

542: Nvidia's Velocity, State of AI, Duolingo, Taiwan + Kuiper?, Google’s FireSat, Microsoft Capex, China's VCs, Mood Tracking, and Margins
"spending time with friends is hard to beat!"

In all affairs it's a healthy thing now and then to hang a question mark on the things you have long taken for granted.
—Bertrand Russell

🗓️🍾2️⃣0️⃣2️⃣5️⃣ 🎉 Guess who’s back?
I hope you had a pleasant New Year. I spent a lot of time with my family, traveled to visit my parents, went to a few parties, and hosted a gathering in our house. It was fun, but now I kind of need to retreat to my introvert sanctuary and recharge my batteries.
In my mind, January feels more like the middle of the year — for some reason my brain is still imprinted on the school calendar, where the real switchover happens around the end of August.
But a new calendar year is still a good opportunity to reflect a bit.
I’ve shared my mood-tracker results on this steamboat for a few years (above, from an app called Daylio). Looking back, 2024 had the highest number of five-star days (⭐️⭐️⭐️⭐️⭐️/⭐️⭐️⭐️⭐️⭐️) since I began tracking my mood daily four years ago. The best month was October, likely because that’s when the OSV offsite took place (spending time with friends is hard to beat!).
I feel fortunate that my mood is very stable. I seem to have a set point around 4/5. I’ve seen other people post these reports — and while mood self-assessment is subjective — it's clear that most people's emotions tend to be more volatile, with many experiencing lower baselines.
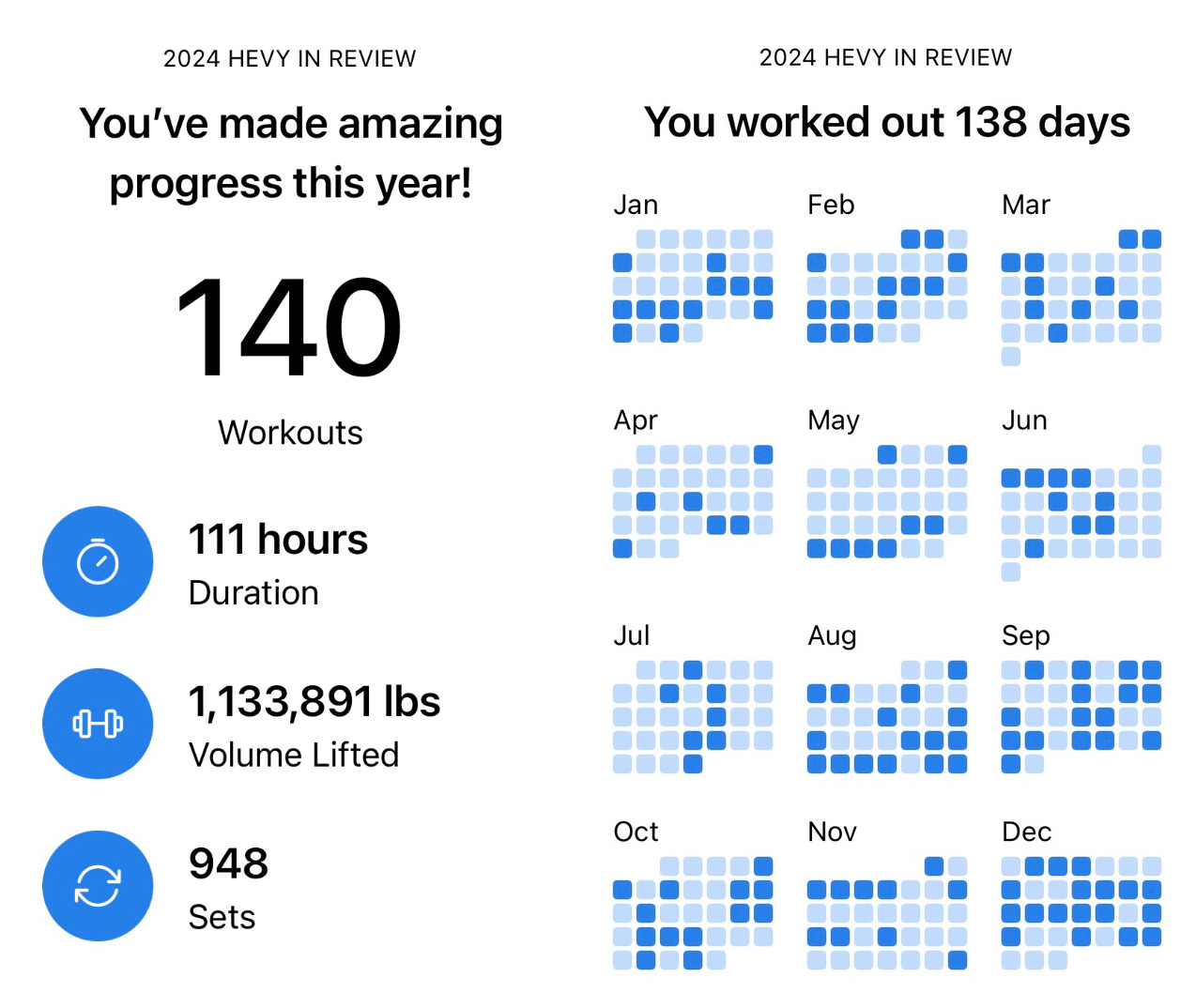
💪🏋️♂️ I've also started tracking my strength training efforts (above, tracked with the Hevy app). My basement gym, which I've written about a few times, got plenty of use. Getting the power rack and barbell made a big difference.
For 2025, my goal is to improve consistency. While I can't always stick to a fixed schedule, I want to avoid the long gaps I had in April, May, and July 2024.
💚 🥃 🙏☺️ If you are a free sub, I hope you’ll decide to become a paid supporter in 2025:
🏦 💰 Business & Investing 💳 💴

📲💎🏆🏅👩🏻🏫 Duolingo and Gamification: When Learning Feels Like Play 🎮
I’ve known about Duolingo for a long time, but never paid much attention to it until recently.
I think I have a blind spot for languages — I think of myself as bad with languages because I had such a hard time with them in school. But now that I think of it, I do make a living in my second language (English).
The real issue wasn't French, English, or Spanish... it was school.
What prompted me to think about this was my 10-year-old boy asking if he could try Duolingo. We went to a New Year’s Eve party with a bunch of Spanish-speaking friends, and I think that inspired him to try to learn some Spanish.
It was impressive to see him spend over an hour learning vocabulary the first day and just as much the next. Trust me, this doesn’t happen with his regular school homework…
While I’m sure there’s a honeymoon effect and most users eventually drop off, playing with the app myself, I was impressed by how good they are at all this behavioral gamification stuff. If you want to learn about the topic, don’t get a book, just download this app!
They’ve got it all — streaks (I’m sure you’ve seen that Jerry Seinfeld interview), high scores and leaderboards, social elements (comparing yourself with friends), cute characters celebrating your successes and giving you sad eyes when you break a streak, video game-style progress through maps with checkpoints, powerups, treasure chests, etc.
And then they combine them for maximum impact: Your characters become cooler as your streak length increases, and you get XP incentives for adding friends (combining accountability and rewards), etc.
I’d much rather see this toolbox used for good than evil. ie. Not selling thousands of dollars of Candy Crush gems to “whales” who are likely gambling addicts who would otherwise be at a slot machine in a casino…
Initially, I wondered why there weren't similar apps for math and music, but then I discovered that Duolingo already offers both, along with dozens of languages.
I wonder what other useful skills could be gamified — VR welding apps? The airplane engine maintenance game? Realistic heart surgery training in an app? 🤔
The AI era just amplifies the potential for personalized tutors and further innovation in this type of app — for example, imagine voice conversational practice in a second language with an AI partner). And it may be easier to build tutors/apps in new verticals — uploading all of Buffett’s letters with the right meta-prompt may create a pretty decent tutor for teaching the basics of investing to someone new to it 🤔
Btw, don’t take this to mean that I LUUV gamification everywhere and it’s always a good idea. It can be incredibly annoying at times and I wish more apps allowed you to turn it off. But for something like learning a language, I think it works very well and I wish my kid’s school took more advantage of it for lessons and homework.
🇹🇼📡🛰️🛰️🛰️🛰️🛰️🛰️ Taiwan in talks with Amazon about Kuiper Satellite Constellation
Amazon is way behind SpaceX & Starlink, but it may get an important customer:
Taiwan’s government is in talks with Amazon’s Project Kuiper subsidiary about co-operating on satellite-based communications, as Taipei broadens its efforts to make its mobile phone and internet infrastructure less vulnerable to a potential Chinese attack.
Taiwan already has a deal with France’s Eutelsat OneWeb, but they say that it can’t provide enough capacity for the country’s needs (and, implied, it wouldn’t handle what is needed in case of invasion).
Why not Starlink?
Taiwanese government officials said separately that Starlink itself was not an option for them, adding Musk’s company would not agree to a joint venture in which Chunghwa Telecom or another Taiwanese entity held at least 50 per cent, as Taipei demands.
Officials said Musk’s extensive business interests in China and past comments on Taiwan’s political status and future were an additional hurdle.
Musk has repeatedly suggested he takes China’s side in the sovereignty dispute. Last year, he said Taiwan was an integral part of China as claimed by Beijing, adding that it was “arbitrarily” outside Beijing’s control because the US military was blocking unification.
Two years ago, he suggested the conflict be resolved by handing at least partial control of Taiwan to China.
What a strange time to be alive, when one man who isn’t the leader of a state is at the center of geopolitics around the whole globe…
Google’s FireSat: A Constellation of 50 Satellites to Detect Forest Fires EARLY with AI 🌳🌳🌳🔥🌳🔍🤖🛰️🛰️
Speaking of satellites:
Satellite imagery that’s currently used for active firefighting is available at a low resolution or only updated a few times a day, making it difficult to detect fires smaller than a soccer field [...]
FireSat is a constellation of satellites dedicated entirely to detecting and tracking wildfires. After it launches, it will provide global high resolution imagery that is updated every 20 minutes, enabling the detection of wildfires that are roughly the size of a classroom.
AI trained on fire imagery is used to detect real fires when they’re still small and reject false positives because all kinds of stuff can fool current satellites.
🏗️🤖 Microsoft’s Brad Smith: $80bn in AI Capex in Fiscal 2025 💰💰💰💰💰💰💰
This is an insane amount of money. Just being able to spend it efficiently is a feat of logistics in itself!
In FY 2025, Microsoft is on track to invest approximately $80 billion to build out AI-enabled datacenters to train AI models and deploy AI and cloud-based applications around the world. More than half of this total investment will be in the United States, reflecting our commitment to this country and our confidence in the American economy.
This is up from $53bn over the same period last year.
🇨🇳💣😰 China’s Startup/VC Ecosystem, Self-Defeating Blunder Edition

This is so stupid:
Chinese venture capitalists are hounding failed founders, pursuing personal assets and adding them to a national debtor blacklist when they fail to pay up, in moves that are throwing the country’s start-up funding ecosystem into crisis.
You don’t expect everyone to understand the startup world, but you’d think that VCs would at least make an effort to understand how the incentives have to be set up.
more than 80 per cent of venture and private equity deals in China contain redemption provisions.
They typically require companies, and often their founders as well, to buy back investors’ shares plus interest if certain targets such as an initial public offering timeline, valuation goals or revenue metrics are not met.
“It’s causing huge harm to the venture ecosystem because if a start-up fails, the founder is essentially facing asset seizures and spending restrictions,” said a Hangzhou-based lawyer who has represented several indebted entrepreneurs and asked not to be named. “They can never recover.” [...]
Once blacklisted, it is nearly impossible for individuals to start another business. They are also blocked from a range of economic activities, such as taking planes or high-speed trains, staying in hotels or leaving China. The country lacks a personal bankruptcy law, making it extremely difficult for most to escape the debts.
This is INSANE!
🧪🔬 Science & Technology 🧬 🔭
🏎️ 🤖 Velocity Edition: Nvidia’s GB300 + NVL72 + GeForce Blackwell 5090 RTX + Digits AI PC 😎
I’m almost done reading Tae Kim’s new book on the history of Nvidia (which doubles as a kind of Jensen Huang biography) — more on that when I’m done — and one of the things that stands out about the company is their obsession with speed.
Here’s an excerpt:
SINCE NVIDIA'S FOUNDING, JENSEN HAS insisted that all Nvidia employees work at the "Speed of Light." He wants their work to be constrained only by the laws of physics-not by internal politics or financial concerns. Each project must be broken down into its component tasks, and each task must have a target time-to-completion that assumes no delays, queues, or downtime. This sets the theoretical maximum: the "Speed of Light" that it is physically impossible to exceed.
"Speed of Light gets you into the market faster and makes it really, really hard, if not impossible, for your competitors to do better” [...]
Jensen would reprimand subordinates who set goals that referred to what the company had already done before or what the competitors were doing in that moment. As he saw it, he needed to prevent the kind of internal rot that he observed at other companies, where employees often manipulated their projects to provide steady and sustainable growth that would advance their individual careers, when in reality they were making only incremental improvements that actually hurt the company in the long term.
The "Speed of Light" notion ensured that Nvidia would never tolerate such sandbagging.There are many great examples in the book, and in Acquired’s Nvidia series of podcasts (🎧), showing how they were able to ship multiple products in the time it took competitors to bring one to market.
This pattern continues today. Hopper is still hot, but all eyes are on the Blackwell ramp… And before GB200 is even widely available, we’re learning of a new version with multiple improvements via friend-of-the-show Dylan Patel & his team at Semianalysis:
The B300 GPU is a brand-new tape out on the TSMC 4NP process node, IE it is a tweaked design, for the compute die. This enables the GPU to deliver 50% higher FLOPS versus the B200 on the product level. Some of this performance gain will come from 200W additional power with TDP going to 1.4KW and 1.2KW for the GB300 and B300 HGX respectively (compared to 1.2KW and 1KW for GB200 and B200).
The rest of the performance increase will come from architectural enhancements and system level enhancements such as power sloshing between CPU & GPU. Power sloshing is when the CPU and GPU dynamically reallocate power between the CPU and GPU
In addition to more FLOPS, the memory is upgraded to 12-Hi HBM3E from 8-Hi growing the HBM capacity per GPU to 288GB.
There’s also a HUGE wafer-size chip called NVL72 that effectively stitches together 72 Blackwells with tons of DPUs, CPUs (adding up to 172 TRILLION transistors! 🤯), allowing them to share memory at incredible speeds, improving the per-token economics for very long inference jobs.
It just so happens that all this is particularly useful for reasoning models like OpenAI’s new o1 Pro and o3!
As an aside, the more I think about test-time compute inference, the more I think it’ll increasingly matter how fast you generate the tokens: While humans can only read so fast, limiting the benefit of faster text token generation, there are significant advantages to faster generation for reasoning models that use their own tokens to "think through" complex problems. This is a crucial insight that isn't getting enough attention. 💡🔁🔁🔁🔁🐇🐢
Nvidia also announced the GeForce 5090 RTX gaming GPU (with 92 BILLION transistors!), which it claims is about twice as fast as the 4090.
There’s also Project Digits, a “personal AI supercomputer” about the size of a Mac Mini for $3000:
Project Digits packs Nvidia’s new GB10 Grace Blackwell Superchip [...]
Each Project Digits system comes equipped with 128GB of unified, coherent memory (by comparison, a good laptop might have 16GB or 32GB of RAM) and up to 4TB of NVMe storage. For even more demanding applications, two Project Digits systems can be linked together to handle models with up to 405 billion parameters (Meta’s best model, Llama 3.1, has 405 billion parameters).
The GB10 chip delivers up to 1 petaflop of AI performance at FP4 precision, and the system features Nvidia’s latest-generation CUDA cores and fifth-generation Tensor Cores, connected via NVLink-C2C to a Grace CPU containing 20 power-efficient Arm-based cores. MediaTek, known for their Arm-based chip designs, collaborated on the GB10’s development to optimize its power efficiency and performance.
What’s neat is that because it’s the same architecture as the data-center GPUs, researchers can run the same software stack locally as they would in the cloud. It even runs Nvidia’s Linux-based DGX OS.
Blackwell is remarkable in all its physical manifestations, but thanks to the relentless pace, we'll likely be discussing Nvidia's Rubin before we've fully caught up on GB300 & co...
This is incredible velocity for *hardware* products.
And here's the kicker — it's not just about designing new and better GPU chips at a high cadence. Nvidia is far more than a semiconductor company. The silicon is just one part of incredibly complex systems with thousands of parts and sprawling supply chains. Even the hardware would be useless without the incredibly complex software that pairs with it.
Everything needs to come together just right for the lights to turn on.
What a feat of coordination and engineering!
🤖👀 The State of AI, Looking Back at 2024 🗓️🤔

Here’s Jensen confirming what everybody’s been talking about: The 3rd scaling “law”, test-time scaling, has been added to the stack and will help keep pushing AI ahead.
So much has happened in the past year. Here are two of my favorite overviews of the state of things at the end of 2024:
Here are key highlights from both. First, Willison:
LLM prices crashed, thanks to competition and increased efficiency
The past twelve months have seen a dramatic collapse in the cost of running a prompt through the top tier hosted LLMs.
In December 2023 (here’s the Internet Archive for the OpenAI pricing page) OpenAI were charging $30/million input tokens for GPT-4, $10/mTok for the then-new GPT-4 Turbo and $1/mTok for GPT-3.5 Turbo.
Today $30/mTok gets you OpenAI’s most expensive model, o1. GPT-4o is $2.50 (12x cheaper than GPT-4) and GPT-4o mini is $0.15/mTok—nearly 7x cheaper than GPT-3.5 and massively more capable.
Countering a popular narrative on synthetic data:
Synthetic training data works great
An idea that surprisingly seems to have stuck in the public consciousness is that of “model collapse”. This was first described in the paper ‘The Curse of Recursion: Training on Generated Data Makes Models Forget’ in May 2023, and repeated in Nature in July 2024 with the more eye-catching headline ‘AI models collapse when trained on recursively generated data’.
The idea is seductive: as the internet floods with AI-generated slop the models themselves will degenerate, feeding on their own output in a way that leads to their inevitable demise!
That’s clearly not happening. Instead, we are seeing AI labs increasingly train on synthetic content—deliberately creating artificial data to help steer their models in the right way.
Here’s Mollick:
At the end of last year, there was only one publicly available GPT-4/Gen2 class model, and that was GPT-4. Now there are between six and ten such models, and some of them are open weights, which means they are free for anyone to use or modify.
What a Cambrian explosion of models! I wonder how many frontier models we’ll peak (if we haven’t already), and what the stable state number will be for the longer term 🤔
o1 and o1-pro, have considerably increased power. These models spend time invisibly “thinking” - mimicking human logical problem solving - before answering questions. This approach, called test time compute, turns out to be a key to making models better at problem solving. In fact, these models are now smart enough to make meaningful contributions to research, in ways big and small.
I can’t wait for o3 to become more widely available to researchers (later this month?), and eventually to everyone.
🎨 🎭 The Arts & History 👩🎨 🎥

Do you read books? The Margins App is for you! 📚📖📲
If you read books (of course you do!), you’ll love the new Margins app.
Think of it as Goodreads if it was good. (and yes, you can import your Goodreads data)
Margins is snappy, rapidly improving, and built on modern tech.
The app lets you keep track of titles and reading time (if you want — no pressure). You can easily build a wishlist, add books you’ve already read, and discover your next read through the neat “search by vibes” discovery system.
There are all kinds of nice details: you can pick your preferred book cover from multiple options, it makes it easy to browse series, it consolidates multiple editions so you don’t get overwhelmed by the 7 different versions of the same thing, etc.
Some books are still missing because books have a particularly long tail, but they have 10s of millions and are adding them quickly. They put a lot of effort into getting very clean data on the books — that takes longer, but it’ll be much better for users over time.
Margins seems to be filling a real need from book lovers because it got to 60,000 installs in twelve days! Right now it’s iOS only, but you can sign up for the Android waiting list.

Full Disclosure: Paul Warren the founder is a friend and OSV is an investor. But we became friends through our common love of books and quality software tools. I’m not saying nice things because he’s my friend; we became friends because he’s doing such cool things! The order matters 🔄
How will margins make money? Is it free now and pay later when I’m hooked?
"What a strange time to be alive, when one man who isn’t the leader of a state is at the center of geopolitics around the whole globe…"
Modern central banks are a post WW2 concept. Private bankers once controlled the ability of states to wage war. Private arms dealers have played a similar role in some parts of the world. If history doesn't repeat, it certainly rhymes.