

631: How Meta Can Win vs ChatGPT, SpaceX IPO, Mythos Cyber & Bio, Ray Tracing LASIK, Amazon + Globalstar vs Starlink, Slowing Down Light, Claude Cowork, and 10,000 Live Shows
"Zero meters per second."

Progress is impossible without change; and those who cannot change their minds cannot change anything.
—George Bernard Shaw

🛀💭 🔦💡 I’m sure you’ve heard that light travels at about 300,000 km/s in a vacuum (186,000 miles/second).
You’ve probably also heard that light slows down when it passes through stuff. Water, glass, diamond, fiber optics. Whatever.
Okay, so light can be slowed down... what’s the slowest it can go?
Like, is there a floor? 🤔
This is the kind of stuff I randomly think about. ¯\_(ツ)_/¯
So I looked it up.
Turns out, in 1999, a Danish physicist named Lene Hau at Harvard fired a laser through a cloud of sodium atoms that had been supercooled to within billionths of a degree of absolute zero (a Bose-Einstein Condensate, to be nerdy).
The light came out the other side at 17 meters per second. 🐌
That’s about 38 mph. Roughly, um, moped speed.
Light. The fastest thing in the universe, at moped speed. 🛵
Then, in 2001, researchers went further. They didn’t just slow light down. They stopped it*. Zero meters per second. They trapped the light pulse inside the atomic cloud, held it there, and then released it again. The light continued on its way like nothing happened.
Science is cool.
* When physicists say they ‘stopped light,’ what actually happened is that the light pulse was converted into a kind of quantum excitation stored in the atoms, a spin wave. The photons didn’t just park themselves mid-air. The information of the light was preserved in the medium, but the light itself stopped propagating as an electromagnetic wave. When the researchers turned a coupling laser back on, the atoms re-emitted the stored pattern as photons, and the light resumed.
🔎📫💚 🥃 As I explained in Edition #628, prices are going up for the first time on May 1st to catch up to six years of inflation. You can lock in the old 2020-era pricing for a year by becoming a supporter now.
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Business & Investing 💳 💴

🏁 Meta’s Bar (and I don’t mean to drink 🍺🍸)
The dynamic in consumer AI is fascinating and so different from what it was a year or two ago (which, in AI time, is basically a decade anyway).
As things stand, Anthropic has been crushing it by being more narrowly focused on coding, enterprise, and agentic use cases. OpenAI, which used to be very much the consumer gorilla 🦍 has been doing a fast pivot to get some of the juicy enterprise bucks and compete more directly with Anthropic.
So, where does that leave the AI consumer market?
xAI is irrelevant, so that leaves Google and… the prodigal son, Meta.
Thanks to Muse Spark, Meta is back in the race, and they might just get a juicy prize because they don’t have to beat Mythos and Spud at the very tip of the frontier, or even match the full Opus experience, they just have to beat the *free version* of ChatGPT.
It’s a very different bar. 🤏
And if OpenAI can’t figure out how to monetize free users better and scale up an advertising platform, the players that already have this infra + scaled consumer distribution are in a very good position to run away with that prize.
To be fair, it's questionable how big that prize is. But previous fears that AI would cannibalize Google and Meta's core businesses — Search, Instagram, etc. — haven't materialized. So as long as that holds, it's worth pursuing defensively AND offensively.
I’ve been testing Muse Spark for a few days.
There are many papercuts and strange omissions (why is the voice dictation so much worse than ChatGPT’s? And why is it only able to understand English? Meta’s probably the most multilingual company around… why does it give errors if you paste a longer chunk of text in the query?), but I like that they didn’t try to reinvent the wheel. They mostly copied ChatGPT’s UX, and the model appears to be generally pretty good (especially in Thinking mode).
But most importantly, it can probably clear the bar of ChatGPT’s free version (if they fix voice dictation and a few bugs).
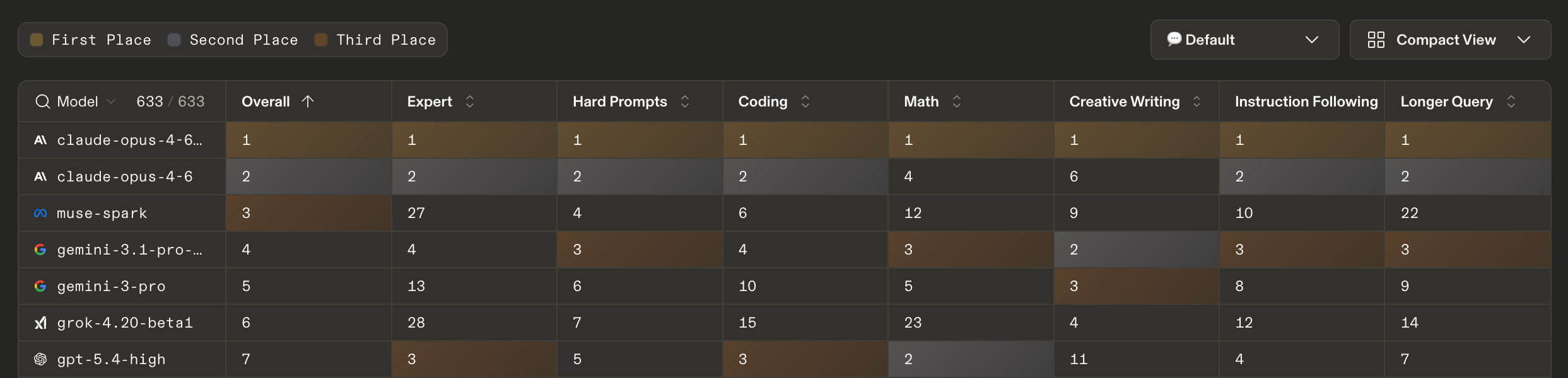
If you look at benchmarks and LLM Arena’s Leaderboard, you can really see the tuning of the model and how it’s less well-rounded than the frontier leaders.
Muse Spark ranks #3 in general text, right behind two versions of Opus 4.6, #2 in vision, but #27 in “expert” tasks (“math, coding, creative writing, and other open-ended domains”) and #12 in Math. But as I said in Edition #629, this is still very impressive for what is claimed to be a smaller model (we don’t know the exact size, but I would guess about Sonnet size).
On one hand, that’s exactly what matters most to likely users of Meta AI. On the other, there’s always some skills transfer and some emergent capabilities, so I wonder if the lack of focus on coding/math/expert-level tasks/etc will hold back the more general abilities of the model over time 🤔
Even just for internal use — it has been reported that Meta is one of the biggest users of Anthropic tokens — I’m sure that if they could make their own frontier model that was good at coding, they would prefer to use it over paying a lot of money to Anthropic AND sending over a lot of their proprietary code and secrets (even if, in theory, data security promises were made.. You never know, they’re a big target and could get hacked and data could be exfiltrated). 🏴☠️
Anyway, I’m sure Meta is aware of this and will aim for the Pareto frontier when balancing their pre- and post-training recipe so that they can satisfy both the users of their platforms and their internal needs (engineering, content moderation, ads, etc) 👨🍳
🛰️🛒 Amazon Acquires Globalstar for $11.57 billion (and Apple Probably Wanted It That Way) 📱
Amazon is buying Globalstar for $90/share or 0.3210 shares of Amazon. It’s interesting not just because space is cool (though it is). It gives them more spectrum and satellite infrastructure to accelerate Leo, their satellite constellation and Starlink competitor, though only a little (this isn’t game-changing or anything).
In addition, Amazon and Apple announced an agreement for Amazon Leo to power satellite services for iPhone and Apple Watch, including Emergency SOS via satellite.
This appears to be mostly just an extension of the existing deal between Apple and Globalstar. It may also signal the beginning of a larger relationship between Amazon Leo and Apple as their constellation gets deployed.
In fact, as Ben Thompson argues, it’s plausible that this deal was driven by Apple, as a way to give them an alternative to Starlink.
Globalstar currently partners with Apple to power satellite service on iPhone 14 or later, as well as Apple Watch Ultra 3, allowing users to text emergency services, message friends and family, request roadside assistance, and share their location.
This follows a recent announcement that Delta Airlines will also use Amazon Leo on 500 planes starting in 2028. ✈️🛰️ (JetBlue also announced a deal last year)
That’s kind of late compared to Starlink, which is already deployed by United and a bunch of other airlines. But apparently, Delta liked Leo’s tech better (they already run much of their operation on AWS, the theoretical uplink and downlink are faster than Starlink, and Amazon’s phased array antenna design seems pretty cool) OR Amazon just made them such a great offer to try to gain a foothold that they couldn’t refuse 🤔
🚀 More SpaceX Financials: A Satellite Company That Also Launches Rockets 📊
Speaking of low-Earth Orbit satellite constellations (that’s still a cool phrase, I’ll never get used to the fact that this exists above our heads), more financial numbers have been leaking out ahead of SpaceX’s IPO:
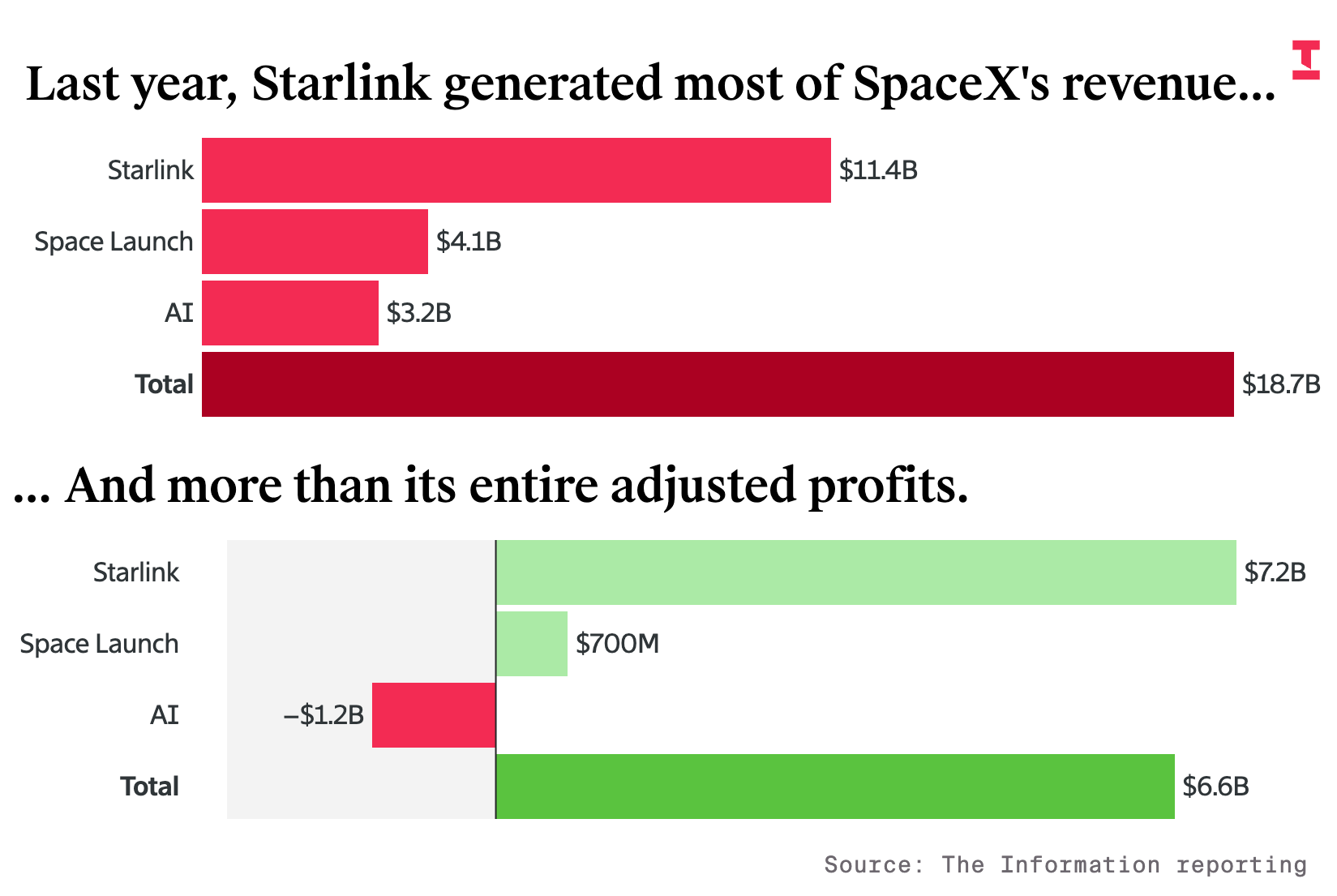
The main business is now Starlink 📡🛰️🛰️🛰️🛰️🛰️
SpaceX’s Starlink internet connectivity business generated $11.4 billion in revenue, growing 50% from the prior year and generating 61% of the company’s overall sales, according to the financial figures. The business line was the only one generating cash, the figures indicate.
Starlink’s earnings before interest, taxes, depreciation and amortization as well as stock-based compensation were $7.2 billion last year, meaning the adjusted Ebitda margin on those sales was 63%, rising from 41% in 2023 and 50% in 2024.
Note that this is also before SBC.
SpaceX’s space and AI businesses have shrinking margins and are burning cash as the company invests in its next rocket and in data centers. [...]
Overall, SpaceX’s cash burn by that measure would be about $14 billion. Last year, SpaceX put out more on capital expenditures—$20.7 billion—than it generated in revenue.
A lot of that is xAI, which burned a lot of cash, and it’s fair to wonder how much of its revenue is from Twitter at inflated transfer rates. 🐦
What about the rockets? Isn’t that the main business? 🚀
Last year, revenue in the rocket launch business only grew 8%, to $4.1 billion. Most of SpaceX’s 160-plus launches sent up its own Starlink satellites. Other customers include government agencies and other companies launching satellites for national security or imagery, but that’s been a limited market
Interesting to think of how much smaller SpaceX would be if it wasn’t its own first-and-best customer, kind of like how Amazon was AWS’s first big customer (except that it didn’t stay that way and the market rapidly expanded).
If SpaceX IPOs at $1.75 trillion (the reported number), it would be valued around 265x adjusted-EBITDA 😬
‘Has the Atomic Bomb of Cybersecurity Just Been Discovered?’ 🔐💣 (and why Bio is next)
I enjoyed this podcast hosted by friend-of-the-show Jordan Schneider, with Ben Buchanan, former senior advisor for AI at the White House now at SAIS, and Michael Sulmeyer, former Assistant Secretary of Defense for Cyber Policy now at Georgetown.
Here are my highlights:
- The most non-Hollywood scenario: quiet shaping, not dramatic blackouts 🕵️♂️🎤
Ben Buchanan: It seems to me that if you had something like Claude Mythos as a state, you would probably want to use it for your intelligence operations or your pre-positioning, because you are almost by definition going to find vulnerabilities no one else knows of with this system. And you don’t want to make a lot of noise about that. You want to go in, set up a persistent, quiet presence. My view for decades has been that the advantage of cyber is not the whiz-bang sky-is-falling blackout — though you can do that sometimes — it is the slow, insidious shaping of the environment and collection of information. A capability to find vulnerabilities and exploit them autonomously would really help on that side of the ledger.
Ben Buchanan: The bottom line for me is this is incredibly important for understanding the landscape of modern cyber operations, but it does not fundamentally change their character, which I think is still one of shaping rather than signaling.
Yes, the cinematic scenarios get more attention, but the quiet stuff is likely to have a bigger impact, at least outside of hot war situations.
- The Patching Nightmare for Critical Infrastructure 💾 🐌
Michael Sulmeyer: The whole process from discovery of the bug to development of the patch to deployment of the patch — that's going to have to go so much faster in a post-Mythos era, because stuff like this will proliferate and folks will be looking for these things and maybe they can reverse-engineer patches. The IT industry and the backbone of critical infrastructure is going to have to level up in speed because of Mythos.
Michael Sulmeyer: Now you also have to factor in the situation where you find a vulnerability in software where all the people who wrote it are gone, and the company said, "We stopped supporting this thing years ago." Just thinking about how you're going to manage the scale of vulnerabilities that's going to come through here in the near term across software — whoa.
Even if Glasswing is successful and lots of vulnerabilities are discovered and patches written, it’s still a HUGE undertaking to get the patches deployed in the real-world. There’s a lot of outdated software running, a lot of abandoned or semi-abandoned projects, a lot of not-so-competent IT organizations… It’s a big, messy world out there!
- Mythos Is a General-Purpose Wake-Up Call — and Bio Is Next 🧬🧫 ☣️
Ben Buchanan: I think we are very fortunate that cyber is coming first. I think we should use cyber as a lesson for what is coming next at the intersection of AI and other fields. Bio will not be far behind. At some point we will have a Mythos moment for bio. I’m not smart enough as a biologist to know what that looks like, but I’m confident that is the direction of travel.
Ben Buchanan: One lesson we should take away from Mythos is not "wow, this means AI is really good at cyber" — it's that AI is really good. This is a general-purpose system that happens to be good at cyber. If you read the Anthropic system card for Mythos, it's also really good at bio. I imagine the next version is going to be even better. […]
I'm biased here, but this feels like a pretty big piece of evidence that should update us towards taking AI risks seriously — in cyber, yes, but also in things like bio, because those are not going to be far behind.
That one is scary, and we should take it very seriously. Keep an eye on the bio-adjacent AI benchmarks.
🧪🔬 Science & Technology 🧬 🔭
👓🚫 Ray Tracing LASIK: Who Wants Near Superhuman Vision? 👀
I had LASIK done about 20 years ago. I had pretty bad myopia (around -5) with astigmatism, and I could barely see the alarm clock by the bed without my glasses. Getting the surgery was scary, but it was over pretty quickly, and when I woke up from my post-operation nap and could already see with 20/20 clarity, it was one of the happiest days of my life.
For years afterwards, I felt a bit like my life had been upgraded from VHS to Blu-ray. 📼 💿 📺
I still think it was one of my best decisions — a one-time cost and a scary moment in exchange for 20 years of benefits.
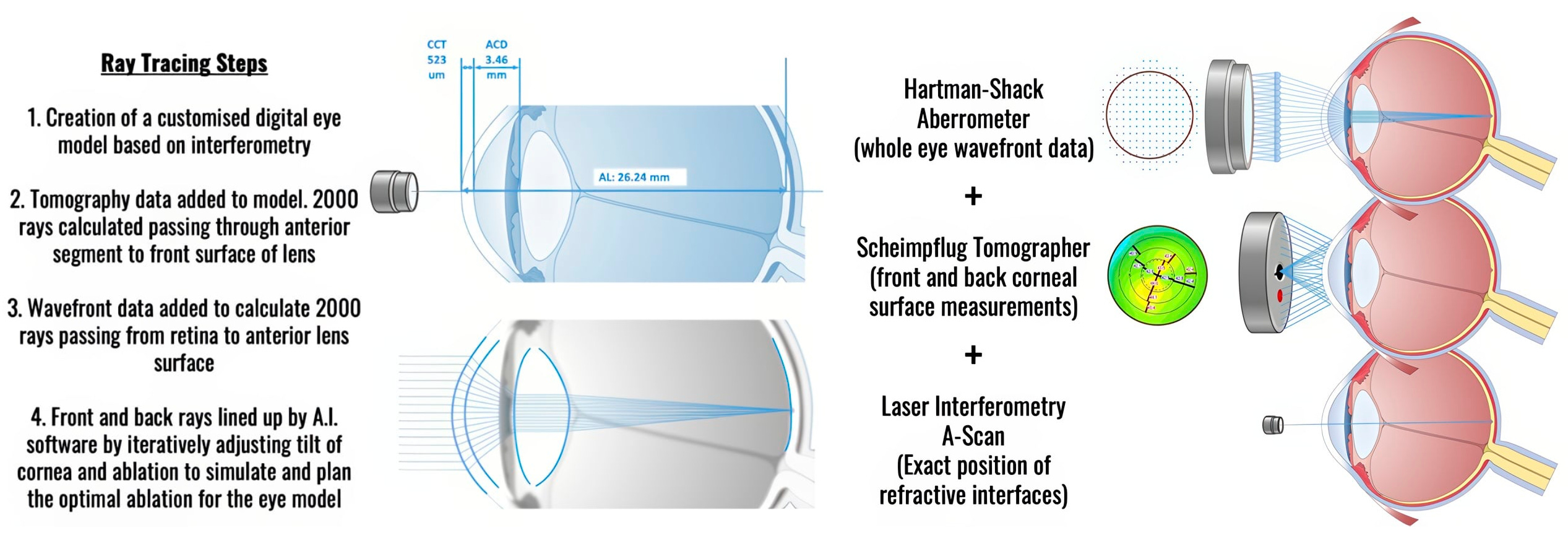
But I recently came across something called ‘Ray Tracing LASIK,’ and it makes so much sense that I’m a little jealous it didn’t exist back in the day.
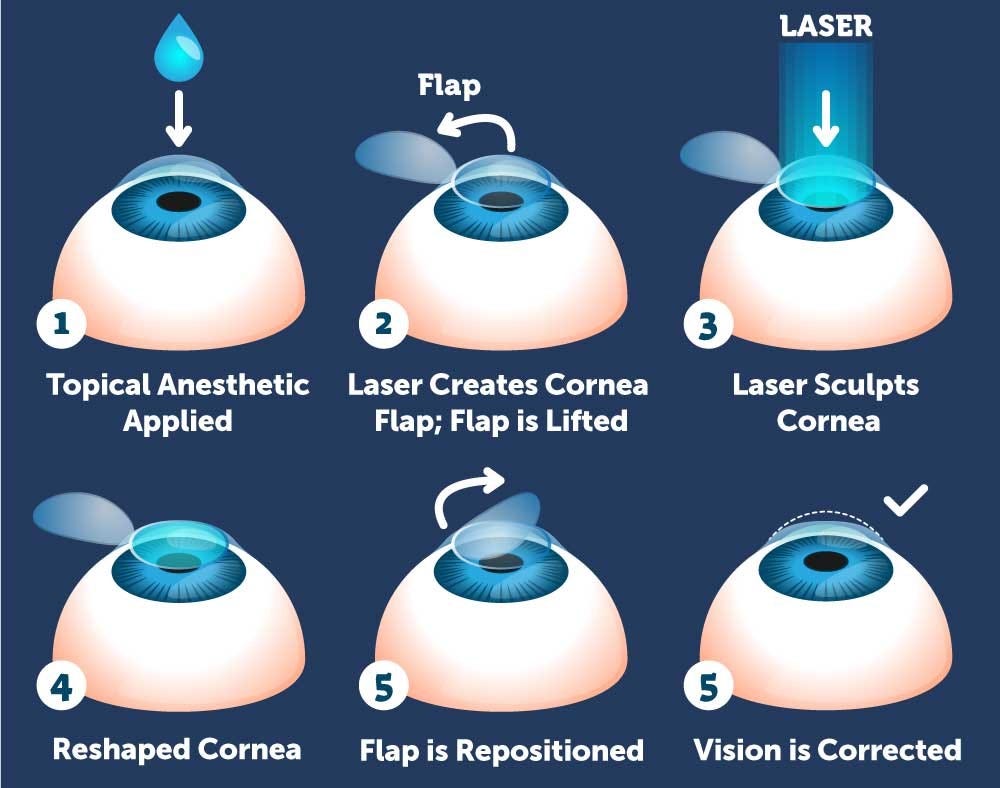
Traditional LASIK treats your eye like a simplified optical system. 👁️
Two people with the same glasses prescription get essentially the same laser treatment, because the planning is based on a generic model of how eyes work.
Ray tracing brings customization to the operation: instead of removing a standard “lens shape” from your cornea, the system builds a full 3D model of your specific eye, using a combination of wavefront imaging, corneal tomography (front and back surfaces), and biometric measurements. It then traces how light rays actually travel through that model and generates a custom ablation profile tailored to your individual optics. The difference is like buying off-the-shelf AirPods that should fit your ears pretty well vs getting a custom-molded in-ear monitor shaped exactly like your ears. 👂
Same name as the 3D rendering technique used in video games or Pixar animated films, same principle: simulate the path of light. Different use case. 🎮
The early clinical data is promising, though you have to read it carefully. The largest published study I found covers 89 eyes with 6 months of follow-up: 100% achieved 20/25 or better, 76-81% hit 20/16, and the procedure avoided introducing new higher-order aberrations (the subtle optical imperfections that cause things like halos and reduced contrast, especially at night).
A separate study of 77 high-myopia eyes found 100% at 20/20 at 3 months, with spherical aberration, the biggest culprit for post-LASIK visual quality issues, essentially unchanged after surgery. That last point matters because LASIK typically increases spherical aberration by 1.2 to 3.9x, especially in high-myopia patients. If ray tracing can actually hold the line on aberrations while still correcting the prescription, that’s a clear win. In a head-to-head conference study (60 patients, one eye per technique), ray tracing outperformed SMILE Pro: 98% of ray-tracing eyes hit 20/12.5 versus 82% for SMILE Pro, and every ray-tracing eye landed within a quarter-diopter of its target.
BUT
These are small studies. 89 eyes, 77 eyes, 60 patients. The PMC study itself notes its sample size as a limitation. The head-to-head data is from a conference presentation by one surgeon, not yet a peer-reviewed multicenter trial. The lead researcher (Kanellopoulos, NYU) explicitly calls for larger multi-center validation. A lot more work remains to be done.
Still, the mechanics just make too much sense. My guess is this becomes the norm within a decade, and we end up with a bunch of people walking around with essentially super-human vision. 🦅
📋 Felix Rieseberg: Cowork's Creator on Why the Product Gap Is Bigger Than the Model Gap 🧰
Good interview with the engineering lead of Claude Cowork at Anthropic. It’s a product I’ve been using a lot, and if you haven’t tried it yet, I recommend it. It brings a lot of the benefits of Claude Code, but in a format that is friendlier for non-coding work.
Here’s a highlight to give you a taste:
- The bottleneck is increasingly product, not model
Felix Rieseberg: We train our models with our products in mind. What the products do informs the research and vice versa. It’s a bit of a dance. However, as models get more powerful, I actually think the “overhang” in the product is bigger than in the model.
The models we have today are already quite capable of running knowledge work over long time horizons and high complexity. We are still figuring out how to package those capabilities for humans. When I visit customers, I rarely leave thinking the model needs to be better at “X.” It’s more common that I’m impressed by how we can organize work to use the model, or I realize the customer’s problem could be solved if I just exposed the right UI or onboarding.
This goes a bit against the main narrative that focuses on how good the next model will be on benchmarks. It reminds me a bit of the megahertz race in the 1990s-early 2000s. People started really focusing on that, so Intel created a chip (Pentium 4) designed to be clocked as high as possible (more Mhz = better, right?), but the winner of that generation was an AMD chip that was designed to get as much work as possible out of each clock cycle (more work per Mhz).
We’re kind of seeing something similar with Anthropic’s success. The models are good, but the tooling around the model (Claude Code, Cowork, various plugins and connectors) is really what is unlocking capabilities. Google has a strong foundation model, but their post-training and harnesses aren’t as good (IMO), and that hobbles their products. 🧰
So Rieseberg is basically saying: a lot of the power is already here, and the real challenge is wrapping it in the right interface, workflow, and onboarding so humans can actually use it.
- “Crawling over glass” is a great product signal
Felix Rieseberg: I gained conviction over the December 2025 holidays. On social media, I saw non-developers picking up Claude Code. People were writing tutorials on how to find the terminal just to use it. Even our developer users were using Claude Code for things that weren’t software at all. If people are “crawling over glass” to use a tool that wasn’t even made for them, that’s a strong predictor of where to invest.
My colleague Boris Cherny, the lead for Claude Code, told me we should ship something by Friday. I negotiated him up to Monday. We “spiked” on how to make Claude Code effective for non-coding use cases.
Cowork is actually rather simple in its ingredients. We took Claude Code and gave it a virtual machine (VM) that Claude can use to run its own code. This VM gives us hard guarantees; the user doesn’t have to supervise it because it’s sandboxed away from your files and network. It also allows Claude to set up its own developer environment without messing with your computer. We then added some elegant UI to simplify the flows for non-developers.
This is what product-market-fit looks like. People will put up with a lot if the core of what you have is good enough, useful enough.
It reminds me of the computers that I grew up with. There were so many annoying aspects, you had to deal with so much BS to do anything… But you put up with it, because it was still amazing once you got there.
- Execution gets cheaper; taste becomes more important
Felix Rieseberg: What’s new is that execution is essentially free. If you have 10 ideas, we can build all 10 prototypes and see which feels better. We have easily 100 different prototypes of applications inside the company right now. In the past, engineering leaders would say, “We can work on that next month.” Now I can say, “Give me 10 minutes, I’ll send you a prototype.” It’s like moving from painting to photography.
Matt Turck: If execution is free, what is the bottleneck?
Felix Rieseberg: Alignment and taste. Competing ideas are hard to reconcile. Human taste is the new fundamental ability. Data helps you see if your taste resonates with people, but you still need that initial vision.
I wonder how far we are from software feeling like the fashion industry. There’s a baseline of quality, but what differentiates a product is the story it tells and how it makes you feel. For Cowork, we want something that generalizes well. No two phones are the same because of the apps installed; similarly, no two Cowork setups will be the same. [...]
I think successful software developers twenty years ago were very good at understanding computers. […] And I think the people who build successful software going forward will increasingly understand humans and users very well.
Software moving in the direction of the fashion industry! I hadn’t heard that one before 👗👠👜
Everyone is focusing on the first-order effect of software becoming easier to make. But the second-order effect is interesting too: once execution gets radically cheaper, taste and product judgment will matter more.
🏋️♀️ The Health Impact of Micro-Exercise Snacks 🚶♂️
A recent RCT out of China looked into a pretty simple idea: what if office workers did 3 minutes of bodyweight exercises every hour during the workday? Basically exercise snacks instead of full meals 🍫
Marching in place, desk push-ups, chair squats, heel raises.
No gym, no equipment, no changing clothes. None of the friction that usually scares people away.
After 12 weeks, the intervention group saw meaningful improvements in fasting blood glucose, postprandial glucose, and insulin resistance, plus about 2 cm off their waist and a ~4 mmHg drop in systolic blood pressure. 📊
The control group was basically flat.
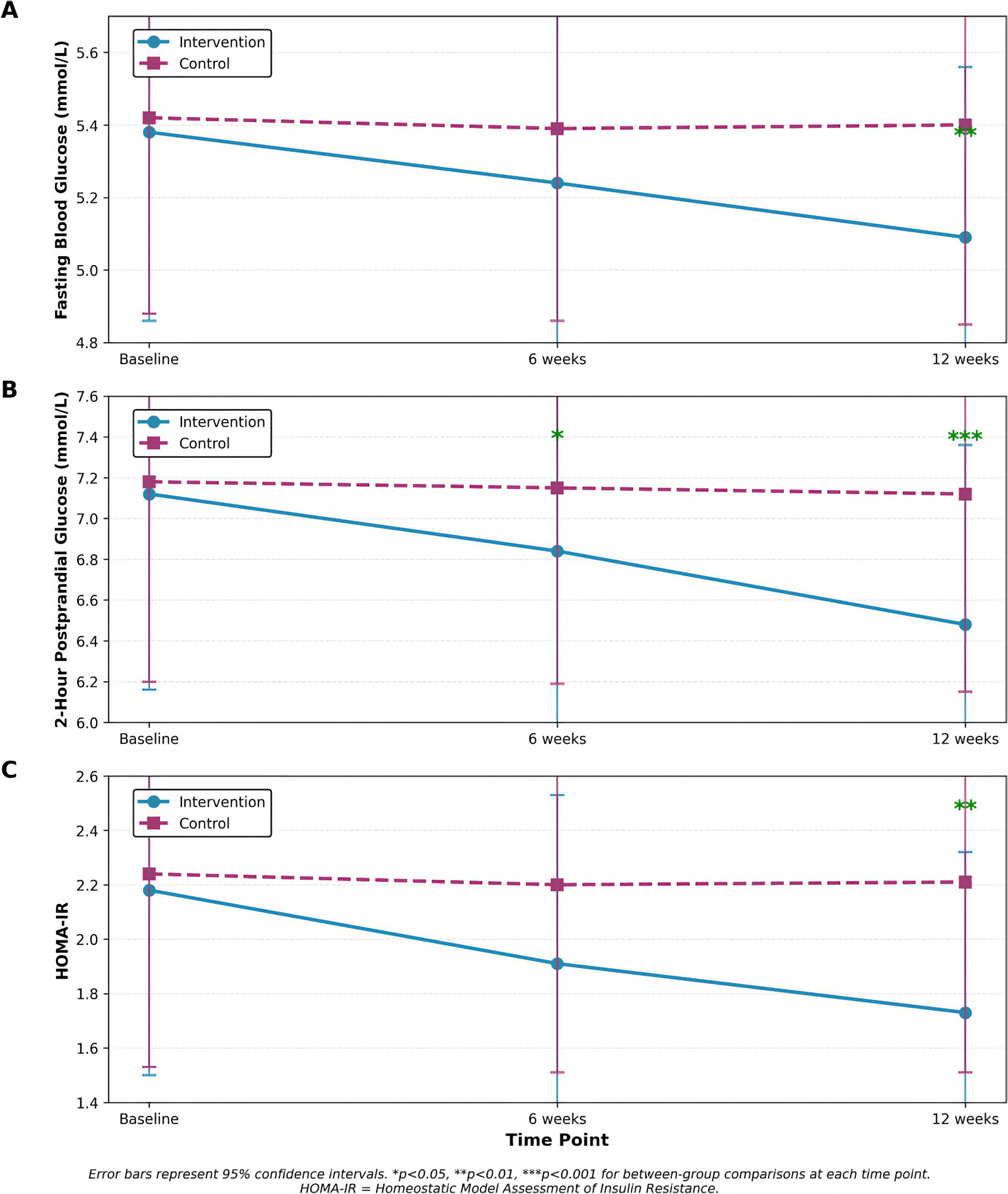
What jumps out (accidental pun) is that just 21 extra minutes of light movement per day, broken into tiny doses, produced metabolic improvements comparable to more intensive structured exercise programs. The implications are that the pattern of how you sit on your butt may matter as much as the total duration.
Some of the usual caveats apply: this is one study with a small sample (86 people), single city, self-reported adherence, no dietary monitoring, and 12 weeks is too short to know if the improvements stick. I’m not saying it’s settled science.
But for those of us who spend most of our day sitting, the asymmetry of the bet is attractive. Whatever the magnitude of the effect, I’m pretty sure it’ll be in the right direction and you’ll feel better than if you just sat there ¯\_(ツ)_/¯
🎨 🎭 The Arts & History 👩🎨 🎥

🎸 Aadam Jacobs Secretly Recorded 10,000 Shows, and Now They’re Online 🎤🎶
This guy is a legend.
From 1984 onward, this Chicago music fan quietly built a time machine for live music.
Wanna hear what Nirvana sounded like in the summer of 1989?

“The collection features early-in-their-career performances from alternative and experimental artists like R.E.M., The Cure, The Pixies, The Replacements, Depeche Mode, Stereolab, Sonic Youth and Björk.” [Really funny to listen to SY on the Daydream Nation tour start Teenage Riot while the drummer’s MIA]
You can search through the collection at the Internet Archive by band name or by year.
Jacobs doesn’t consider himself obsessive or, as many call him, an archivist. He says he’s just a music fan. He figured if he was going to attend a few concerts a week anyway, why not document them? In the early years, he contended with contentious club owners who tried to prevent him from taping. But they eventually relented as he became a fixture in the music scene, and many began letting the “taper guy” in for free. [...]
“Especially after the first couple years, he’s got it so dialed in that some of these recordings, on, like, crappy little cassette tapes from the early 90s, sound incredible.”
First they fight you… then they let you in for free! 😅
The whole collection isn’t online yet, but it’s being digitized box by box:
Once a month, Brian Emerick makes the trip from the Chicago suburbs to Jacobs’ house in the city to pick up 10 or 20 boxes each stuffed with 50 or 100 tapes. Emerick’s job is to transfer — in real time — the analog recordings to digital files that can be sent to other volunteers who mix and master the shows for upload to the archive.
Emerick estimates he’s digitized at least 5,500 tapes since late 2024 and that it will take another few years to complete the project.
It’s one of those cases where obsessive behavior by one person ends up preserving a whole world for everyone else. Source.
Very interesting article. Thanks.
In re LASIK, there are also cool alternatives being tested that avoid removing corneal tissue. Electromechanical reshaping instead electrochemically molds the eye into a better shape. The upshot is vision improvement but without the downsides of LASIK and the (small) risk of complications. https://bli.uci.edu/new-eye-shaping-technique-could-replace-lasik/