

621: Going Deep on Nvidia GTC 2026, Agentic Era, Groq Strategy, OpenClaw Hype, The Android of Self-Driving, 1990 Video Store Simulator, Shingles Vaccine vs Cognitive Decline, and Rick Beato Interview
"Strange to think about the path dependency"

Erudition can produce foliage without bearing fruit.
—Georg Christoph Lichtenberg

💻💾 Ben Thompson (💚 🥃 🎩) said something that struck me on a recent episode of Sharp Tech. I don’t have the transcript, so this is my rough paraphrase rather than his exact wording:
We may be the only generation that had to know computers. Our parents didn’t, and our kids won’t need to.
(for reference on the generation he’s talking about, afaict Ben is in his late 40s. I’m 43)
This made me think about how many other things are like that.
Maybe the equivalent for my dad’s generation was being able to fix cars. Back then, you had to. Stuff broke frequently, carburetors needed adjusting, ignition points wore out, timing drifted, and drum brakes needed manual adjustment.
I know basic maintenance, but for most people my age and younger, cars feel more like appliances. And the reason may be similar to what happened with computers: they got more complex at the same time as they got more reliable, so it became harder to tinker just as you had fewer reasons to.
Growing up, I probably spent a third of my time in front of the computer diagnosing and fixing problems on DOS (tweaking CONFIG.SYS and AUTOEXEC.BAT so King’s Quest would load 😅), then Windows, then Linux systems. Upgrading the hardware was so expensive that whenever I did, I spent months researching components, bought them individually on sale, and DIY assembled everything.
That was so annoying, but I also learned a tremendous amount doing it.
My son’s not going to do that with iPads and MacBooks. 💻
Maybe every important technology has a middle phase where ordinary people have to understand its guts before it becomes an appliance 🤔
What else is like that? What will be the equivalent for my kids’ generation?
🗓️ On March 11, I published a piece about Paul Ehrlich.
He died on March 13.
I swear it’s a coincidence ¯\_(ツ)_/¯
🔎📫💚 🥃 We’re at the point where too few readers of this newsletter are paid supporters, and it’s threatening the existence of the project.
Don’t take it for granted. If you want it to continue, become a paid supporter 👇
🏦 💰 Liberty Capital 💳 💴
🎂 🤖 Going Deep on Jensen’s 2.5-Hour GTC 2026 Keynote 🔥🚒
This was a marathon. After a few years of tighter focus, Nvidia is back to announcing so many things that it’s borderline overwhelming. It’s rare to see a company that has both this level of breadth and depth while executing at a pace that most startups would struggle to match.
Nvidia’s overarching message is: we are now in the agentic era.
We began in the generative era, with ChatGPT kicking down the door to the modern AI revolution. o1 augmented it and brought us into the reasoning era. But now, it’s all about agents. 🤖🤖📋🤖🤖
Here’s a non-exhaustive list of what Nvidia showed us: DLSS 5, seven new chips in production, BlueField-4 STX for storage, Vera CPUs (now standalone!), updates to Omniverse, space computing stuff, NemoClaw, the new version of Nemotron, agentic platform stuff, Hyperion stuff for level 4 self-driving, partnerships for edge compute, Dynamo updates for inference orchestration, lots of robotic stuff, lots of details on every part of the Vera Rubin servers, the new Groq-based inference racks, and some teasing of the next generation (Feynman!).
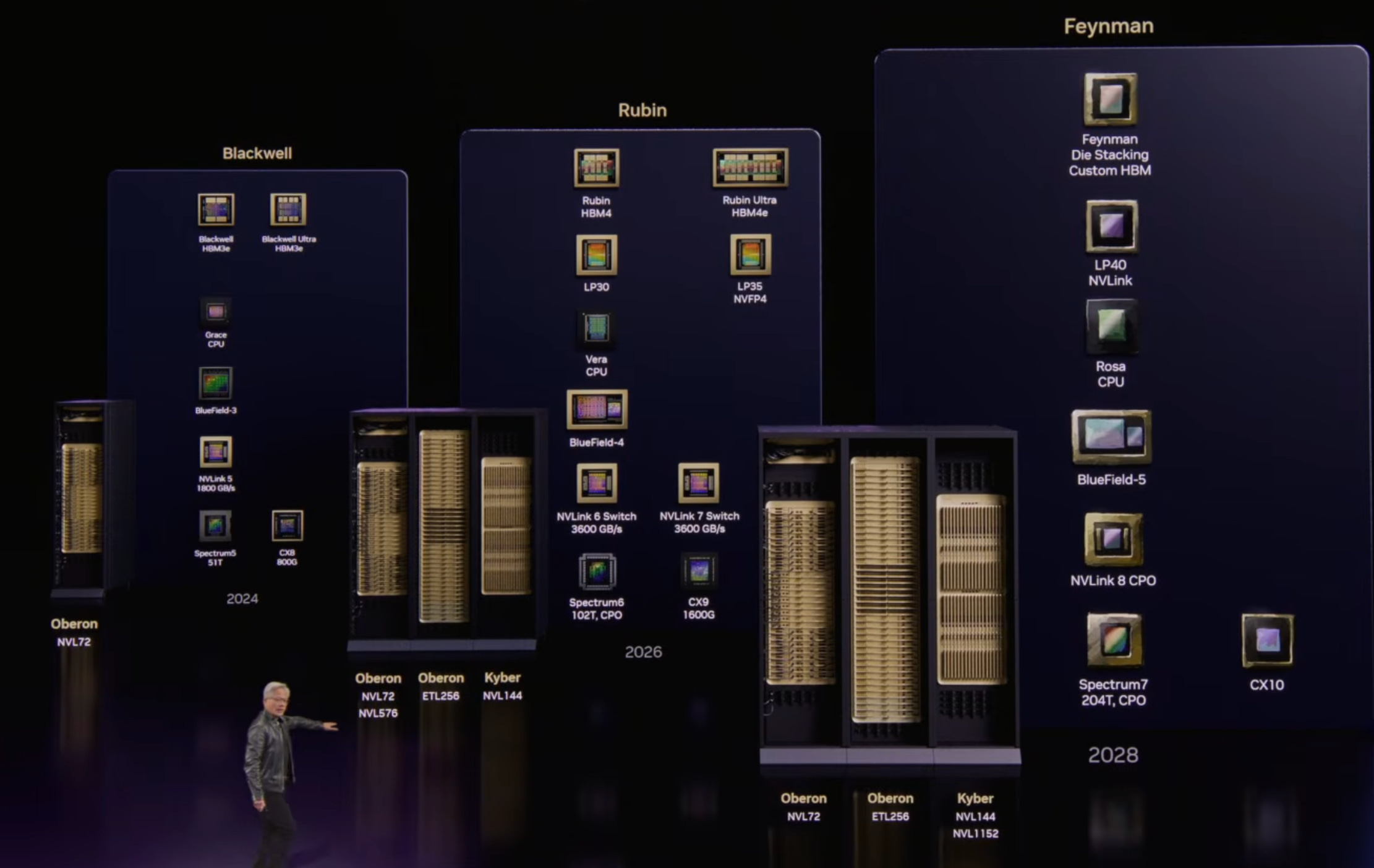
Look at all these chips and their racks. I still think many people underestimate how hard Nvidia is to keep up with. They do so many things at the same time, and all the pieces are interconnected (⚙️⚙️) and need to be delivered on a precise timeframe, or nothing works.
Oh, and Jensen not-so-casually said that he sees “at least 1 trillion dollars” in orders through 2027 and “in fact, we are going to be short, because I am certain computing demand will be much higher than that.” And that’s just with what they have visibility on right now. 💰
Let’s dig deeper into Jensen’s five-layer cake, shall we? 🍰
Here are my highlights:
Tokenomics aka What it Takes to Keep Up 💵📊
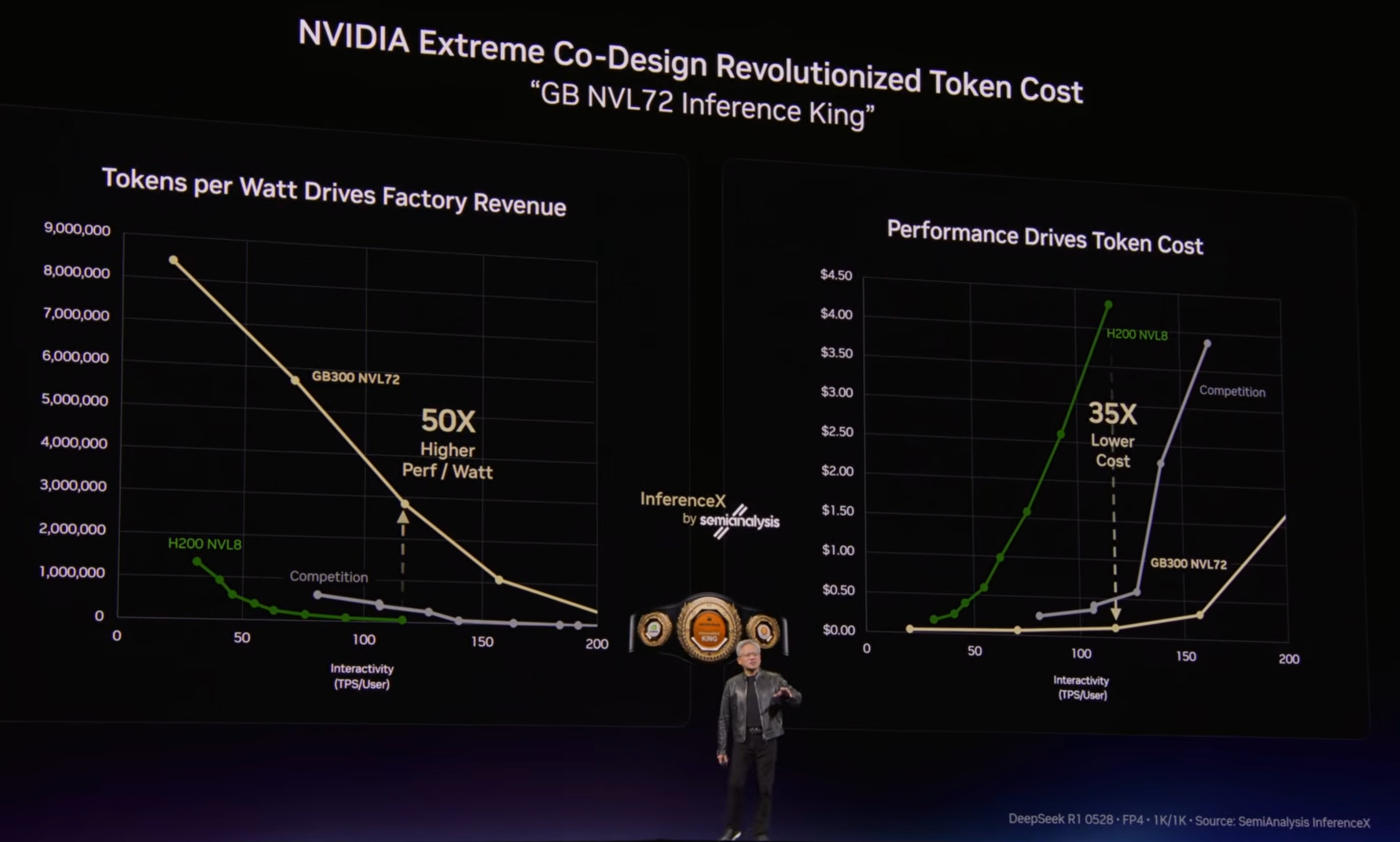
I want to start with the one thing that Jensen hammered home again and again:
More and more of this business reduces to token economics: how many tokens you can produce, how valuable those tokens are, and what your bottlenecks are along the way (power, compute, cooling, permitting, integration, and so on).
And Nvidia has been making HUGE strides from one generation to the next in performance per watt, which either reduces the cost of inference and training, or lets you scale up to generate more valuable tokens through smarter models (larger, more pre and post-training, more reasoning, agentic workflows, etc).
As Jensen points out, if the old Moore’s Law applied, we may have seen a doubling of performance per watt, while from Hopper to Blackwell, the diff is closer to 50x.
He also said a few times, explicitly and implicitly, that once we reach gigawatt-scale ‘AI Factories,’ costs are so high (he cites $40bn/GW), even without taking into account the compute, that going with anything but the most proven platform (*cough* Nvidia *cough*) is a huge risk.
What if you’re having trouble integrating various parts of the stack? What if some vendor has a delay? What if Nvidia keeps updating the performance of its software and other vendors don’t keep up? What if your token cost ends up worse than you thought?
There was a slide that compared what you could do with 1 gigawatt on earlier Hopper-era systems (about 2 million tokens/second) and on Vera Rubin (about 700 million tokens/second). That’s a 350x increase in a few years 🤯
And even then, raw token counts still understate the shift, because not every token is equally valuable.
Back in the Hopper days, these tokens were mostly from GPT-4 and GPT-4o type models, while what will run on Vera Rubin next year should be better than today’s best models (but even if you just assume 700 M tokens of Opus 4.6 and GPT-5.4, that’s still much more valuable than an equivalent number of tokens from GPT-4o).
Token economics are not just a silicon problem. Nvidia’s new Dynamo 1.0 is basically an inference OS for AI factories. The software routes workloads, manages memory, and improves utilization. Optimizing the orchestration of all this brutally expensive hardware to squeeze every drop out of it has a very high ROI, and Nvidia says Dynamo can improve Blackwell inference performance by up to 7x.
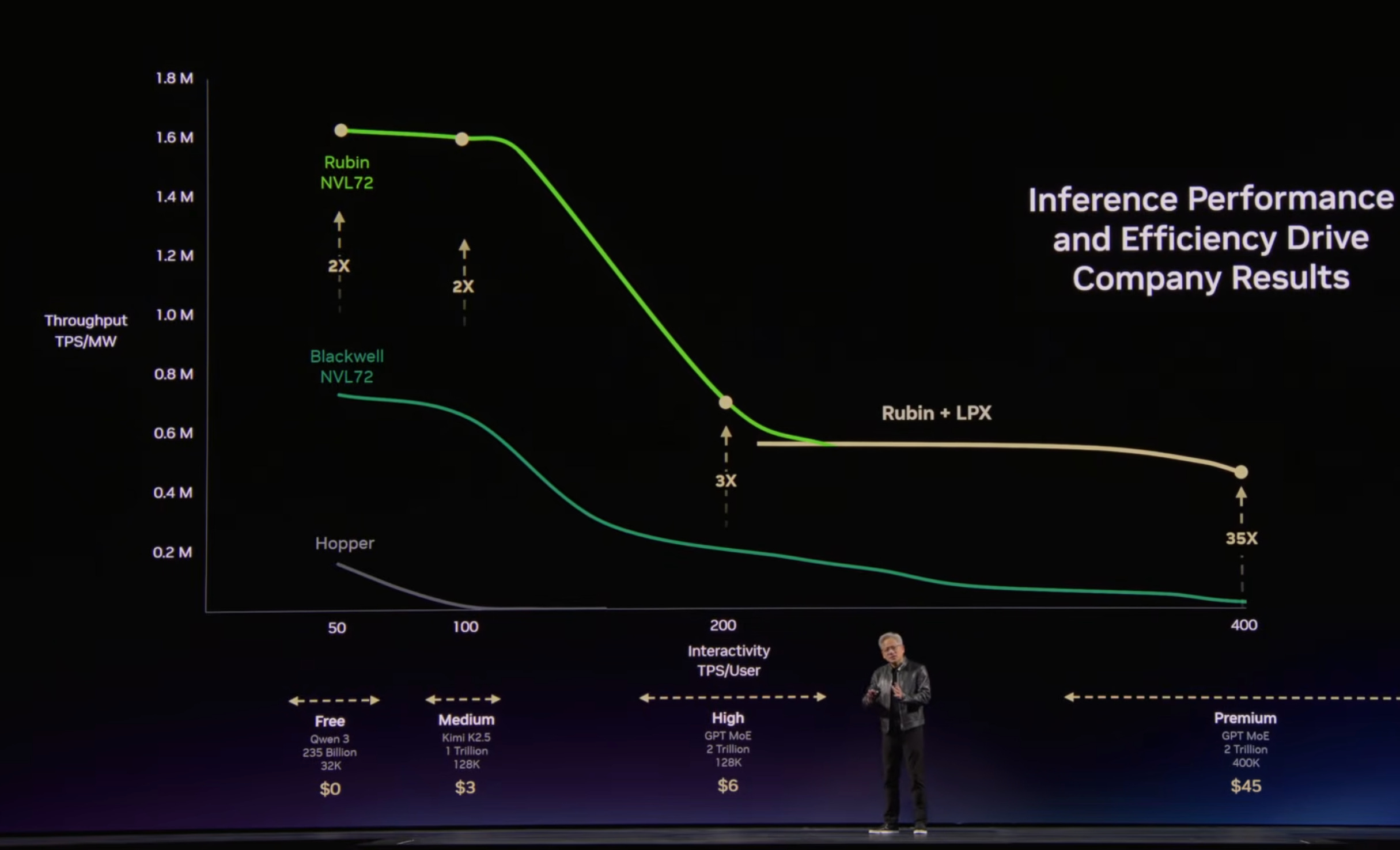
And of course, Rubin plus Groq is on the horizon with another step up over Blackwell:
DLSS 5 and Gaming Updates 🎮
This is a bit bittersweet to think about.
Yes, DLSS 5 looks like it makes games look much better. The realism of human faces, and the way it improves geometry and lighting, is astounding for something rendered in real time.
From the start in 2018, DLSS has been about making games look sharper and run faster by rendering fewer pixels internally and then using AI to intelligently reconstruct a higher-resolution image. At first it was mostly just upscaling, but over time, it has evolved to generate whole extra frames.
The latest version goes far beyond just a boost in performance to do way more complex detail generation:
DLSS 5 takes a game’s color and motion vectors for each frame as input, and uses an AI model to infuse the scene with photoreal lighting and materials that are anchored to source 3D content and consistent from frame to frame. DLSS 5 runs in real time at up to 4K resolution for smooth, interactive gameplay.
The AI model is trained end to end to understand complex scene semantics such as characters, hair, fabric and translucent skin, along with environmental lighting conditions like front-lit, back-lit or overcast — all by analyzing a single frame. DLSS 5 then uses its deep understanding to generate visually precise images that handle complex elements such as subsurface scattering on skin, the delicate sheen of fabric and light-material interactions on hair, all while retaining the structure and semantics of the original scene.
That’s some complex stuff that needs to happen in real-time, on an interactive game where the player can hit a button or joystick at any time, requiring instant drawing of new frames.
But the bittersweet part is how little gaming will matter to Nvidia from a financial perspective going forward. What used to be pretty much 100% of the company’s revenues was $16 billion out of $216 billion in the last fiscal year.
That’s 7.4%, and shrinking fast. And no doubt at lower margins than data-center SKUs.
Can Nvidia justify putting the A-team on gaming stuff? Will it even show up in the company’s top 10 priorities in a few years? Some of the tech developed for AI chips can no doubt be ported to gaming GPUs, but those two species will diverge more and more over time. AI was first created on gaming GPUs, so there’s a common ancestor, but evolutionary pressures are pulling them apart. 🦃↖️↗️🦅
The Vera Rubin Family 👨👩👦👦
Nvidia keeps doing more, faster, to keep the competition at bay.
At this GTC, they highlighted *seven* new chips for five new racks, and they say they are in production:
Vera CPU
Rubin GPU
NVLink 6 Switch
ConnectX-9 SuperNIC
BlueField-4 DPU
Spectrum-6 Ethernet switch
Groq 3 LPU
It’s very cool to see the physical improvements to the racks to reduce the number of cables (or eliminate them!) and simplify installation to save time (and cost).
Nvidia started making ARM CPUs a few years ago.
While AMD and Intel make great CPUs for the needs of hyperscalers who monetize by the core and have usage patterns and bottlenecks that are very different from AI, the Grace CPUs were designed to keep expensive GPU cores fed and happy and to leave as much power as possible for the GPUs.
NVIDIA announced a new Vera CPU rack integrating 256 liquid-cooled Vera CPUs [...]
Vera features 88 custom NVIDIA-designed Olympus cores, delivering high performance for compilers, runtime engines, analytics pipelines, agentic tooling and orchestration services. Each core can run two tasks, using NVIDIA Spatial Multithreading,
256 Veras at 88 cores each is *writes on a napkin* 22,528 cores per rack!
That’s a nice rack 😅
The new Vera CPUs are designed for the agentic AI era, where CPUs are now being hit a lot by automated processes that can run at super-human rates. Demand for CPUs is expected to rise so much that Nvidia has created a rack of just Vera CPUs with tons of LPDDR5X memory, which is not typically used in the data center and uses less power than typical server DDR5.
Groq Integration into Nvidia’s Offering 🏎️
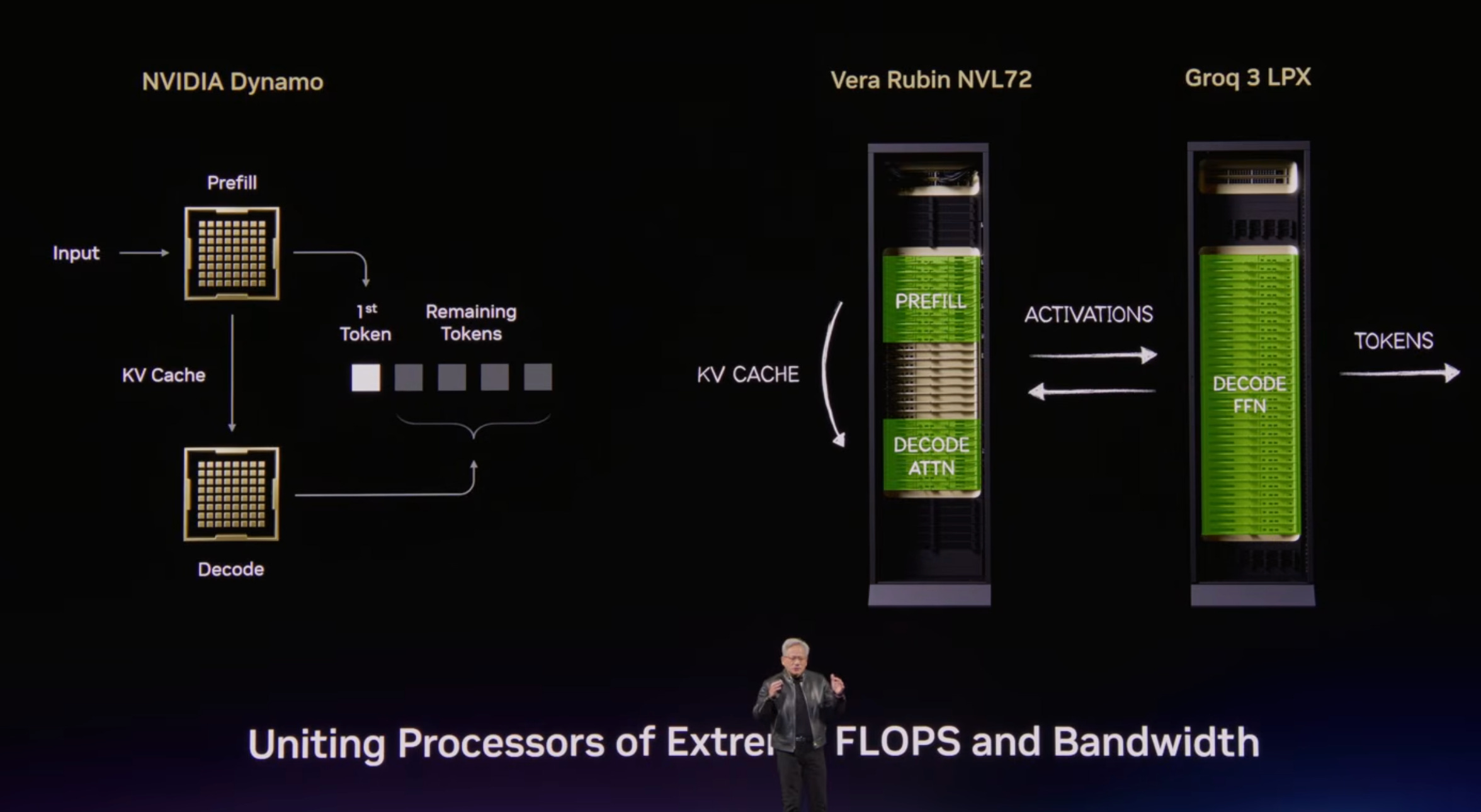
We now know how the $20bn licensing/acquihiring deal with Groq will be used, and I’m kind of surprised at how fast they went from closing, in December 2025, to having new SKUs to sell.
I think their approach is very clever. They are integrating Groq racks into the larger Vera Rubin family, going deeper into heterogeneous computing as a way to better ‘tune’ performance to their customers’ needs, and to get the best of both worlds.
Designed for the low-latency and large-context demands of agentic systems, LPX and Vera Rubin unite the extreme performance of both processors to deliver up to 35x higher inference throughput per megawatt and up to 10x more revenue opportunity for trillion-parameter models.
At scale, a fleet of LPUs function as a giant single processor for fast, deterministic inference acceleration. The LPX rack with 256 LPU processors features 128GB of on-chip SRAM and 640 TB/s of scale-up bandwidth. Deployed with Vera Rubin NVL72, Rubin GPUs and LPUs boost decode by jointly computing every layer of the AI model for every output token.
Optimized for trillion-parameter models and million-token context, the codesigned LPX architecture pairs with Vera Rubin to maximize efficiency across power, memory and compute. The additional throughput per watt and token performance unlocks a new tier of ultra-premium, trillion-parameter, million-context inference, expanding revenue opportunity for all AI providers. Fully liquid cooled and built on MGX infrastructure, LPX integrates seamlessly into next-generation Vera Rubin AI factories to be available in the second half of this year.
As Jensen explained, the software stack will orchestrate the use of both Vera Rubin chips and Groq LPUs so each can do what it does best. The GPUs have a lot more memory, while the Groq chips can have extremely low latency.
Combined, they can accelerate very large models that produce very valuable tokens, especially where speed itself can be sold at a premium. If you need 1,000 tokens per second from a very large model, even the best GPUs won’t be able to help you.
He also said the Groq chips that are now in “volume production” are the 3rd generation of the tech, and are “much better” than the gen 1 demos that have been public so far.
Jensen Hypes OpenClaw, Announces NemoClaw 🦞

A huge segment of the keynote was about OpenClaw (originally Clawdbot). I was surprised by how they framed it as the most important thing since Linux. Jensen even said on CNBC: “This is definitely the next ChatGPT.”
But the OpenClaw community is no doubt great for inference demand, and not all on small models running locally on Mac Minis, so from Nvidia’s point of view, it’s a thing worth encouraging.
What Nvidia is really doing with NemoClaw is trying to wrap OpenClaw in enterprise guardrails. The key piece is OpenShell, a runtime meant to enforce privacy, policy, and security controls around always-on agents. And of course, they make it easy to install their Nemotron models.
I’m a little skeptical of OpenClaw, but having not used it myself, I want to reserve judgment. It feels a bit like a Sora 2 moment, when everybody gets super excited about something, and then it fades…
But the broad ideas behind it are no doubt here to stay. I’m just not sure if this is the implementation that will break through to the masses. It feels a little too much like building your own Linux PC in 1996. It still needs to evolve a fair bit. But hey, I could be totally wrong, and the speed of evolution is certainly faster than anything we’ve seen before.
DRIVE Hyperion Self-Driving 👀🚙🤖
As Tesla is clearly struggling to get its self-driving taxi fleet off the ground seven years after claiming there would be 1 million robotaxis on the road a year later, and then basically re-upping that claim every year since…
(as an aside, I saw some videos of Cybercab demos, and I gotta say, they look like they kind of suck. Those doors are a nightmare, look at how this guy has to move to get in and out, the styling is really polarizing and personally I don’t like it — that Cybercab font is very cringe and in edgelord territory, which makes me think that Musk keeps overruling whatever talented designers Tesla employs — and just won’t fly for a product that is meant to be a mass-market utility that is useful to everyone, and that needs to appeal — or at least not offend — everyone.)
…Nvidia’s strategy seems to be the Android of self-driving by creating a modular horizontal platform for the industry.
They announced deals with Hyundai, Kia, BYD, Geely, Isuzu, Nissan, Bolt, Grab, and Lyft, in addition to existing deals with Uber, Toyota, Mercedes-Benz, Volvo, Jaguar Land Rover, etc. At what point does it become impossible for automakers to compete and develop self-driving tech by themselves?
Waymo, ironically, plays a role closer to Apple, at least so far. They’ve talked about doing some licensing, but their approach is more vertically integrated than Nvidia’s.
Nvidia and Uber are now talking about launching full-stack robotaxi fleets across 28 cities by 2028, starting with Los Angeles and San Francisco in the first half of 2027.
🧪🔬 Liberty Labs 🧬 🔭
💉🧠 Could a Dormant Virus Be Quietly Aging Your Brain? The Shingles Vaccine Might Help
In 2010, a viral immunologist in Colorado started losing his mind. Slowly at first, memory slipping, concentration fading, struggling to finish sentences mid-lecture. Four years of worsening symptoms. He got a brain biopsy, but no answers.
Then he connected it to a shingles episode he’d had just before the decline began.
He took antivirals (💊), and most of the cognitive decline reversed!
That case helped kick off a research thread: A recent study published in the journals of Gerontology looked at data from a Health and Retirement Study (nearly 4,000 adults aged 70 and older, nationally representative) and found that people who’d gotten a shingles vaccine tended to score better on several biological aging measures: lower systemic inflammation, slower epigenetic aging, slower transcriptomic aging, and a better overall composite aging score.
That’s multiple signals pointing in the same direction.
We usually think of vaccines as narrow tools that stop disease X and that’s it, so potential downstream effects on the biology of aging are worth paying attention to.
I wouldn’t oversell it either, though. This is cross-sectional data, so you can’t rule out that the kind of person who gets vaccinated is also wealthier, more plugged into the healthcare system, more prevention-minded, and just biologically better off to begin with.
So: “Plausible and interesting,” not “confirmed.”
There’s a broader mechanistic story here. The virus Varicella-zoster, which most kids know as chickenpox, stays dormant in your peripheral nervous system for decades. It can reactivate as the immune system ages, sometimes silently, sometimes repeatedly.
When it does, research suggests it infiltrates the brain via nerve transport systems, inflames the cerebral arteries, and damages neurons and mitochondria. Studies link shingles to roughly a 60% to 80% higher stroke risk in the first month post-episode. 😬 (to be clear, that means relative to baseline risk, not 60-80% absolute risk… very different!)
A Nature paper earlier this year found that zoster vaccination was associated with about a 20% relative reduction in new dementia diagnoses over seven years in a Welsh natural experiment. Varicella reactivation can also apparently trigger reactivation of HSV-1, another dormant herpes virus most of us carry, potentially compounding the neurological damage.
For me, the math seems pretty asymmetric. Shingles is miserable, Shingrix is highly effective, and the downside is mostly a sore arm and feeling a bit crappy for a day or two.
Even without any potential anti-aging benefits, it would still be worth getting, so this is just a free option on top. And if suppressing a latent virus’s ability to quietly accelerate your brain aging actually turns out to matter, well…
I know I’m making an appointment!
🎮 Run a 1990s Video Store 📼
What used to be a crappy, entry-level job is now primo nostalgia entertainment.
Oh, and it’s currently the #11 best-selling game on Steam!
🎨 🎭 Liberty Studio 👩🎨 🎥
🎼 Interview: Rick Beato on Love of Music, Perfect Pitch, and ‘Beatles vs Amplification’ Path Dependency 🔈
As you know, I’m not the biggest fan of Lex, but in this case, he did a decent job. And it’s fun to hear Rick on the receiving end of an interview rather than asking the questions himself.
If you’re unsure, at least listen until the anecdote about how Rick trained his son to have perfect pitch, starting when he was in the womb and then as an infant. I wish I had known about these simple techniques before my kids were born, I’d probably have tried something like that 😅
I certainly wish I had a better ear 👂
But I’m still glad my kids are exposed to so much music. However their preferences evolve over time, they’ll at least have heard a bit of everything from many genres and eras during their formative years, which is when this stuff seems to matter most for shaping lifelong taste.
I also love Rick’s theory, which he explains about halfway through the pod, that we may owe a lot of the Beatles’ greatest songs to something as mundane as… bad amplification.
PA systems were so bad in the 1960s, and bands didn’t have good monitors like today (and forget about in-ear monitors). Ringo literally had to watch the shoulders of the others bobbing to keep time because he couldn't hear them play. So they decided to become a studio band. And that unlocked a whole new level of creativity and experimentation.
So maybe if the Beatles had better live sound, they would have been completely different creatively. Strange to think about the path dependency, and how the most random things can have the biggest effects. 🔊
Hi Liberty, You should play with openclaw or a similar safer model nanoclaw etc. While sora was just kind of random AI enterainment, even though there are security concerns with OPenClaw it can actually do a huge amount. It is the closest I have seen to a real executive assistant or chief of staff and adds real value. Even if the form changes I think it really signals the value of AI in actually accomplishing things and maintaining context overtime. Newer safer versions will come out but I do think it was a real step change in AI impact.