

561: Is OpenAI Winning the AI Race?, The Next Social Layer, Returns on Agency, China Semicap Megamerger, Retina to Brain, Nuclear Power, Andor, and Lakers Legacy
"the highest-agency hunter-gatherer"

The greatest discovery of my generation is that a human being can alter his life by altering his attitudes.
—William James
👩🏻🏫🤖🎓📚 For those who choose to take advantage of it, AI is a genius, polymathic, non-judgmental private tutor.
It’s on call 24/7 🕙🗓️
It’s free, or for the cost of a few cups of coffee, you can upgrade your genius. ☕️☕️
What does it mean when *everyone* can have a genius tutor?

This makes Returns on Agency (RoA?) inflect upward once again 📈
RoA has been increasing steadily for centuries, thanks to a series of high-leverage developments, from Gutenberg to Adam Smith to Tim Berners-Lee. Think of the possibilities for the highest-agency person you know today vs the highest-agency hunter-gatherer 20,000 years ago…
Google, the previous champion of agency, reigned for two decades. Now it’s passing the torch to AI🏅
📺 I started watching ‘Andor’ (2022, Disney+).
I’d heard enough good things from people whose taste I trust to override my “I’m so done with Star Wars” and “it’s not because something has the same name as something else I like that it’s any good” positions.
The first two episodes were pretty good, but I don’t feel like things have gotten started yet. They’re still setting the stage. I’ll let you know what I think when I’ve seen more.
🛀💭 💵 🛒📱⛏️💊 The more I think about the price of things, the weirder it all feels.
Each month, I spend more on vitamins and supplements than on music, TV, and movies combined.
Does that make sense?
It costs me more to pay someone to dig a hole in my yard than to buy a brand new iPhone.
That can’t be right…?!
💚 🥃 🙏☺️ If you’re a free sub, I hope you’ll decide to become a paid supporter in 2025:
The next best thing is to share something you enjoyed here with someone who might like it too. Drop a screenshot and a link in your group chat! 💬
🏦 💰 Liberty Capital 💳 💴

🏁🏇 OpenAI’s Lead: Temporary Surge or Durable Advantage? 🏇🏇🏇
Momentum builds on itself. There’s a real vibe that OpenAI is winning lately and may be on track to become the first new Big Tech company to emerge since Facebook in 2004.
Are they pulling ahead sustainably, in a way that will make them structurally almost impossible to catch — f.ex. like Google vs other search engines — or is it just a moment in time, with a potential reshuffling of the deck at any time?
Or maybe OpenAI will somehow snatch defeat from the jaws of victory..? 😬
I’m hearing from many people on many different channels about how much their usage has gone up, how impressed they are by it, and how they’ve switched from other AI providers to ChatGPT. The exodus from Claude and Perplexity is real. Many are also substituting a lot of their Google Search usage.
I’m even seeing early signs of the same ‘it’s addictive’ commentary, and it’s giving me flashbacks to the early days of social media and smartphones. 📲😵💫🤳
This feedback is also increasingly coming from regular people, not just early adopters, tech enthusiasts, or people with a clear business use case. I increasingly hear about ChatGPT being used as a surrogate friend/therapist.
This seems to be largely thanks to a mix of having strong models AND strong products AND a strong brand — ChatGPT has become a Schelling point when it comes to AI for regular people.
The longer ChatGPT stays in the lead, the more habit-forming it is for its hundreds of millions of users and the harder it’ll be for the competition to win them over. They won’t change their habits unless something else is *much* better.
There are other very strong models out there (looking at you, Gemini 2.5 Pro), but they tend to be wrapped in inferior products and lack the pure-play, singular brand identity.
This latter point may be underrated.
Most people prefer clarity of purpose. Imagine if all of Meta’s properties were hosted in the same app — Facebook + Instagram + WhatsApp + Messenger + Threads.
You can argue that many of these are already becoming a bit crowded and multi-purpose (Insta is about photos and videos and stories and reels and messaging…). A similar thing happens as Google tries to sprinkle Gemini everywhere. You have to figure out if you want to go to the Gemini standalone app (which few people have), or use it via Google Search, AI Studio, NotebookLM, Gmail, Google Docs, etc.
When you go to ChatGPT, you know exactly why you’re going there, and nothing else gets in your way (for now, anyway…).
Anthropic’s Claude also has this clarity, but the user-facing product isn’t nearly as good, even if the underlying LLM engine is strong. The velocity of improvements is much lower:
Web search only came out recently, and only in some countries
Voice mode is inferior
No native image generation
No live video/vision
The app UX isn’t as good
There’s no good desktop app, and so on…
Even ChatGPT’s recent “memory” feature feels cleaner in a single-purpose app. If Google comes out with the same thing and decides to use everything they know about you from Search and Gmail (which may need to be opt-in because users never assumed this would be used this way), I’ll be curious to see how well it works. There’s *a lot* more noise in my inbox and search history than in my chatbot logs.
💃 The Personality Advantage/Usage Feedback Loop 🔁🤖
One advantage of ChatGPT is its massive user base. That provides them more usage feedback to tune their products than anyone else (aka reinforcement learning from human feedback, RLHF).
It’s a bit like how Google has so much more scale in search, even if Bing had an *identical* algorithm and code base, the signals from usage would rapidly make Google better 🔍
OpenAI can run way more A/B tests and experiments and use these datapoints to tweak things. You may have seen this: You type something in ChatGPT, and you see two responses side by side with a prompt asking you which one you prefer.
There’s a similar dynamic with its hundreds of millions of users: The default policy is that they can use content submitted to ChatGPT, including prompts, responses, images, and files, to improve model performance. This gives them a firehose of real-world optimization data.
Only Business/Enterprise/Team/API users are opted out of data collection by default; all others must opt out manually via a setting under "Data Controls.”
There’s got to be a lot of useful signal here, both to fine tune and tweak the product, and because all the data generated to answer queries is “synthetic data” that competitors don’t have access to and that can be used in training runs (I’m sure they have ways to determine data quality and throw away a bunch of it).
In theory, I could see this leading ChatGPT to having a “personality” (I usually call this “flavor”) that better matches what people like than most other models, at least over time. In the short run, having a great system prompts and doing great internal RLHF can probably win (for a while, Claude had a distinctive “flavor” that many preferred).
But Anthropic is getting a small fraction of the usage signal and data that OpenAI is, so despite the better “taste” of its creators, ChatGPT has been improving faster and has caught up or surpassed it in many ways.
At least, that’s what I think when my friends tell me they are moving from Claude to ChatGPT and using it more and more…
In short:
Strong models + Strong product + Unmatched scale of user feedback & data = durable lead?What do you think?
🕸️🤖 The Next Social Layer: OpenAI’s Shot at a New Kind of Connection Engine 👩💻🧑💻
This idea is fuzzy in my brain, but I want to think it through with you. If it sparks better ideas in your mind, please let me know in the comments or by replying to this Edition’s email.
As I mentioned in Edition #559, there’s a rumor that OpenAI is working on its own “X-like social network”. There’s reportedly an early internal prototype focused on ChatGPT’s image generation with a social feed, and Sam Altman has been quietly asking for feedback.
I’ve been thinking: What would a truly AI-native, Twitter-like social network look like?
Tyler Cowen wrote:
I believe that by spending time online I will meet and befriend a collection of individuals around the world, who are pretty much exactly the people I want to be in touch with. And then I will be in touch with them regularly.
I call them “the perfect people for me.”
[…] frankly, if forced to choose, I would rather have thinner relationships with “the perfect people for me” than regular bear hugs and beer guzzlings with “people who are in the 87th percentile for me.”
If OpenAI marries ChatGPT’s personal context to an algorithmic ‘interest graph,’ it could create the first truly AI-native social layer. A new way to help match humans, not just distribute content.
From Social Media 1.0 to 4.0?🕸️💻📱🤖
To understand the context, here’s the quick & dirty history:
Twitter started with a chronological feed manually populated by following other users. What made Twitter particularly powerful was that it was built on an Interest Graph rather than a Social Graph — when people get together because of traditional social ties, they joke around, do small talk, share baby pictures and memes, etc. When they get together because they have common interests, they learn, brainstorm, mentor each other, create things, build businesses, etc.
Later, Facebook became more dominant in part because of its algorithmic feed, which Twitter (and others) also adopted.
In the next era, TikTok became massive by surfacing content from anywhere on the network, caring only about engagement. Others retrofitted their recommender algorithms to be more like that, and everything is now TikTokified.
The logic was simple: You should *always* be able to find something more engaging if you can pick from the whole network than if you only pick from the accounts that a user has manually decided to follow (YouTube’s homepage is like that too now).
The result: There’s now very little “social” about most social networks. They’re now mostly carousels for user-generated content (UGC).
This has driven most of the quality social interactions and thoughtful content underground to private group chats, Discord channels, sub-Reddit communities, and Substacks.
What’s the next evolution?
From OpenAI’s perspective, how can they make their product better and stickier for users while leaning into the very real human need for connection and finding your tribe out there in the vast online ocean?
👥👥🤝👥👥 What if OpenAI could be a Matchmaker?
ChatGPT might already know more about most of what its users care about than Google, because chatting about a topic often means revealing more bits of information than searching for it and clicking on a link.
OpenAI could use this to spin up mini-communities and shared spaces for people with similar interests.
They have the opportunity to build the Interest Graph 2.0! 🧩
If I’m constantly researching Jazz, it could offer me a feed or group chat of other jazz fans interested in similar eras and styles. Or fitness, or science-fiction, or long-term fundamental investing, or Deadwood, or J.S. Bach, whatever. Some communities may be more text-based while others may be more image & video-based (especially as AI starts to generate better video).
Maybe that looks like a subreddit with various topic-based threads and comment sections where discussion happens (with both humans and AI agents, clearly labelled? 🏷️) or like a Twitter feed where you can see things that people decide to make public.
Each community could have an automated archivist that summarizes debates, surfaces canonical links, schedules live audio jams, etc. AI would handle onboarding, moderation, spam, and de-duping so groups stay high-signal. Users could choose to appear as themselves, anonymous, or via a persistent AI-persona (“JazzCat42”) that’s transparently synthetic.
You could follow people who consistently share great stuff (both prompts and answers), send DMs, maybe even tip them. Over time, I could easily imagine that this interest-based match-making could help me find great sources of content, but most importantly, maybe even new friends.
This is not so far-fetched. I’ve met many of my closest friends on Twitter. 🐦
🐜🏭 China’s Chip Tool Megamerger: Consolidating 200 Firms into 10 🔧
China is trying to build scale in its semiconductor capital equipment industry:
China is pushing forward a major consolidation plan to restructure its fragmented semiconductor equipment sector, reportedly cutting more than 200 domestic firms down to just 10 core players.
If you want to understand just how insanely difficult this industry is to master, check this out:
The Korea Institute for International Economic Policy reports that from 2014 to 2024, China invested over CNY1.331 trillion (approx. US$182.2 billion) to localize its semiconductor sector. Yet, domestic self-reliance in chipmaking stands at only 23%, highlighting continued shortfalls in advanced manufacturing capabilities.
This is one of the second-order effects of export controls.
As long as China had access to the best Western chips and equipment, pressure to grow capabilities was always limited. Even with government mandates, companies prioritize competitiveness and profitability, so they wouldn’t abandon the best equipment in favor of inferior local versions.
This dynamic helped Western companies stay ahead: they benefited from the scale of selling to both the rest of the world *and* China—a much larger market than China alone.
This dynamic makes it hard for Huawei and the Chinese semicap supplier ecosystems to reach scale and compete on the frontier. It does help that they copy foreign tech (I wrote about Swinging the Machete vs Sprinting Up the Trail in Edition #554), but that only gives you so much expertise vs doing the R&D and going up the learning curve yourself.
🧪🔬 Liberty Labs 🧬 🔭
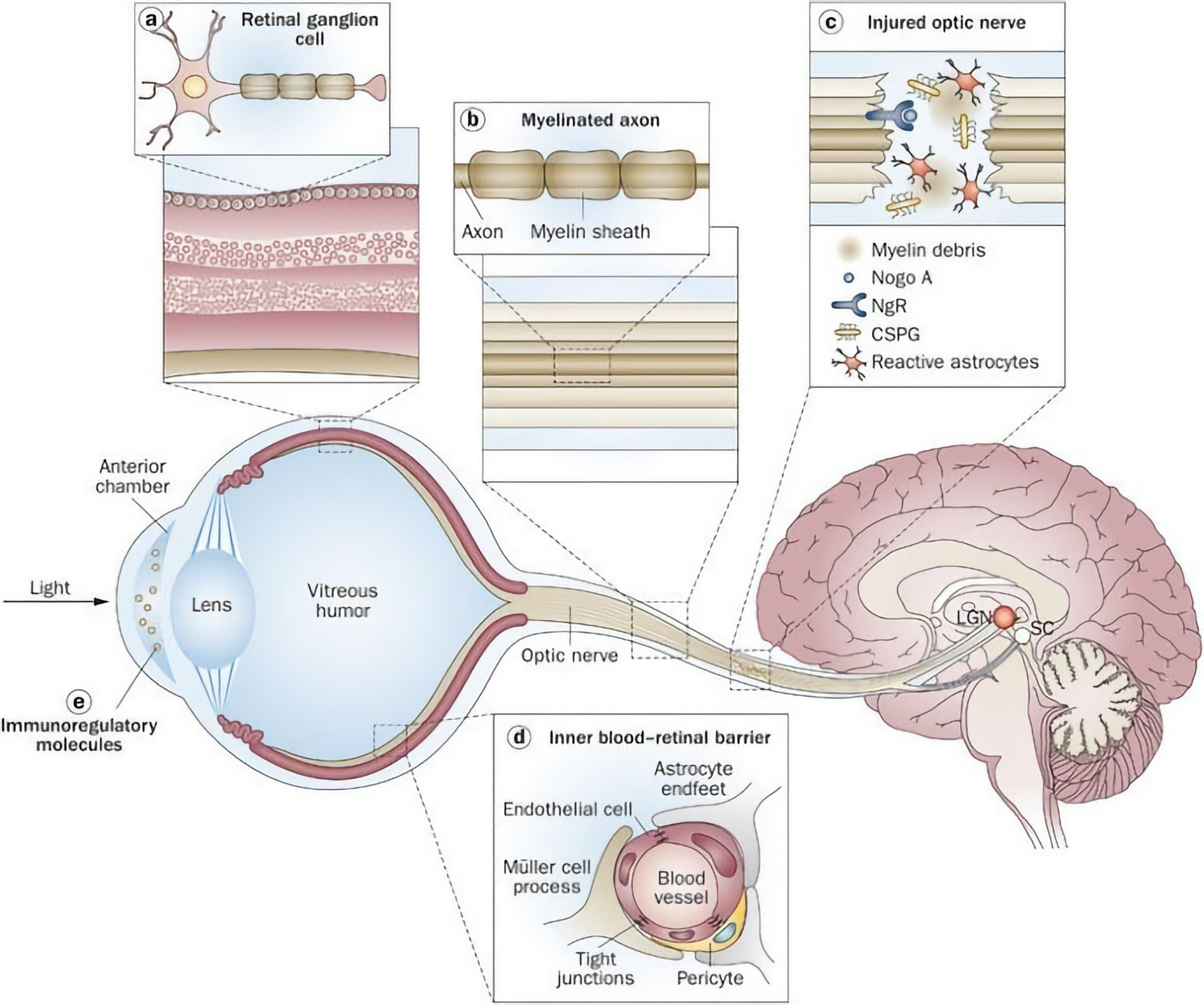
👁️👁️➡️🧠 From Retina to Brain: Our 25,000:1 Compression Vision Pipeline 🤯
Peyman Milanfar has a great tweet distilling the info from this paper:
The retina is arguably the most impressive part of the brain - it's also the only part of the brain that faces the world directly - it’s a sensor and processor in one
Consumes 50% more energy per gram than the rest of the brain.
1000:1 compression from retina to optic nerve
25000:1 from optic nerve to brain
For every 1Gb collected by the retina, 1Mb is sent to the brain thru the optic nerve and < 100bits used, at a rate of about 875Kbps. Similar to broadband internet.
These numbers are not exact, and they fluctuate from person to person and moment to moment. But they’re directionally correct, and the scope is pretty mind-blowing.
China Approves 10 New Nuclear Reactors for $27bn 🇨🇳🏗️⚛️⚛️⚛️⚛️⚛️⚛️⚛️⚛️⚛️⚛️

It's the fourth consecutive year that China has approved at least 10 new reactors (🤯).
They have 30 reactors under construction, which represents nearly half of all nuclear projects worldwide.
This most recent batch is going to be third-generation Chinese designs called Hualong One pressurized water reactors, built with close to 100% local supply chains:
On 27 April, the State Council approved 10 reactors at following sites, according to domestic news:
-Haiyang phase 3
-Xiapu phase 1
-Sanmen phase 3
-Taishan phase 2
-Fangchenggang phase 2
This is a meaningful addition. Recent numbers show that the country has “58 operable reactors with total installed capacity of 60.96 GW.”
By 2030, China is projected to become the world leader in installed nuclear capacity, beating the United States. Right now, it ranks third behind the U.S. and France.
Here’s a message to the rest of the world: Wake up! 😴⏰
🎨 🎭 Liberty Studio 👩🎨 🎥

📺 “Legacy: The True Story of the L.A. Lakers”: Great Family Business Doc Disguised as a Sports Story 🏀💸🏆
Listen, I don’t care about sports. I’ve never watched any and don’t plan to start…
But SOMEHOW!
Many of my favorite documentaries are about sports. I loved ‘The Last Dance’ about Michael Jordan. It’s a bit like how I don’t play much chess or poker, but I love books or documentaries about how the very best go about *becoming* the best. ♟️♣️
(The book ‘The Professor, the Banker, and the Suicide King’ is a good example of this)
This docuseries was recommended to me by my friend Jimmy Soni (💚 🥃✍️📚), and I really enjoyed it.
What makes it not just a history of a bunch of basketball games is that they focus heavily on what it takes to successfully run a major sports franchise. A lot is about strategy, marketing, the complexities of family businesses and personality clashes with coaches, star players, and siblings. There are so many moving pieces ⚙️, ups and downs, tears of joy and tears of sadness.
(That Kobe part! 😢)
Even if you don’t care about sportsball, you may like this one!
Regarding your point on the social/interest potential of AI, I can definitely see it being a step change from what’s currently available.
You also mentioned everyone having their own tutor — and while it might sound a bit hand-wavy, it really feels like OpenAI is edging close to becoming all of these things at once.
The “tutor” could recommend communities to join — I’ve even seen o3 say something like, “Would you like me to highlight a few forums where this topic is being discussed?” It wouldn’t all have to live in-house, though there would be obvious advantages if it did.
The same idea could extend to jobs. How much more pleasant (and efficient) would it be to have ChatGPT suggest roles, or even make an introduction?
Lately, I’ve noticed ChatGPT taking more initiative, asking if I’d like to move on to the next logical step. I often find myself responding, “Yes please, that would be great!”
I really liked your framing around “returns on agency.” But I wonder: will self-agency be the key differentiator in this new paradigm, or will it matter more that we trust the ghost in the machine to steer us well? Maybe will turn out to be the ultimate AI agent…
Your point on Meta combining all its apps or OpenAI’s social media interest/matching potential made me think of Elon and Grok. I know that he wants X to become the “everything app”. If he succeeds, which I am not going to put past Elon, could we see Grok skyrocketing up there?
I already see so many users using Grok to verify tweets. I feel like it hallucinates a lot , but untapped potential there?