

610: Jensen on Everything, Apple + Google, Claude Cowork, Jim O'Shaughnessy & Jimmy Soni, GPT Solved 3 Erdős Problems, Software Guitar Amps, and NYPD Blue
"Lovers of peace, freedom, and progress"

You can’t use up creativity. The more you use, the more you have.
— Maya Angelou
🎭🔁☀️⛈️ Optimism AND pessimism are largely self-fulfilling.
I’ve written many times about how everything we create starts with a vision or an idea, and if your head is filled with “it’s pointless”, “it doesn’t matter”, “it’ll never work”, and “I can’t do it”, odds are you’ll prove Henry Ford right:
“Whether you think you can or think you can’t, you’re right.”That’s why merchants of pessimism can have a massive and insidious impact on the world. It’s always hard to trace cause and effect, but infect millions of minds with cynicism and it’ll shape how they steer their lives across decisions, large and small.
Conversely, purveyors of positive thoughts can also have a very large impact through ideas and words alone. I’m currently reading ‘The Splendid and the Vile’, which is about Churchill’s first year as prime minister, just as the Nazis started to bomb the UK and threaten invasion. The book makes clear that while his decisions mattered, it was his words and ideas that changed how millions of people saw themselves and decided to act in the following years. Those same words helped convince the U.S. that all was not lost and they should provide support.
My friend MBI (🇧🇩🇺🇸) recently shared this graph, and I couldn’t help but think about this kind of reflexivity:
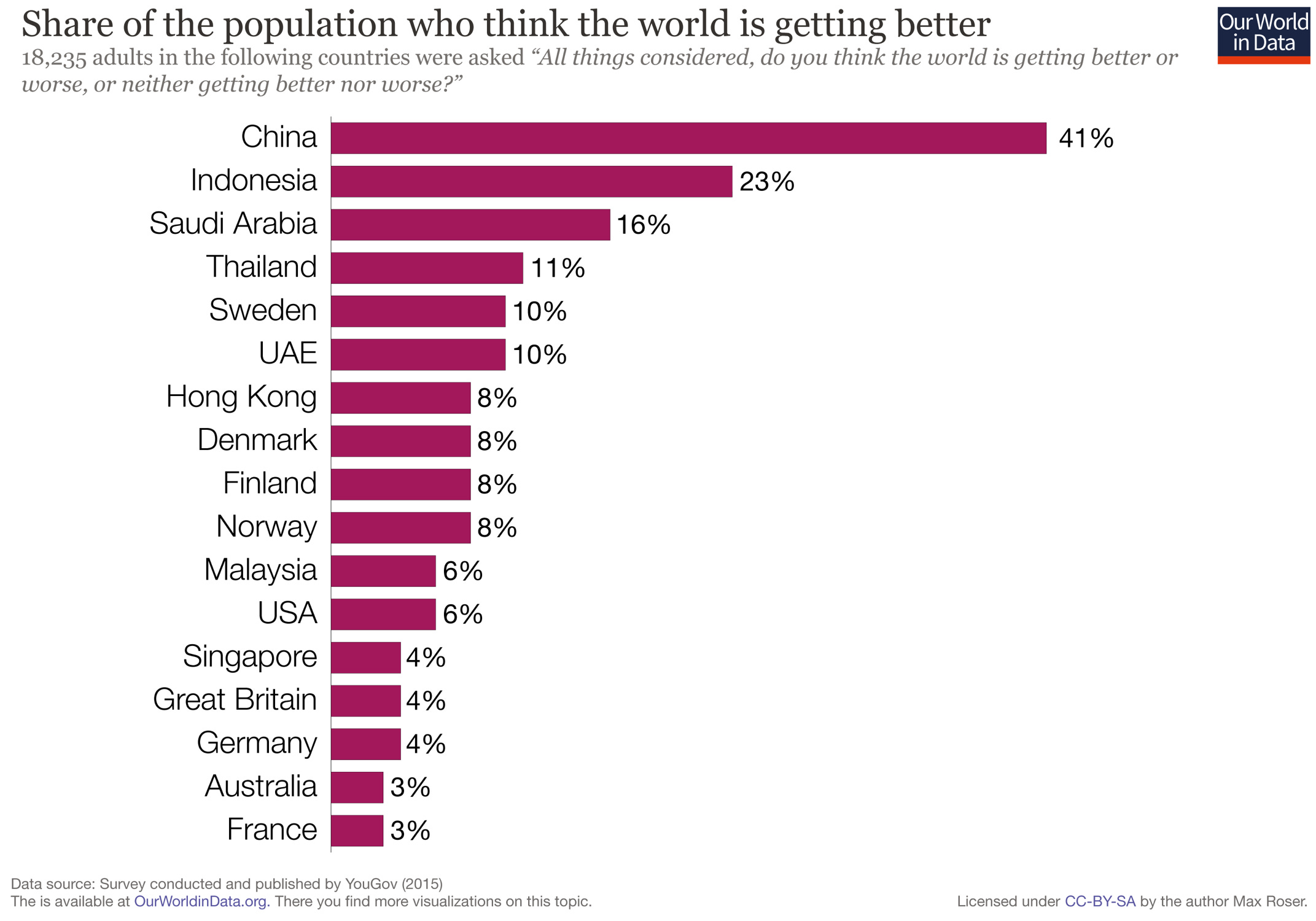
More details on the methodology and other interesting graphs can be found here.
Common misconceptions include the belief that global extreme poverty is rising and that child mortality in poor countries is rising.
We are not just negative about the past, we are also pessimistic about the future
If we ask people about what is possible for the world, then most of us answer ‘not much’. This chart documents the survey answers to the question “over the next 15 years, do you think living conditions for people around the world get better or worse?”.
More than half of the people expect stagnation or that things will be getting worse. Fortunately, the places in which people currently have the worst living conditions are more optimistic about what is possible in the coming years.
On population scales, positive and negative mindsets lead to positive-sum or zero-sum thinking, and the historical results of each are very stark. Lovers of peace, freedom, and progress should champion positive-sum thinking, as it’s clear that zero-sum thinking is the soil in which authoritarianism and tyranny grow.
🛀💭😈👺I think if everyone was taught from a young age to recognize Dark Triad traits, a lot of problems would be avoided 🤔
I can’t know for sure, but if you took a random sample of the population and asked them about this on the sidewalk, I suspect that fewer than 15% could even name the three socially aversive traits in the Dark Triad (narcissism, machiavellianism, and psychopathy). And if you asked people to describe each in their own words, probably fewer than 5% could.
I’m teaching my kids how to recognize these toxic traits. 🛡️
In the branching decision tree of a life, having this information at the right moment can be the difference between taking a miserable path — at least for a while — and a happier one.
🔎📫💚 🥃 Exploration-as-a-service: your next favorite thing is out there, you just haven’t found it yet!
If this newsletter adds something to your week, consider becoming a paid supporter 👇
🏦 💰 Liberty Capital 💳 💴
🗣️🔮 Jensen on Everything AI: Scaling Laws, Energy, Open Source, Robotics, Biology, Employment Fears, ASICs 🤖🚀
I really enjoyed this wide-ranging interview with Jensen. He’s increasingly taken the role of Elder Tech Statesman, following in the footsteps of Steve Jobs, Bill Gates, and Jeff Bezos in past decades.
From his vantage point at the center of almost everything exciting happening in tech right now, he has a unique perspective on where things are and where they’re going. 🔭👀
Every day, he’s talking to the leaders of other large tech companies and the less glamorous but very important suppliers that keep everything humming. He’s also seeing what’s in the lab both at Nvidia and at its partners, so it’s hard to find someone with more of a finger on the pulse, and with a clearer windshield to see what is coming in the near future (of course, Jensen has also always been very optimistic and bullish, so we should calibrate for that).
In any case, here are some of my highlights from what he said in this interview:
DeepSeek is “The Single Greatest Contribution to American AI” 🇨🇳
Jensen: Let’s face it, DeepSeek was probably the single most important paper that most Silicon Valley researchers read from in the last couple of years.
Sarah: It was the only thing that felt frontier that was open in years.
Jensen: That’s right, which is the value of open source again. Literally DeepSeek benefited American startups and American AI labs all over.
Sarah: And infrastructure companies.
Jensen: And infrastructure companies all over, probably the single greatest contribution to American AI last year.
And so if you said this out loud, of course people kind of shudder that American AI is actually learning from and benefiting from AI from other nations. But why would that be surprising? AI researchers all over America are Chinese natives and come from different countries. We benefit from every country, we benefit from every researcher. And all of the world’s ideas don’t have to come from the United States.
DeepSeek certainly shook up the US labs, and Sam Altman specifically cited it as a reason why they decided to create and release GPT-OSS. It’s solid, but probably due for an update in the coming months if it doesn’t want to fall too far behind the Chinese open models.
The Hinton Radiology Paradox 🩻
Jensen: And one of my favorites is, I love Geoff Hinton. He said, you know, some five, six, seven years ago that in five years’ time, AI will completely revolutionize radiology, that every single radiology application will be powered by AI and that radiologists will no longer be needed, and that he would advise the first profession not to go into is radiology.
And he’s absolutely right. 100% of radiology applications are now AI-powered. That’s completely true. And in some eight years’ time, it has now completely pervaded radiology. However, what’s interesting is that the number of radiologists increased.
And so now the question is why. And this is where the [distinction] between task versus purpose of a job [matters]. A job has tasks and has purpose. And in the case of a radiologist, the task is to study scans, but the purpose is to diagnose disease.
This is crucial for understanding both the disruptions of the past AND those that are coming.
Too few people understand that the way you do something is a means to an end, and it’s that end that matters. All kinds of constraints will help define that “how”, and if these change, it’s irrational to stick with how things used to be done.
Just look at DNA sequencing. Back when it used to be super expensive, it was done rarely, and only for a small number of base pairs. Now that the cost has fallen by many orders of magnitude, a lot more sequencing is happening, for all kinds of uses that nobody would have even considered before.
I suspect that as the cost of various things falls — MRI scans, creating software, etc — the consumption of many of them will go through the roof (Jevons Paradox).
But not all of them, and not all of them will have a dynamic similar to radiology, so it’s still very hard to predict the future. But it won’t be as simple as either the doomers or megabulls believe.
AI usage at Nvidia and ‘Task vs. Purpose’ framework 💾
Jensen: Also interesting, we use Cursor here, and we use Cursor pervasively here. Every engineer uses it. And the number of engineers—you just mentioned it—the number of people we’re hiring today is just incredible. Monday has come to work on NVIDIA Day, and why is that? This is now the purpose and the task.
The purpose of a software engineer is to solve known problems and to find new problems to solve. Coding is one of the tasks. And so if the purpose is not coding—if your purpose literally is coding, somebody tells you what to do, you code it. Maybe you’re going to get replaced by the AI, but most of our software engineers—all of our software engineers—their goal is to solve problems.
And it turns out we have so many problems in the company, and we have so many undiscovered problems. And so the more time they have to go explore undiscovered problems, the better off we are as a company. Nothing would give me more joy than if none of them are coding at all. They’re just solving problems. You see what I’m saying?
And so I think this framework of purpose versus task is really good for everybody to apply. For example, somebody who’s a waiter, their job is not to take the order. Their job is so that we have a great experience. And if some AI is taking the order, their job—or even delivering the food—their job is still helping us have a great experience. They would reshape their jobs accordingly.
A company full of engineers that don’t code!
The question that all these engineers are no doubt asking themselves is: Will “exploring for undiscovered problems” also be automated?
Will the smartest engineers get a ton of leverage, but the least experienced, or people who simply aren’t geniuses... Are they going to be left behind?
Will large companies have a small team of geniuses overseeing and guiding millions of AI agents? 🤔
Inference tokens: Profitable and growing exponentially 💰
Jensen: I’m really pleased and probably a little bit surprised, in fact, that token generation rate for inference, especially reasoning tokens, are growing so fast, several exponentials at the same time, it seems.
And I’m so pleased that these tokens are now profitable, that people are generating—I heard somebody, I heard today that Open Evidence, speaking of them, 90% gross margins. I mean, those are very profitable tokens. And so they’re obviously doing very profitable, very valuable work. Cursor, their margins are great. Claude’s margins are great. For the enterprise use of OpenAI, their margins are great.
So anyways, it’s really terrific to see that we’re now generating tokens that are sufficiently good, so good in value that people are willing to pay good money for.
Any process that grows several exponentials at the same time for a while ends up changing the world. That’s a given.
The question is: How long and how fast?
Even if these tokens have great unit economics, there’s massive investment in future capacity that may overshoot demand at some point. Maybe soon, maybe in a long time, but any such fast-moving field never stays in perfect equilibrium forever. It’s a question of ‘when’, not ‘if’ ⏳
The ChatGPT moment for biology and material science 🧬
Jensen: I think several industries are going to experience their ChatGPT moment. I believe that multimodality and very long context is going to enable, of course, really, really cool chatbots. But the basic architecture, that in combination with breakthroughs in synthetic data generation, is going to help create the ChatGPT moment for digital biology. That moment is coming.
I think we're good at protein understanding. Now, multi-protein understanding is coming online.
I think that the protein understanding is advancing very quickly. Now protein generation is going to advance very quickly, ChatGPT moment proteins.
And then, of course, chemical understanding and chemical generation, and then protein chemical confirmation, understanding, and generation. [...]
AI is a technology that understands information. And there's human information, and so we oftentimes think about AI as a chatbot. But remember, there's biological information, there's chemical information, there's physical information, information of all kinds. There's financial information, there's healthcare information, there's information of all modalities, all kinds.
That’s very exciting, and I haven’t seen as much progress there as I expected. But things are bound to go non-linear, and once the floodgates open, it could get quite interesting quite fast.
This is because progress builds on progress, so once some new tool for biology is both general enough and powerful enough, it should unlock a lot of progress, in the same way that GPT-3.5 and GPT-4 made a whole ecosystem bloom around them.
Consumer vs Enterprise expectations 🛒📁
Jensen: in the case of AI for consumers, if it works 90% of the time, you’re delighted, you’re mind blown. If it works 80% of the time, you’re satisfied. In the case of most industrial and physical AIs, if it works 90% of the time, nobody cares about that. They only care about the 10% that it fails, basically 100% dissatisfaction. And so you’ve got to take it to 99.9999.
So the core technology might be able to get you to 99% and then a vertical solution provider like a Caterpillar or somebody, they could take that core technology and make it 99.999% great.
This is something to remember when it comes to highly specialized and complex enterprise software that is used for mission-critical stuff. Maybe you can save a little money by going with something that was AI-coded, but if there’s a problem and your whole business grinds to a halt and you give a bad experience to customers, the cost may be much higher than whatever you saved 😅
Nvidia’s More General GPUs vs ASICs:
Jensen: The reason why we are so dedicated to a programmable architecture versus a fixed architecture—remember a long time ago, a CNN chip came along and they said NVIDIA’s done. And then the transformer chip came and NVIDIA was done. And the benefit of these dedicated ASICs, of course, it could perform a job really, really well.
And transformers is a much more universal AI network. But the transformers, the species of it is growing incredibly. The attention mechanism, how it thinks about context, diffusion versus autoregressive. And so the architecture of transformers is in fact changing very rapidly. And over the next several years, it’s likely to change tremendously. And so we dedicate ourselves to an architecture that’s flexible for this reason so that we can, on the one hand, adapt with—
Remember, because Moore’s Law is largely over, transistor benefit is only 10% maybe a couple of years. And yet we would like to have hundreds of X every year. And so the benefit is actually all in algorithms. And an architecture that enables any algorithm is likely going to be the best one because the transistor didn’t advance that much.
And so I think our dedication to programmability is number one for that reason. We have so much optimism for innovation in algorithms and innovation in software that we protect our programmability for that reason.
The second thing is by protecting this architecture, our install base is really large. When a software engineer wants to optimize their algorithm, they want to make sure that it doesn’t run on just this one little cloud or this one little stack. They want it to run on as many computers as possible. So the fact that we protect our architecture compatibility, then flash attention runs everywhere. So SSMs run everywhere. Diffusion runs everywhere. Auto-regression runs everywhere. It doesn’t matter what you want to do. CNN still runs everywhere. LSTM still runs everywhere.
And so this architecture that is architecturally compatible so that we have a large install base programmable for the future is really important in the way that we help to advance. And as a result, all of this drives the cost down.
You need hardware that can run any algorithm — because the winning algorithm keeps changing.
That’s not a bad point, though it is mitigated by the fact that for the successful ASICs (and there won’t be that many, most new projects are likely to fail) there’s a lot of vertical integration, so the silicon design can be informed by what is on the roadmap. 🗺️
In other words, Google’s TPUs are made with what DeepMind is working on in mind, and Amazon’s Trainiums are now getting input from Anthropic.
📲 Apple’s Siri Will Use Google’s Gemini Under the Hood 🍎
It’s happening:
Apple and Google have entered into a multi-year collaboration under which the next generation of Apple Foundation Models will be based on Google’s Gemini models and cloud technology. These models will help power future Apple Intelligence features, including a more personalized Siri coming this year.
After careful evaluation, Apple determined that Google’s Al technology provides the most capable foundation for Apple Foundation Models and is excited about the innovative new experiences it will unlock for Apple users. Apple Intelligence will continue to run on Apple devices and Private Cloud Compute, while maintaining Apple’s industry-leading privacy standards.
The ideal scenario for Apple is probably to use Gemini 3 Flash, which is both very fast and smart, to power Siri. But tailor the user experience via the product interface, maybe some RL and fine-tuning of the model itself, etc, such that it all feels very Apple and different from using the Gemini App.
It’s reported that:
To maintain Apple’s privacy pledge, the Gemini-based AI will run directly on Apple devices or its private cloud system, which is powered by Apple’s own server chips, rather than running on Google’s servers. [...]
Apple can ask Google to tweak aspects of how the Gemini model works, but otherwise Apple can finetune Gemini on its own so that it responds to queries the way Apple prefers, the person involved in the project said.
From Google’s point of view, this is a great defensive move and could become lucrative over time.
If reports that they’re providing Gemini to Apple for $1bn/year are true, they’re not making money on this yet, but they are preventing other labs from getting more scale through Apple’s distribution. And who knows, maybe they can structure things so that the $1bn grows into something material over time, such as by taking a cut of commercial transactions done via Siri?
Or just by renegotiating, once Apple is very dependent on Gemini… Apple will try to avoid this by keeping the system fairly agnostic about which model is used, but will they succeed? 🤔
🖇️🦾📁 Claude Cowork Preview (for Max Subscribers)
I’m sure you’ve heard about Claude Code non-stop recently. It’s really having a moment, and people are doing pretty incredible things with it.
But it’s still pretty nerdy. In the same way that DOS was too much for most people back in the day, the command line terminal is going to be too much to handle for the vast majority of users.
Enter Claude Cowork, the more user-friendly app-based version of Claude Code:
How is using Cowork different from a regular conversation? In Cowork, you give Claude access to a folder of your choosing on your computer. Claude can then read, edit, or create files in that folder.
Cowork is designed to make using Claude for new work as simple as possible. You don’t need to keep manually providing context or converting Claude’s outputs into the right format. Nor do you have to wait for Claude to finish before offering further ideas or feedback: you can queue up tasks and let Claude work through them in parallel. It feels much less like a back-and-forth and much more like leaving messages for a coworker.
Most impressively, Claude Code’s creator has recently said that he has stopped writing code himself. When asked how much of Cowork was written by Claude Code, he replied:

To be clear, he added the precision that humans were very much in the loop: “We had to plan, design, and go back and forth with Claude” but “Claude wrote all the code.”
So far, this preview is only available on the MacOS app for Anthropic subs on the Max Plan ($100-200/month). Hopefully it comes soon for users on lesser plans!
But considering how fast Anthropic built this tool, how long until Google and OpenAI release their own version of this agent-centric product? 🤔
📚 Jimmy Soni & Jim O’Shaughnessy on Reinventing Publishing 📚
I’m so totally super biased here because these are two of my favorite people, but I thought this was a great conversation about what we’re doing at OSV when it comes to book publishing via Infinite Books.
🧪🔬 Liberty Labs 🧬 🔭
🏥🧑⚕️🤖 Anthropic Announces Claude for Healthcare
In the same way that OpenAI has been focused on the consumer and Anthropic on the enterprise, their health product — right on the heels of ChatGPT Health, which I wrote about last week — is also more targeted at organizations than individuals:
we’re introducing Claude for Healthcare, a complementary set of tools and resources that allow healthcare providers, payers, and consumers to use Claude for medical purposes through HIPAA-ready products.
Claude can now connect to:
The Centers for Medicare & Medicaid Services (CMS) Coverage Database, including both Local and National Coverage Determinations. This enables Claude to verify locally-accurate coverage requirements, support prior authorization checks, and help build stronger claims appeals. This connector is designed to help revenue cycle, compliance, and patient-facing teams work more efficiently with Medicare policy.
The International Classification of Diseases, 10th Revision (ICD-10). Claude can look up both diagnosis and procedure codes to support medical coding, billing accuracy, and claims management. This data is provided by the CMS and the Centers for Disease Control and Prevention (CDC).
The National Provider Identifier Registry, which allows Claude to help with provider verification, credentialing, networking directory management, and claims validation.
🧮 GPT-5.2 Pro Cracked Three Previously Unsolved Erdős Problems 😮
The talking point about how ‘AIs are really smart but they aren’t creating novel knowledge’ is getting more tenuous by the day.
GPT-5.2 Pro, combined with Harmonic's Aristotle proof verification system, has produced solutions to three decades-old Erdős problems: #728, #729, and #397. The proofs have been formalized in Lean, a proof verification language, and Terence Tao has participated in the verification process (though they are not yet published in peer-reviewed journals).
Problem #728 was the first and appears to be the most solidly “autonomous” result. An arXiv write-up confirms this is recognized as the first Erdős problem solved autonomously by AI, with no prior literature found.
Problem #729 is closely related to #728. GPT-5.2 Pro adapted the techniques from #728 to handle a variant about factorial divisibility.
Problem #397 was disproved, showing the conjecture was false through an infinite family of counterexamples, also formalized in Lean.
Terence Tao wrote: "AI tools are now becoming capable enough to pick off the lowest hanging fruit amongst the problems listed as open in the Erdős problem database, where by 'lowest hanging' I mean 'amenable to simple proofs using fairly standard techniques.'"
The problems themselves aren’t providing huge breakthroughs, this wasn’t like solving room-temperature superconductors or anything like that. But it’s a breakthrough in itself to see AI reach this level, and the common refrain applies: “This is the worst that it’ll ever be, it’ll only get better from here.”
🎸🔊 How Guitar Amps are Turned Into Software 🇫🇮
Very interesting visit to Neural DSP’s headquarters in Finland and interview with Doug Castro, the co-founder, about how the company was created and how they do what they do.
That must be such a cool job for someone who likes both engineering and music!
🎨 🎭 Liberty Studio 👩🎨 🎥

👮♂️📺 Back to the 1990s: NYPD Blue & David Milch’s Genius
My wife and I have been making our way through NYPD Blue over the past few months. I decided to check it out after reading David Milch's excellent memoirs.
I became a fan of Milch because Deadwood is my fave show (I recorded a podcast about the show with David Senra 🤠), but all the NYPD Blue anecdotes in the book convinced me I had to check it out.
I had low expectations... some cop show procedural from the 90s?
Turns out, it's way better than I expected.
It takes a few episodes to find its footing in season 1, but it gets good quick, and the last few episodes of season 3 have been all-timers. It’s Milch’s style to make important things happen a few episodes before the end of the season rather than at the end, when you don’t expect it.
Milch's voice has become stronger in the writing over time. As it went on, he took over most of the creative decisions for the show, and it's a good thing.
I love how he took the police procedural and made it something more. It feels organic and messy and nuanced. It’s a prototype of the prestige TV that came later with Oz and The Sopranos.
It's also a great time capsule to see NYC in the 1990s. If you want something old school, I highly recommend it. Give it a few episodes, but then it keeps getting better and better over the next few seasons. S3 is my favorite so far.