noticed something he calls the equal-odds rule: an artist’s hit-to-total ratio stays roughly constant. More output mechanically produces more masterpieces AND more duds. But in the end, what really matters is the absolute number of bangers.
You have to hit reality's tuning fork often, looking for that clear signal.
🔎📫💚 🥃 If you want Liberty’s Highlights to continue, this is the moment. Become a paid supporter.
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Liberty Capital 💳 💴

🌴🍃🤺🇺🇸 How China Stays a Few Months Behind on a Fraction of the AI Capex 🏃♂️🇨🇳
When I look at the capex of Big Tech in the US and China, the difference is pretty big:
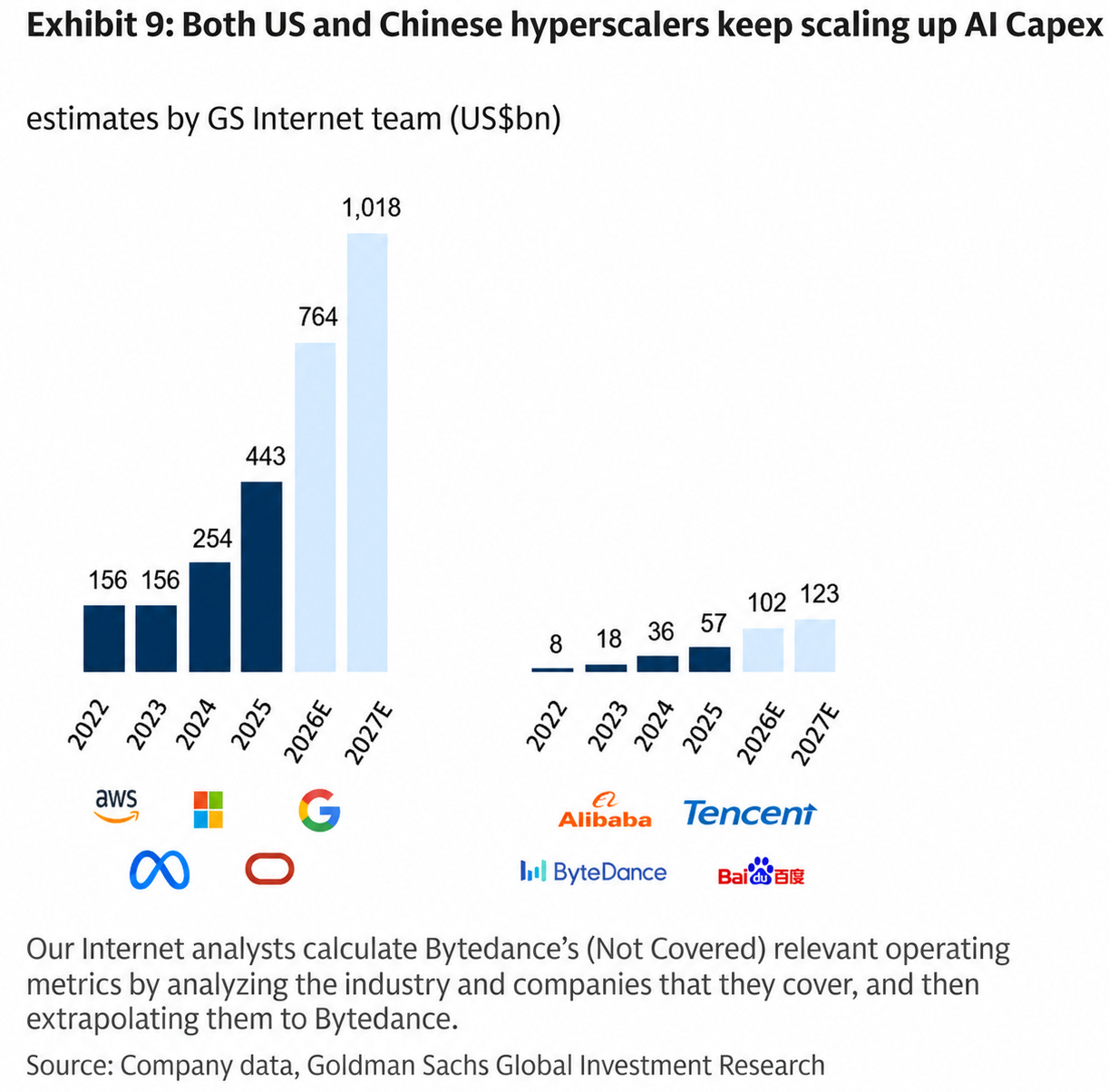
Yet we keep hearing about how Chinese models are just a few months behind. At times, they are this close 🤏 to the frontier, at other times, they fall farther behind, but they are never left totally in the dust. DeepSeek had its moment with R1 in January 2025, and lately it's GLM-5.2 from Z.ai having the moment.
How is it possible?
About 100 Editions ago (still in the Holocene), I wrote about first movers vs second movers:
Pioneers deserve praise for hacking through uncharted jungles (total respect to them 🏆), but history shows that followers often catch up fast. Once someone proves something’s possible, the path clears and followers can sprint ahead, sometimes even passing the trailblazers. It’s often the second mouse that gets the cheese! 🐭
China’s rapid technological advancement perfectly illustrates this: the path to replication and improvement is clearer. [...]
This makes intuitive sense: followers can learn from pioneers’ expensive mistakes, focus resources on proven approaches, and skip the dead-end paths that others have already explored.
Maybe most importantly, the psychological barrier of “that’s impossible” is replaced by the much more concrete challenge of “how do we implement and improve this thing we now know is possible?” 🧠
For Chinese AI models, the cynical view is that they’re benchmaxxing (more than US labs, because everyone does it to some degree) and their models are not as good as they appear on paper. They make a big splash when they come out with competitive scores, but then very few people will rip out Claude or Codex even though the Chinese models are a lot less expensive. The proof’s in the pudding.
The second part of the cynical view is that they are as good as they are mostly because they are distilling American models, and without the gigantic US capex, they could not do all this. Kind of like how the US biotech/pharma R&D powers progress for the rest of the world, and many countries wouldn’t have all kinds of medications without the US spending billions on them.

But is there another less cynical explanation?
I think it goes back to the fast-follower advantages.
If OpenAI/Google/Anthropic/Meta spend enormous sums discovering the scaling laws, architecture tricks, data recipes, RL methods, evals, infrastructure software, and product lessons, a fast follower does not have to rediscover all of that.
They can skip the dead ends and the obsolete intermediate steps the pioneers had to slog through, and point their capital straight at what's already proven. They can train far fewer giant ablation runs and design the whole stack (model and infrastructure) for scale from the start, around a target they know works. And because so much of this is now out in the open (published papers, open weights), and plenty of others can be reverse-engineered, most of the best ideas are there to implement. Near-frontier capability can sometimes be compressed into a much cheaper training run once the recipe is known. 🧑🍳
Forced efficiency also matters. If you have access to a lot of compute, there are some clever algorithmic breakthroughs you won’t make because your resources and attention are better spent elsewhere.
In the end, I tend to see the situation as a hybrid of the cynical view and the natural state of being a fast-follower: The U.S. is paying for exploration and industrial-scale deployment. China is often paying for rapid exploitation, compression, and catch-up. Those are different cost structures.
There’s also a lot of innovation from Chinese labs, but it’s hard to compare because open source innovation gets headlines while closed innovation often stays in the dark, even if it’s just as clever. To me, the most objective way to compare isn’t benchmarks, but adoption by the most sophisticated and discerning users. And so far, the US models are still comfortably in the lead there.
Are we in a somewhat stable equilibrium where, unless the US shoots itself in the face (which is not impossible! to be clear), it will remain in the lead because it’s investing massively more and scale is a big ingredient of, well, scaling laws?
China may never fully take the lead as long as it can’t match that scale of compute (export controls, which are full of holes, but still bite), BUT it also won’t fall far behind because of the second-mover advantages 🤔
🧠 Is Google Experiencing a Brain Drain? 🔋🪫

When I wrote “What is Google Doing?” on Friday, I didn’t expect that right after I published, John Jumper (DeepMind vice president and engineering fellow who co-won the Nobel prize with Demis Hassabis for AlphaFold protein folding breakthroughs) would join Noam Shazeer (co-inventor of the Transformer architecture) in leaving Google.
Shazeer left for OpenAI. Jumper for Anthropic.
This creates the impression of a brain drain (or the potential start of one…), and that something is wrong at Google. Mr. Market didn’t like it, and the stock was down 5% on Monday.
Every departure from Google will be scrutinized for a while, and until they wow us with Gemini 3.5 Pro or a Mythos-like leap forward with Gemini 4, skepticism will be de rigueur.
Which is strange, because it wasn’t that long ago that Google was an obvious AI winner and everybody loved them.
It’s a good reminder of how fickle these winner/loser cycles are (before Google, Microsoft was a winner, then a loser. Meta also had its own cycle where they were clearly a winner, then clearly a loser… 🦙).
The question is: Are we at the part of the industry’s life cycle where the number of winners gets smaller and smaller, and many who fall behind never catch up (like what happened to chip foundries), or is it still a dynamic race? 🏇🏇 🏇 🏇 🏇
🚀 SpaceX Sells $6.3bn of Colossus 2 Compute to Reflection ☁️🤝💰
I guess the Cursor team won’t be using up all that compute in the near future:
Under the agreement, Reflection will get immediate access to Nvidia GB300s, top-of-the-line AI chips used to train and run advanced models, and has agreed to pay SpaceX $150 million per month beginning July 1, 2026, through 2029.
The payments would total about $6.3 billion if the agreement runs through the end of its term. (Source)
Reflection is an open-source AI lab founded by two ex-DeepMind researchers. It has a ~$25bn valuation and Nvidia’s backing.
Once again, like with the Anthropic and Google deals, SpaceX is keeping some flexibility and either company can end the contract with 90 days’ notice after the first three months.
Now that SpaceX is public, it may be hard to turn off the revenue tap without triggering a market reaction. These SpaceX-as-Neocloud deals may prove addictive 💉
🗣️ Neural Software: When the AI Becomes the App, Not the Coder ☁️🧠💾
Interesting interview that covers the bull case for neoclouds and why they might be more differentiated than just a bunch of GPU REITs, why GPU life is longer than many expected, etc..
But the part I found most interesting is the discussion of what Balaban calls neural software. I wrote about this a few years ago, probably under the name real-time generated software or on-demand software or something like that.
The idea is that instead of having an AI code up software for you, you entirely skip that step and just have the AI generate the final output of what that software would be like. eg. the actual text and pixels that such a software would output, kind of like how Google Genie does real-time interactive 3d world generation.
Stephen Balaban: That is part of my idea around what I call neural software, or a neural operating system. [...]
What you’re going to see is a future where the large language model becomes the software, rather than generating it. This results in an extremely flexible way of interfacing with a computer, where it is impossible to have a bug—only a misunderstanding about the prompt and what you’ve asked for. [...]
You can preview what this may be like if you ask a text LLM to pretend it is a Linux workstation, and then you just run various commands (ls, mkdir, ls, top, grep, ping, etc) and it’ll hallucinate responses as if it was running an actual OS.
Stephen Balaban: Eventually, it will also have a multimodal network generating every pixel on your screen, as well as every audio waveform coming out of your speakers. The advantage is that you can dream up software where only the part being experienced by you is actually implemented. [...]
Vibe coding takes in a prompt and outputs human-readable, writable, compilable code that runs on a normal software programming language substrate. [...]
That software is static. Once it has been generated, it cannot change. [...]
But it is still software. The next step is simply interacting with the LLM as it emulates how software might behave. That is the difference between vibe coding and a neural operating system or neural software. With neural software, there is no code running. It is just modifications of the feature activation space and the context in the mind of the neural network.
Sounds like it could be great for some things, but a nightmare for others that require deterministic outputs (banking, medical, etc). Though maybe breakthroughs will allow these neural OSes and apps to have the best of both worlds 🏦🏥
How fast does he think we’re likely to see this?
Stephen Balaban: How far are we from mass adoption?
Generally speaking, when I’m early on something, I tend to be about a decade to a decade and a half early. So, I would say that within 10 to 15 years, we will see the mass adoption of neural software beginning.
As much as the current AI coding advancements are upending the software world, something like this would be a MUCH bigger change. Current AI coding tools can be used by existing software companies to make their products better and, if they’re smart, keep up with new entrants and defend their turf.
But if a lot of software becomes more or less a real-time hallucination by an AI smart enough to make it good enough, coherent enough, and intuitive enough for users to get what they want out of it, I think it transfers a lot more of the value capture to the big AI labs. 🤔
🎥 Google Invests in… A24!? 🍿
I have to admit, I did not see that one coming:
Google is investing in independent movie studio A24 as part of a new artificial-intelligence research partnership between the two companies.
The search giant is putting around $75 million into A24, which released the recent hits “Backrooms” and “Marty Supreme,” according to people familiar with the matter.
It’s not for the data:
Their multiyear, nonexclusive deal doesn’t give Google access to A24’s data, including its film and television library.
So what for?
Google’s DeepMind AI unit and A24 are aiming to create new tools for movie production and distribution. [...]
“We think there are better uses that preserve creative control and support risk-taking,” he said. The new tools “won’t look anything like the prompted generation type of AI that people feel uncomfortable with.”
A24 is in the process of making its most expensive movie ever. It’s a roughly $175m film based on Elden Ring, and it’s directed by Alex Garland (I love his Ex-Machina).
🔌🚘🔋 Electric Car Sales vs Installed Base Turnover
Fun piece by Hannah Ritchie trying to estimate how fast the fleet of cars will electrify.
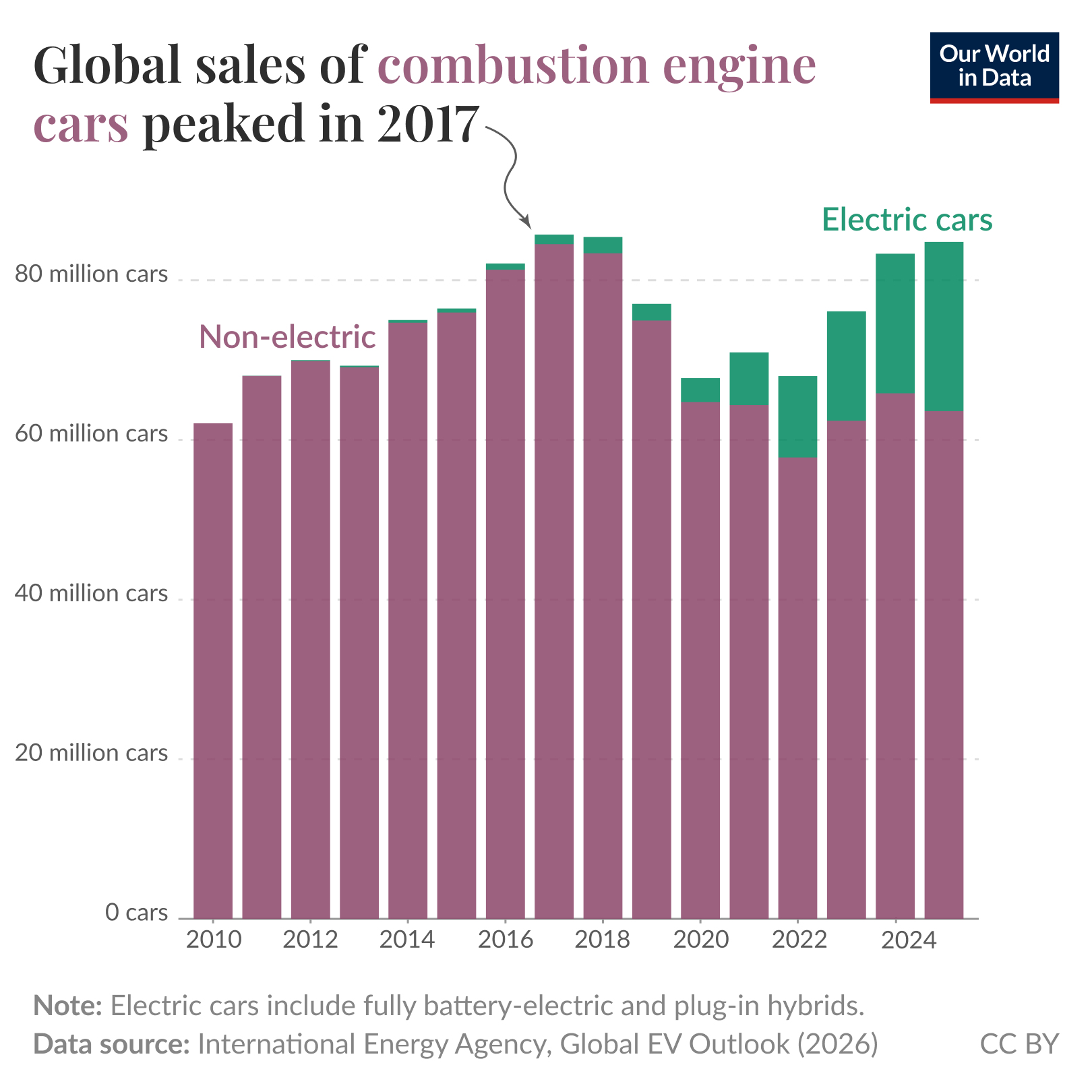
While about 25% of cars sold globally are electric (which includes plug-in hybrids), the adoption rate varies a lot:
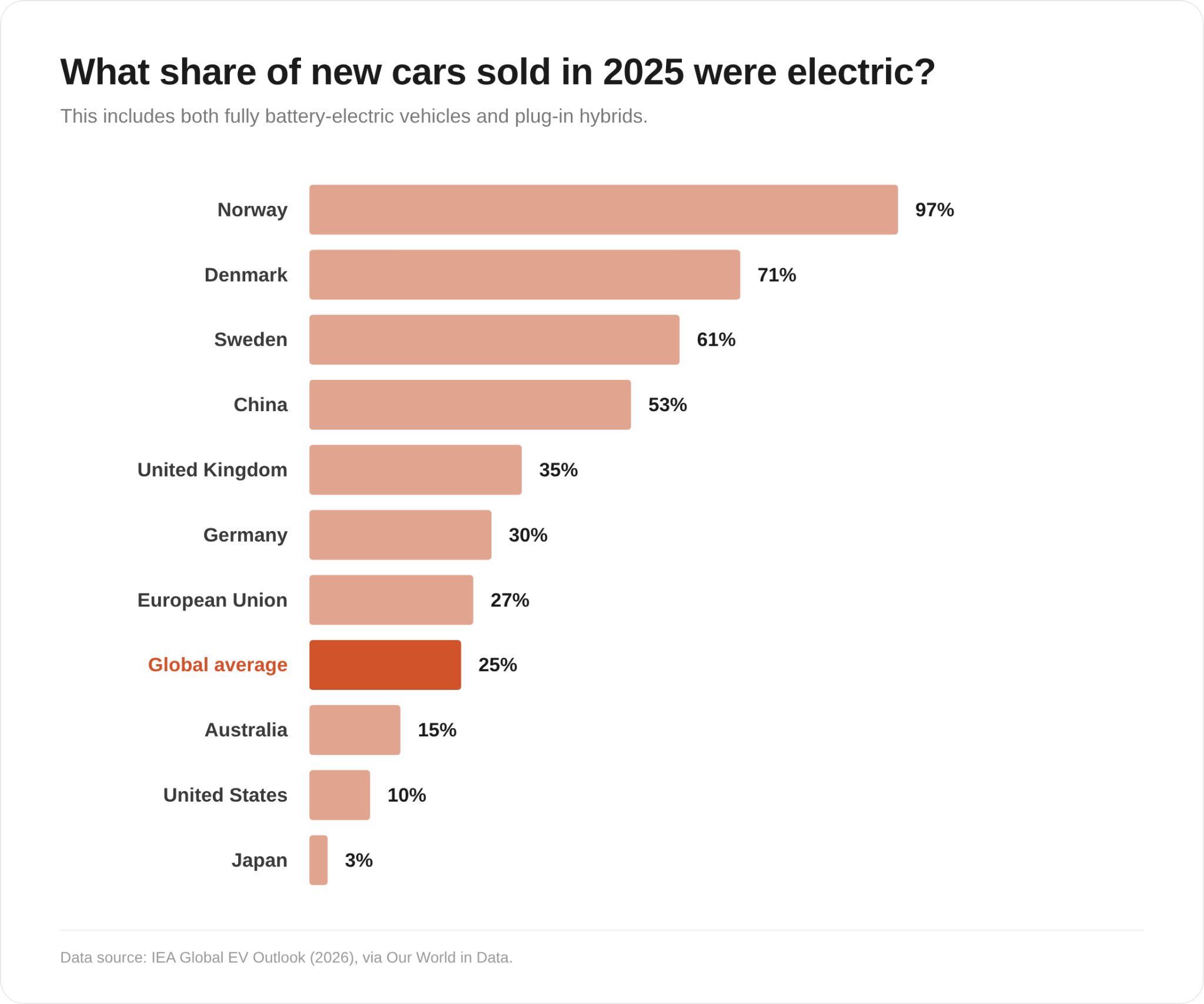
Ritchie built an interactive tool to see how fast the fleet would go electric based on various assumptions. You can also slice and dice it by country or region (Norway is super high, China is doing well, the US is pretty low, etc).
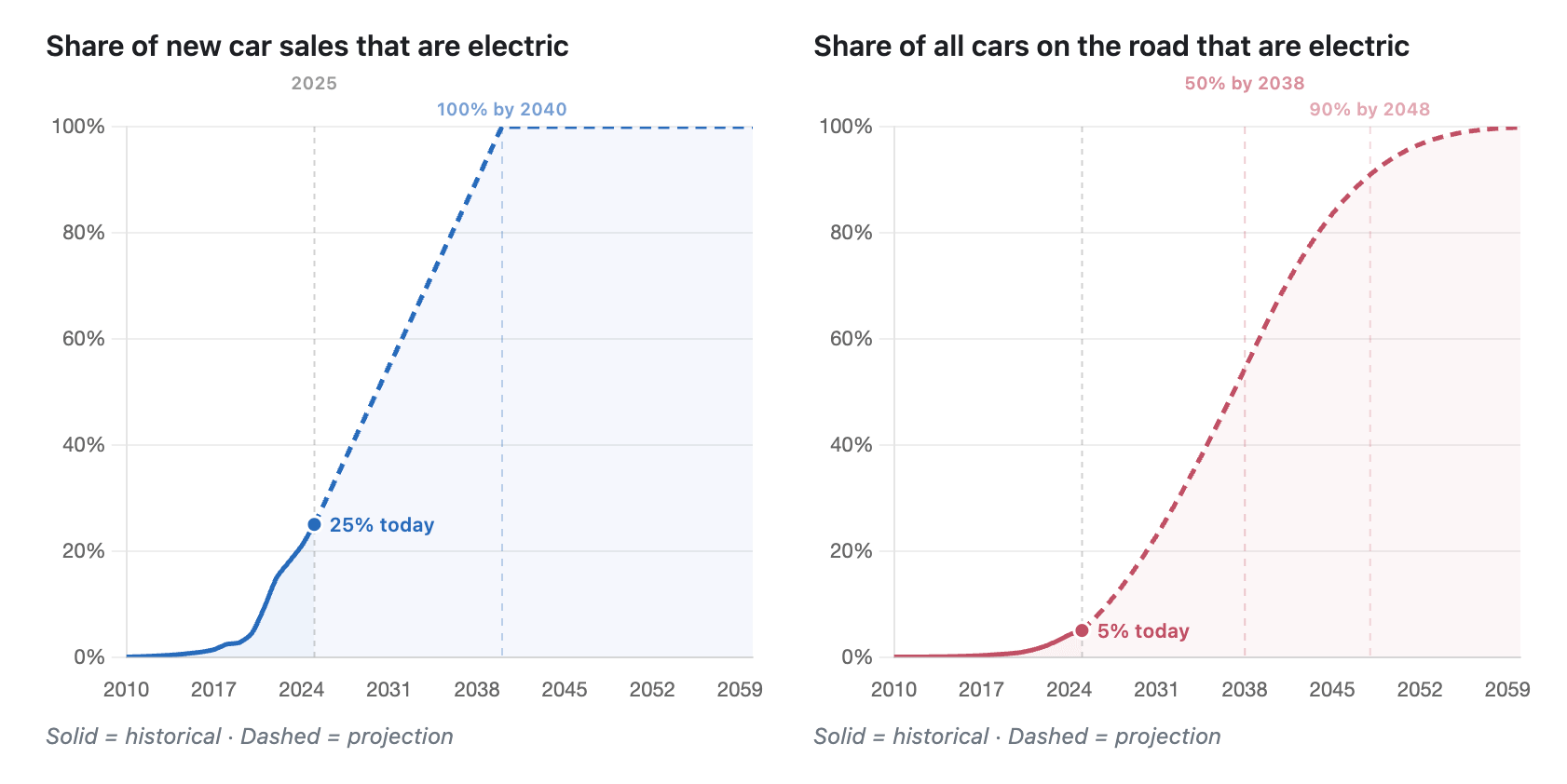
The fleet only turns over as fast as old cars die. So the installed base lags the sales share by a decade or more. Even if every new car sold were electric, you'd be waiting ~15+ years for the roads to catch up.
🇰🇷🇵🇱 Rich Dad Country, Poor Dad Country 🇬🇧🇮🇹
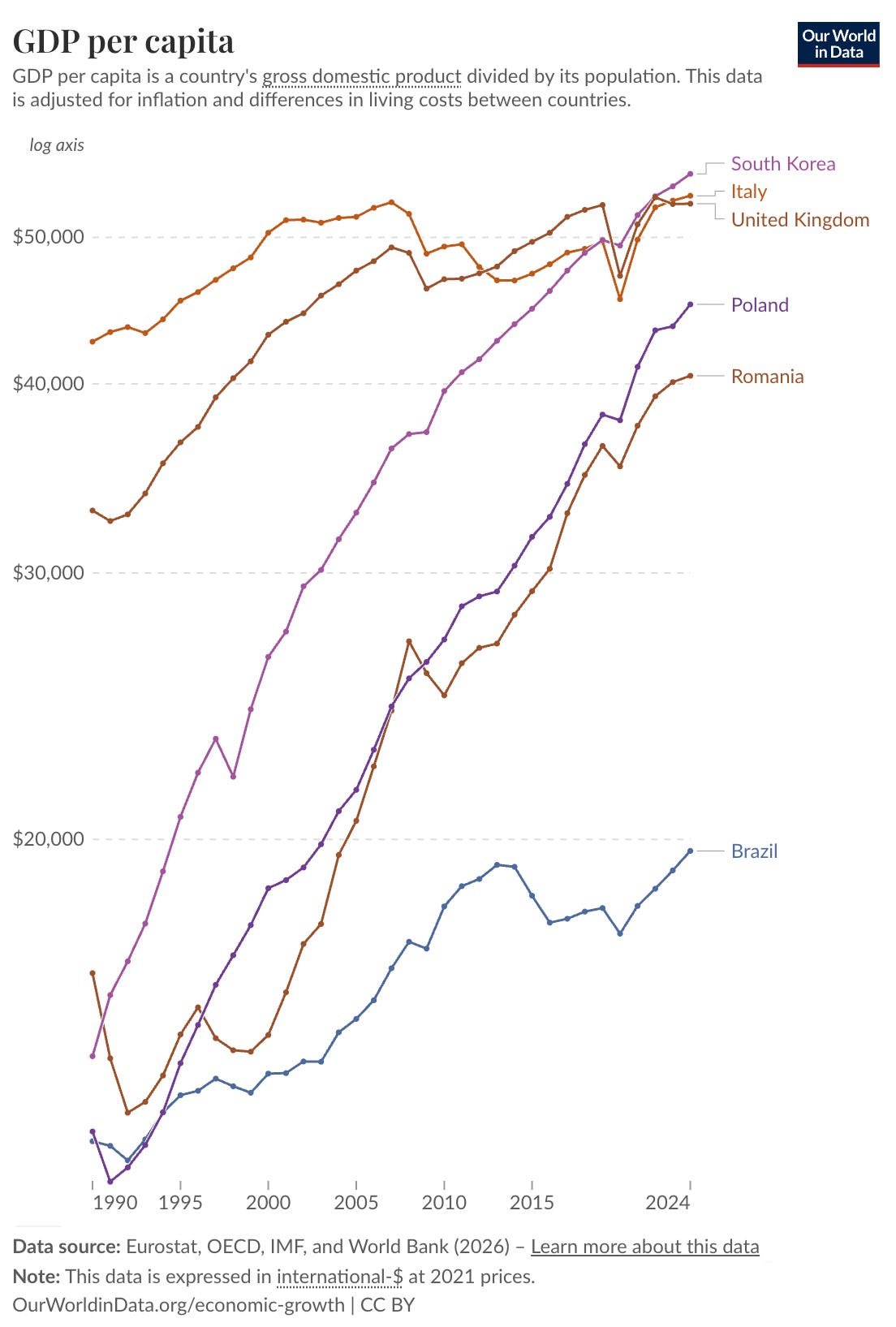
Alec Stapp tweeted a graph that showed GDP per capita (at purchasing power parity) for South Korea and the UK and then expanded the comparison to include Poland.
35 years ago, Poland and Iran had similar standards of living.
Now, Poland is about to pass Japan in GDP per capita.
How do we create more Polands?
I expanded it further to include Romania, Italy, and Brazil to show the contrast in outcomes from similar starting points, caused by making very different choices (freer markets, rule of law, more trade, better education, etc).
Unfortunately, the Fertility Crisis™ may spoil the party:
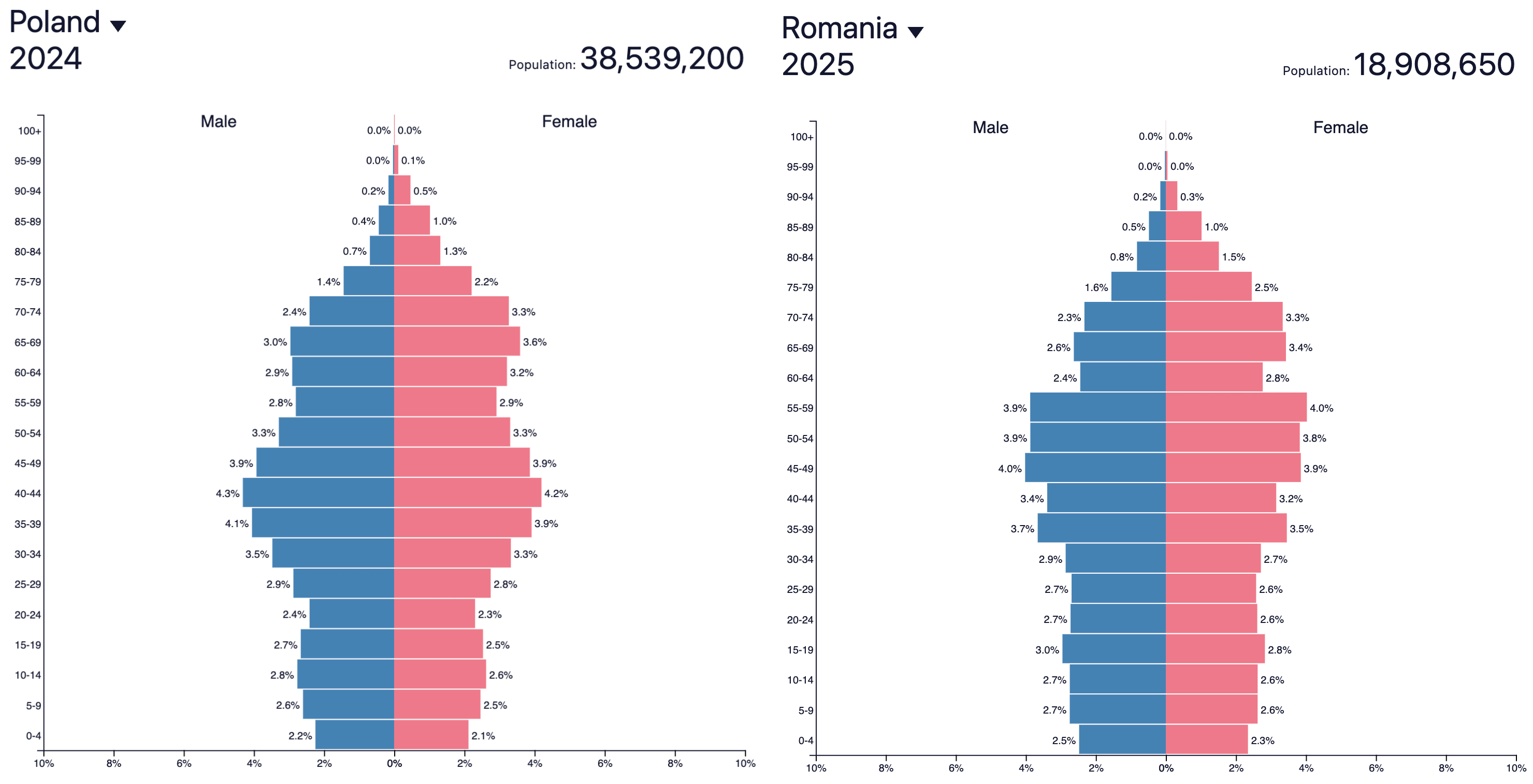
Poland and Romania’s age bulges aren’t quite in the same spot, but they may both start to look more like Japan over time with upside-down demographics (and Romania’s population has been declining for decades. Poland has been on a plateau since the 1980s and is projected to be peaking around now, followed by a decline going forward 📉).
🧪🔬 Liberty Labs 🧬 🔭
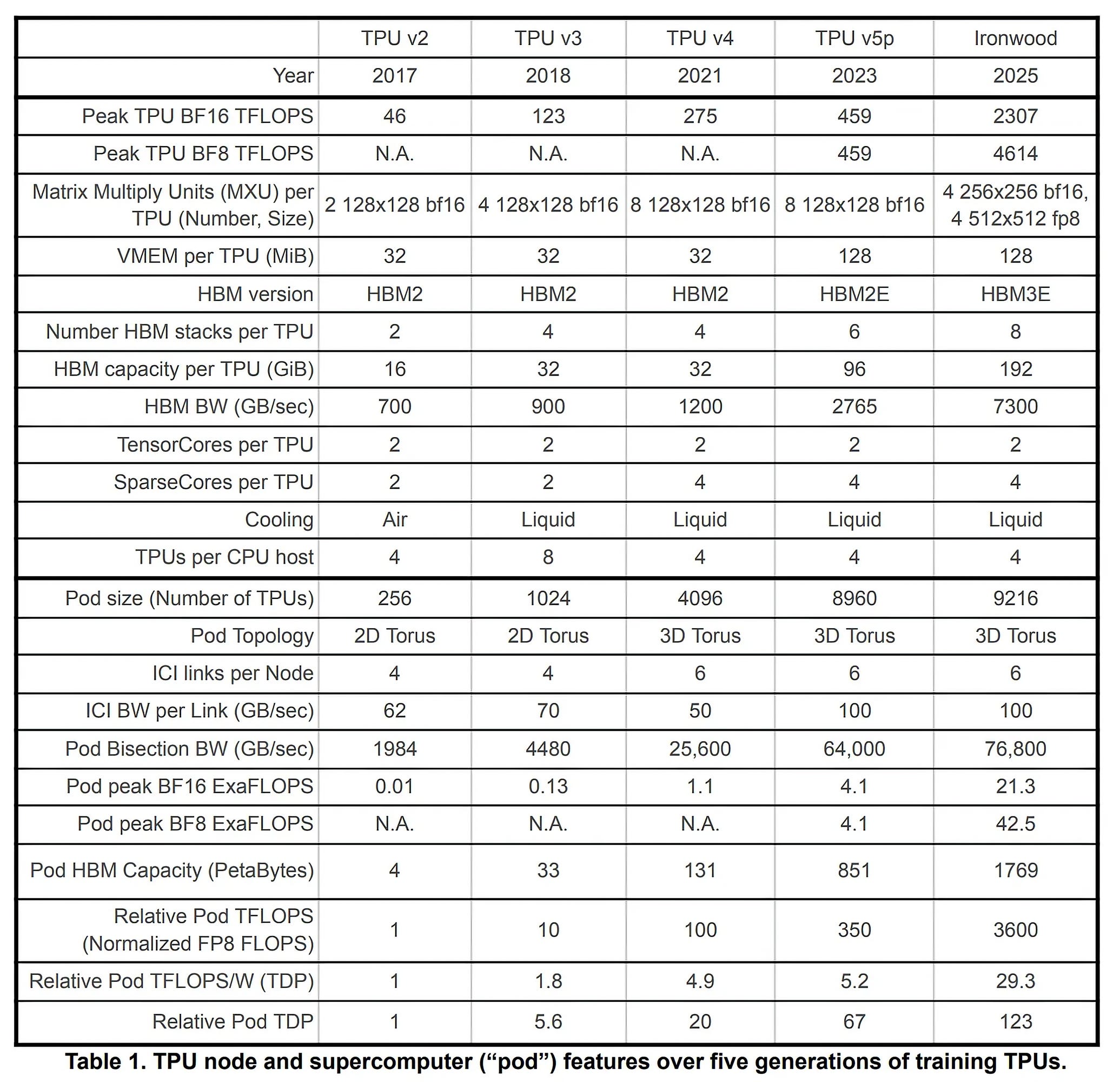
🐜 Google’s TPU Progress Over Time 📈🔍
Jeff Dean tweeted about a new paper by Google researchers called Google’s Training Supercomputers from TPU v2 to Ironwood: Architectural Stability, Scale, Resilience, Power Efficiency, and Sustainability Across Five Generations (catchy title, no?).
A few things caught my eye, and I wanted to share them with you.
Over the past 8 years:
HBM (High Bandwidth Memory) capacity and bandwidth per TPU increased ~10X
Performance per Watt rose ~30X
Supercomputer size and interconnect bisection bandwidth both grew ~40X
Directly-addressable shared (supercomputer-level) HBM memory expanded ~400x, from 4 terabytes in TPU v2 to 1.77 petabytes in Ironwood, a new record for AI supercomputers
Peak performance per TPU advanced a remarkable ~100X, from 46 BF16 TFLOPS in TPU v2 to 4614 FP8 TFLOPS in Ironwood (or ~50X for BF16 at 2307 TFLOPS)
Peak supercomputer performance jumped ~3600X, an impressive compound annual growth rate of nearly 100% despite losing Dennard scaling and Moore’s Law.
That’s a lot of Xs!
The paper also explicitly says performance per watt has become more important than performance per TCO because new data centers are increasingly power-limited. Ironwood is shown as a major leap: about 29.3x TPU v2’s peak performance per TDP watt, and roughly 6x TPU v5p’s level.
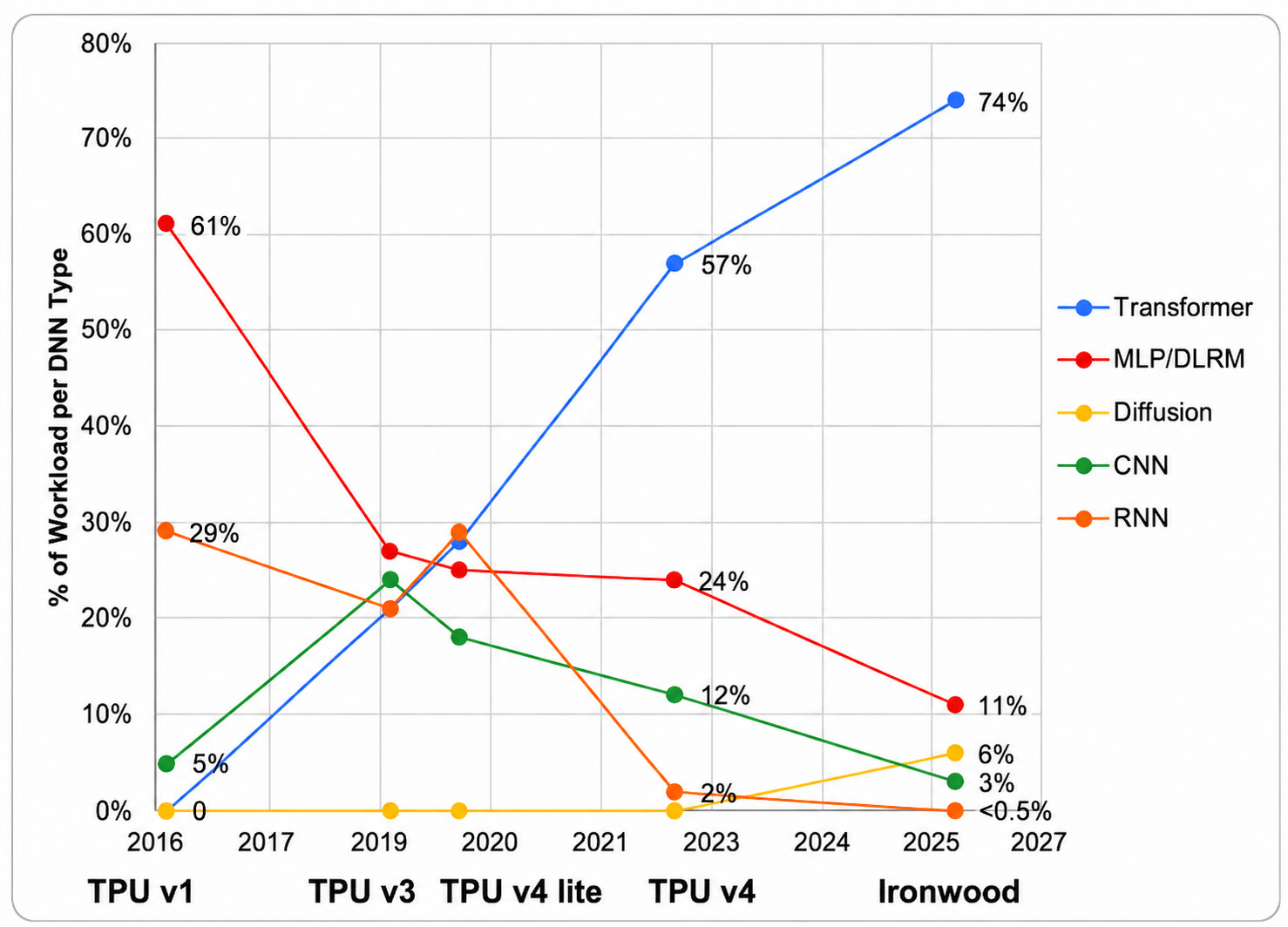
Also interesting is the change in workloads over time, with the rise and dominance of the transformer over other architectures.
Today, variations of Transformer dominate Google workloads. Despite the potential downside of domain specific architectures becoming mismatched to latest DNN trends over the 2–3 years it takes to design, fabricate, and deploy an accelerator, the original TPU v2 microarchitecture demonstrated long-term viability in this fast moving field. Architectural stability reduces the difficulty of optimizing software and models for new TPUs [...]
In 2016 DNNs were dominated by MLPs at 61%, while in 2019-2020 DNN types were relatively equally balanced. Since 2016, RNNs have practically disappeared (<0.5%), and Diffusion models are now larger than CNNs. The Transformer paper wasn’t published till December 2017, yet just 15 months later it was already 21% of Google’s production workload. In 2026 DNN workloads are imbalanced again, with the dominant DNN being Transformer at 74%
The takeaway is a bit counterintuitive. Betting on a stable microarchitecture across five generations instead of chasing each new DNN trend was the winning move, because it let software and models optimize against a fixed target even as workloads flipped from MLPs (61% in 2016) to Transformers (74% in 2026).
🗣️🎙️📝 Fluid Voice: A Free, Fast & Accurate Voice-to-Text Mac App

For a long time, I've been using SuperWhisper as my voice-to-text app. It allows you to use very powerful voice models based on OpenAI’s Whisper, but it's a paid app, and the interface isn't always the best.
I recently started using Fluid Voice, which is a free and open-source native Mac app that is claimed to be very fast and very accurate. It’s also private because the computing is on your Mac, not in the cloud.
I gave it a try, and so far I'm impressed.
These words you’re reading are being dictated right now, and there are almost no transcription errors. As I speak, the words appear pretty much in real time in a little floating window, so that I can know if the model is understanding what I'm saying.
You can even do file transcription by dragging & dropping an audio file in the app, and you get a full transcript processed locally on your computer, for free.

The website clearly says Fluid will be “Free forever” so I don’t think this is a bait & switch. But you never know…
If you’re on a Mac and could use an upgrade over MacOS’s built-in dictation, give it a try:
🌐 Fluid Voice by Altic (Free & Open Source)
There are features that I haven’t tried: You can have an LLM do some post-processing on what you dictate, and you can use it in ‘command mode’ and ask it by voice to do things on your computer.
You can select various voice models that have different trade-offs between speed, accuracy, and memory use (the list has models by OpenAI, Cohere, Nvidia, or the Apple built-in model). So far, I’ve only been using the recommended model, which is Nvidia’s Parakeet TDT v2, a 600-million-parameter model, and it’s great. Nvidia really cooked with this one.
The app even has stats for nerds like me:
I just started using it, so there isn't much yet, and I know I tend to resort to habit and start typing again because I'm not used to dictation. But this software is so fast and accurate that I may start dictating more stuff. One more tool in the toolbox 🧰
Amazon’s Robots Are Learning to Take Orders… In Plain English 🗣️🛒📦

You may not yet be seeing a lot of robots out and about, but inside Amazon’s warehouses, they’ve been taking over more and more of the work. Soon, they may be able to understand when people talk to them:
Amazon has announced a new version of its fully autonomous warehouse robot, Proteus, that will interact using language instead of code. The expanded capabilities come as part of a growing pivot toward automation as the e-commerce giant replaces its human workers with robots.
Amazon says the AI-powered upgrade means its human employees can assign the robot tasks in the same way they’d communicate with colleagues. Previously, workers would need to use specialized software to direct the floor-level, tortoise-like systems, which are designed for heavy lifting and moving large carts throughout Amazon’s warehouses. (Source)
For now, they’re still in the lab, but there are plans to start deploying it in Europe in 1H27.
Amazon publicized crossing ~1 million warehouse robots in 2025 (reportedly approaching parity with its human workforce). Packages handled per worker have gone from ~175 in 2016 to ~3,870 in 2025.
How long until there are 2 robots for every human worker? 5:1? 10:1? 🤔
🎨 🎭 Liberty Studio 👩🎨 🎥

🎞️🎨 Learning to Notice Color: Tuning a Film With Three Beams of Light
I’ve been trying to notice the use of color more lately, and it’s been useful that I’ve been rewatching a mix of older films and newer films.
For example, I recently watched The Fugitive (1993) with my kids, and Villeneuve’s Dune (2021) with my older boy, and The Sting (1973) with Paul Newman and Robert Redford. Three different eras and very different looks.
So I’ve been trying to learn about how they get that certain “film” look that you don’t get if you just pick up a camera and film stuff.
Two terms often get used interchangeably, but they’re doing different jobs:
Color correction is the technical pass: balancing every shot so they match, fixing exposure and white balance, making sure the actor’s face doesn’t shift green when you cut from the wide to the close-up.
Color grading is the creative pass on top: the washed-out palette of a war film, the warm glow that tells your brain “this is a flashback.”
Correction is continuity.
Grading is mood.
In the digital era, images are just data, 0101101010101. Software allows you to adjust EVERYTHING.
You sit in front of something like DaVinci Resolve and push the image around until it looks right. A shot doesn’t match the one before it? There are tools that will match them for you off a reference frame.
Want a deeper blue sky but the skin tones left alone? Draw a mask. Want to desaturate the whole background while keeping one red dress vivid, and have that mask follow the dress as the actor walks across the room? No prob, man.
But watching older films made me wonder what they did when they were still splicing film by hand and editing with razor blades.
Back in the photochemical era, the look you got was a physical property of the print, set by how much red, green, and blue light a lab shone through the negative when making each copy. 🎞️

After the negative was cut together (literally), a specialist called a color timer studied it on a machine like a Hazeltine (which turned the negative into a positive) and dialed in three numbers per shot, one each for red, green, and blue, usually on a 1-to-50 scale.
Twenty-five across the board was the theoretical middle, except every lab was calibrated a little differently, so the same numbers gave you slightly different results from one lab to the next. (the 🐐 Roger Deakins ran his own normal closer to 29-31-29 because he liked a heavier negative).
Then the lab made a print, everyone sat in a theater and watched it, somebody said “the close-up’s too green” and “the sunset doesn’t match the wide,” and the timer changed the numbers and printed it again. That first approved version was the answer print, and you went around the loop until it was signed off.
But those adjustments were global. You could make a whole shot warmer or cooler, lighter or darker, push it toward magenta or pull it off green. You could NOT brighten just the actor’s face, or deepen just the sky, or keep one red dress vivid while everything around it went grey. No masks, no tracking, no secondaries.
The discipline had to be upstream, on set. Film stock, filters, gels, exposure, lighting, wardrobe, production design. The lab could balance and polish what you handed it, but it couldn’t remake it into something else. “Fix it in post” is a fairly recent luxury.
When the Coen bros and Deakins wanted a dusty Depression-era gold for O Brother, Where Art Thou? (2000), the lush green Mississippi summer they captured on film was a problem.
")
Deakins tested photochemical approaches, including bleach-bypass and bi-pack processes, but they weren’t selective enough. So the negative was scanned and the film was graded digitally, letting Deakins and Cinesite colorist Julius Friede target the greens of trees and grass and turn them into dry browns and yellows. It’s usually credited as the first Hollywood feature to have every frame digitally color-graded as a full digital intermediate.
And it’s a great example of using color creatively because the look that everyone remembers is that gold/brown, but it *wasn’t* in front of the lens on that day.
")

