

633: AI’s All-You-Can-Eat Era is Ending, Google's Two-Chip TPU Strategy, OpenAI & Microsoft's New Deal, Musk's AI Reboot, SpaceX AI & Cursor, My Thoughts on GPT-5.5, and Pancreatic Cancer Vaccine
"it was very clear who had the leverage"

On the Internet, people on the tails of the bell curve can find one another.
—Virginia Postrel

📷🎨🤖 OpenAI recently released ChatGPT Image 2.0.
One way I’ve been testing it is with old family photos. I asked my mother for old photos of her parents and her childhood, and used the new image model to “remaster” them.
Of course, it’s extrapolating details and colors, and you can never be sure how close the result is to what things actually looked like. But it’s still a very fun exercise, and if you steer the model to retain exact facial features and such, it appears to do a pretty good job.

You can ask it to recreate the photo as if it were shot with a specific camera (I don’t want to pay for a top-of-the-line Nikon or Sony, or a vintage Hasselblad, but I can emulate them!), or on a certain type of film, so I’ve been fiddling with those variables to see what looks best.
But most importantly, my mother seems to really enjoy it. ♥️
⚔️🥚🛡️🏰🐴 In case you missed it, I have a new podcast, and I hope you’ll enjoy it as much as I did recording it:
🔎📫💚 🥃 Last call: As I explained in Edition #628, prices are going up for the first time on May 1st (this Friday!) to catch up to six years of inflation. You can lock in the old 2020-era pricing for a year by becoming a supporter now. ⏳
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Liberty Capital 💳 💴

OpenAI and Microsoft Alter the Deal, Again 🤝
When Microsoft first invested in OpenAI back in July 2019, it was very clear who had the leverage. OpenAI’s tech didn’t do much yet, unless you wanted a really good bot to play Dota 2.
Microsoft had the money, the compute, and the distribution channels. In exchange for their $1bn investment, which was mostly going to be spent on Azure anyway, they got exclusivity, joint development of AI supercomputing infra, rights to commercialize OpenAI’s IP, and economic exposure to the for-profit side of things. The integration went deeper in 2023 with a $10bn follow-on, giving Microsoft 75% of OpenAI’s profits until recouping its investment. These rights eventually converted to a 27% equity stake in 2025.
But over time, as ChatGPT exploded in popularity and pulled OpenAI into hypergrowth, the negotiating equilibrium changed. There was a moment when Microsoft had second thoughts about keeping investment pedal-to-the-floor, which allowed OpenAI to further wriggle out of the exclusivity straitjacket and go fully poly with everyone else.
This apparently reached a new stage:
The companies also scrapped a controversial clause in their deal that would have granted Microsoft a share of OpenAI’s revenue and certain IP rights up until OpenAI achieved “artificial general intelligence,” or AI on par with a human.
Microsoft will now keep getting a share of OpenAI’s revenue until 2030 regardless of whether the startup achieves AGI, the companies said. Microsoft will also retain the rights to use OpenAI’s models and products until 2032, but Microsoft’s rights to the IP will no longer be exclusive.
Microsoft will also stop sharing some of the revenue it makes from selling OpenAI models on Azure. Up until now, Microsoft shared 20% of the revenue from those sales with OpenAI, while OpenAI shared 20% of its total revenue back to Microsoft. OpenAI will keep sharing revenue with Microsoft through 2030, the companies said Monday.
Looks like this was necessary to, among other things, allow OpenAI to sell its APIs on Amazon AWS.
The value of this freedom of motion kept increasing for OpenAI as Anthropic’s explosive revenue growth showed how well coding could be monetized. In return, Microsoft got cleaner economics and protected its downside by removing the AGI escape clause.
Back when OpenAI and Microsoft first made their deal, it was probably expected that the ChatGPT consumer business would be the main engine, but the API and enterprise business turned out to be the real revenue engine (at least for now).
Musk’s AI Reboot: Thoughts on xAI SpaceX AI & Cursor 🤖🚀📡🛰️💾
Speaking of Microsoft, apparently, they looked at buying Cursor but decided not to proceed before this was announced:

This looks like a Hail Mary by the AI laggards to band together and hope that they can make something happen.
Cursor plans to train its latest AI coding model, Composer 2.5, on xAI infrastructure, the people said. Cursor will use tens of thousands of xAI's graphic processing units (GPUs), the chips used to train AI models, they said.
I mean, these GPUs were probably not doing a lot anyway ¯\_(ツ)_/¯
In a memo to staff last week, Nicolls, xAI's president, said the company's model FLOPs Utilization (MFUs), a measure of how efficiently a GPU is used during AI training, was "embarrassingly low" at about 11%. Nicolls said he aims for the team to reach 50% in the next few months.
xAI did incredible things, building a huge GPU data-center in record time by MacGyvering an old appliance factory with gas turbines on trailers tapped into a nearby pipeline. Very impressive, and thanks to all this compute, for a brief moment, they had a very competitive model (around Grok 4).
But users never materialized. They couldn’t keep up when coding and agentic stuff became the new hotness, and pretty rapidly, *all* of xAI’s co-founders not named Elon jumped ship.
Musk then vowed to rebuild xAI and do it right this time (😅), but it’s unclear what the path from here to there is.
Even with Cursor, it’ll be hard to compete on the coding/agentic front with Anthropic and OpenAI. Cursor may have some nice data assets, but they’re still heavily dependent on third-party models, which the labs get earlier and cheaper, and subsidize on the flat-rate plans vs the API, making it hard to compete.
In other words, Anthropic researchers are building the next model using the unreleased Mythos, burning way more tokens than they could afford if they were paying the API prices (because they don’t pay themselves a gross margin). Neither Cursor nor xAI has that advantage — they’re trying to build something either using their own inferior in-house models, or using Anthropic and OpenAI’s public models, paying their competitors a margin and helping them grow.
[Cursor]’s revenue hit $2.7 billion in annualized sales last month, said one of the people, up about 14 times from a year ago. Some investors expected annualized revenue to hit more than $7 billion by year’s end, said two of the people.
Ok, so they’re still growing fast, BUT:
Cursor’s gross margin was negative 23% as of the quarter ended in January, according to two people with direct knowledge of its financials. [...]
Cursor’s gross margin could look even worse than it does. The company classifies the cost of running servers for non-paying users as a sales and marketing expenses rather than costs of goods sold, according to financial documents The Information viewed. [...]
If the cost of inference compute for free users was included in COGS, it would have decreased Cursor’s gross margins for the quarter ending in January from negative 23% to about negative 31%
Yes, it’s a lot easier to grow fast when you’re selling dollars for 70 cents.
And they don’t have the frontier labs’ excuse that training is super expensive, since their own models are not nearly as expensive to train (they take Moonshot’s Kimi K2.5 and then add some of their own frosting to it).
It’s also doubtful that the best AI engineers and researchers in the world will want to go work at xAI, especially after what they saw happen to all of the technical co-founders.
Musk’s primary advantages seem to be:
Raising money and leveraging his other companies
Speed of execution, especially for physical infrastructure
Overpaying for Cursor and using cheap SpaceX equity to do so seems to fit #1. A kind of big acqui-hire and buying a user base in coding. But Cursor isn’t the shiny leader it was not so long ago: Its star has been falling against Codex and Claude Code.
Is Musk going to top-tick a structurally disadvantaged asset that won’t be enough to move the needle? Maybe it’s the least bad option if xAI’s compute is under-utilized and almost un-monetized right now, and Musk doesn’t want to throw the towel and just rent compute to Anthropic and OpenAI. He’s looking for first-party workloads AND for something to reboot his team. Cursor has some experience training models based on Open Source models, but I don’t think they are quite at the level of the big labs.
So, where will Musk find a core frontier team? Is he just going to use lots of SpaceX equity/IPO funds to massively overpay for researchers and do what Zuckerberg did?
Maybe that’ll work, but that probably has a clock on it. I suspect that as soon as Cursor’s top engineers and whatever top AI researchers he recruits with promises of a billion dollars and great soup have earned out, they’ll take the money and run. 🍜💰
⚓🍤 AI’s All-You-Can-Eat Buffet Era is Slowly Ending 🐟

GitHub just announced:
TL;DR: Today, we are announcing that all GitHub Copilot plans will transition to usage-based billing on June 1, 2026.
Why?
Why we’re making this change
Copilot is not the same product it was a year ago.
It has evolved from an in-editor assistant into an agentic platform capable of running long, multi-step coding sessions, using the latest models, and iterating across entire repositories. Agentic usage is becoming the default, and it brings significantly higher compute and inference demands.
Today, a quick chat question and a multi-hour autonomous coding session can cost the user the same amount. GitHub has absorbed much of the escalating inference cost behind that usage, but the current premium request model is no longer sustainable.
Usage-based billing fixes that. It better aligns pricing with actual usage, helps us maintain long-term service reliability, and reduces the need to gate heavy users.
Anthropic has also been making moves in that direction. It’s a bit confusing to try to untangle it, but as far as I can tell, Enterprise plans with 150+ users are moving from flat per-seat rates (up to $200/user/month) to a $20/seat base fee plus usage-based billing on top.
Will what started with larger enterprise plans eventually migrate to individual plans? That seems very likely.
OpenAI still seems to have enough compute to use it as a weapon. Codex has MUCH higher limits than Claude Code on a similarly-priced plan, it’s ridiculous. I can do tons of things in Codex and never run out, while I often go into extra pay-as-you-go usage with Claude.
But I suspect that, if things go well for them, even OpenAI will eventually have to become less generous and make sure that the whales aren’t eating so much that they generate deeply negative margins.
OpenAI’s Nick Turley, head of ChatGPT, said:
“it’s possible that in the current era, having an unlimited plan is like having an unlimited electricity plan. It just doesn’t make sense.”
The writing is on the wall. It’s not company-specific, it’s structural.
🧪🔬 Liberty Labs 🧬 🔭

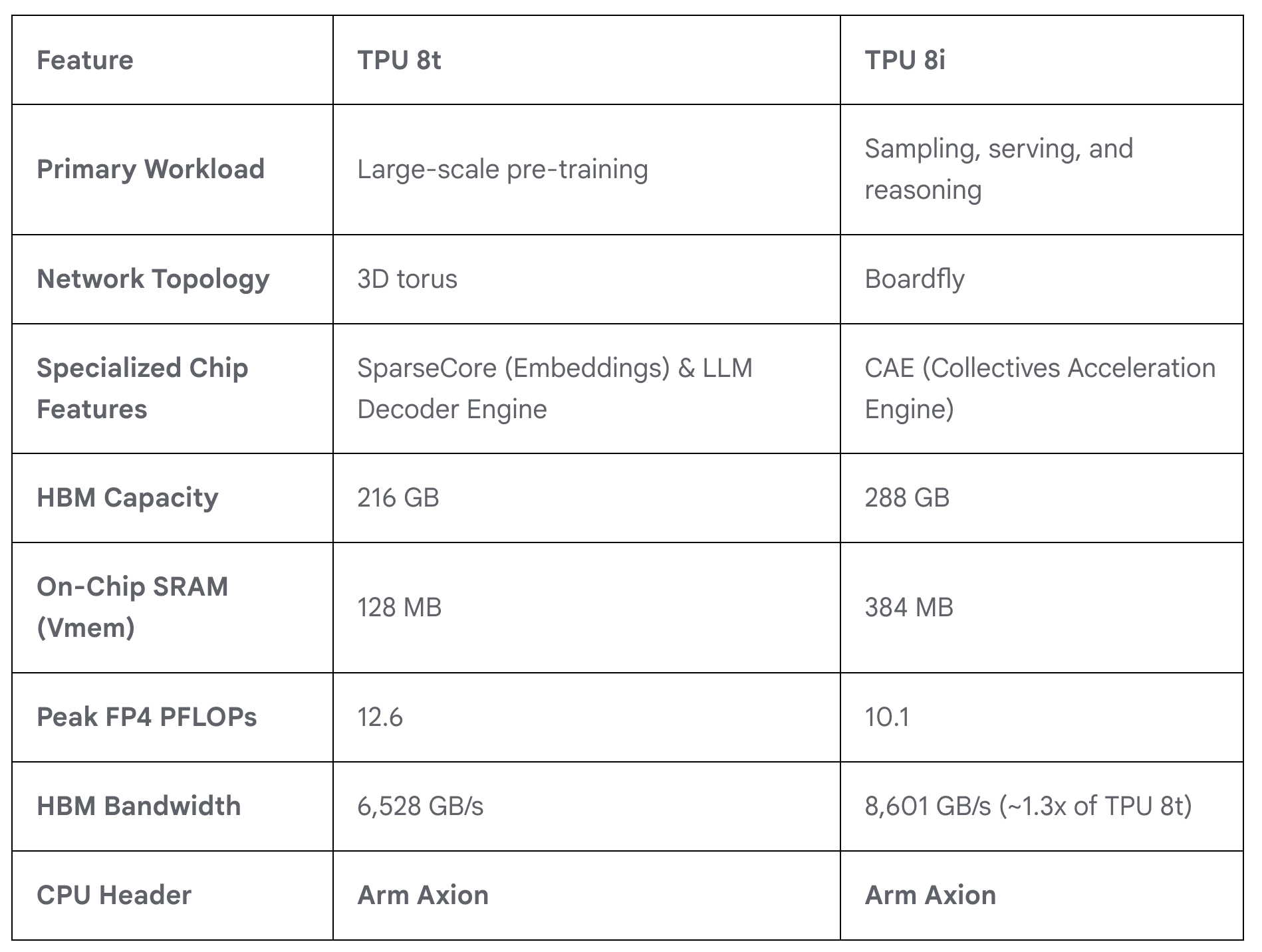
🐜🐜🔍 Google's Two-Chip TPU Strategy: One Chip to Train, Another to Serve
As Nvidia is starting to add more SKUs and split its product lineup a bit more, Google is doing the same with its new TPU, with the TPU 8t for training and TPU 8i for inference:
Training: TPU 8t utilizes our proven 3D torus network topology at an even larger scale of 9,600 chips in a single superpod. TPU 8t is designed for maximum throughput across hundreds of superpods [...]
TPU 8t introduces native 4-bit floating point (FP4) to overcome memory bandwidth bottlenecks, doubling MXU throughput while maintaining accuracy for large models even at lower-precision quantization [...]
With JAX and Pathways, we can now scale to more than 1 million TPU chips in a single training cluster.
Training price-performance: Google claims that TPU 8t delivers up to 2.7x performance-per-dollar improvement over Ironwood TPU for large-scale training.
That’s a lot, though it’ll be interesting to see how that compares to Blackwell and Rubin on the Nvidia side (Blackwell was a really big jump over Hopper).
Inference: With 3x more on-chip SRAM over the previous generation, TPU 8i can host a larger KV Cache entirely on silicon, significantly reducing the idle time of the cores during long-context decoding. [...]
By integrating a specialized CAE, TPU 8i further reduces the on-chip latency of collectives by 5x. Lower latency per collective operation means less time spent waiting, directly contributing to higher throughput required to run millions of agents concurrently. [...]
This is what that crazy spiderweb of ASICs looks like: 🕸️
Utilizing a high-radix design, we connect up-to 1,152 of these chips together, reducing the network diameter and the number of hops a data packet must take to cross the system. By slashing the hops required for all-to-all communication (the heart of MoE and reasoning models), Boardfly achieves up to a 50% improvement in latency for communication-intensive workloads.
Inference price-performance: Google claims that TPU 8i delivers up to 80% performance-per-dollar improvement over Ironwood TPU, particularly at low-latency targets for large MoE models.
Broadcom designed the TPU 8t, and MediaTek designed the TPU 8i. Google is diversifying its silicon supply chain.
They’re pairing those TPUs with their own Axion Arm-based CPUs, which are based on the Neoverse V2 design, replacing the x86 CPUs used in previous generations.
Specs look like this:
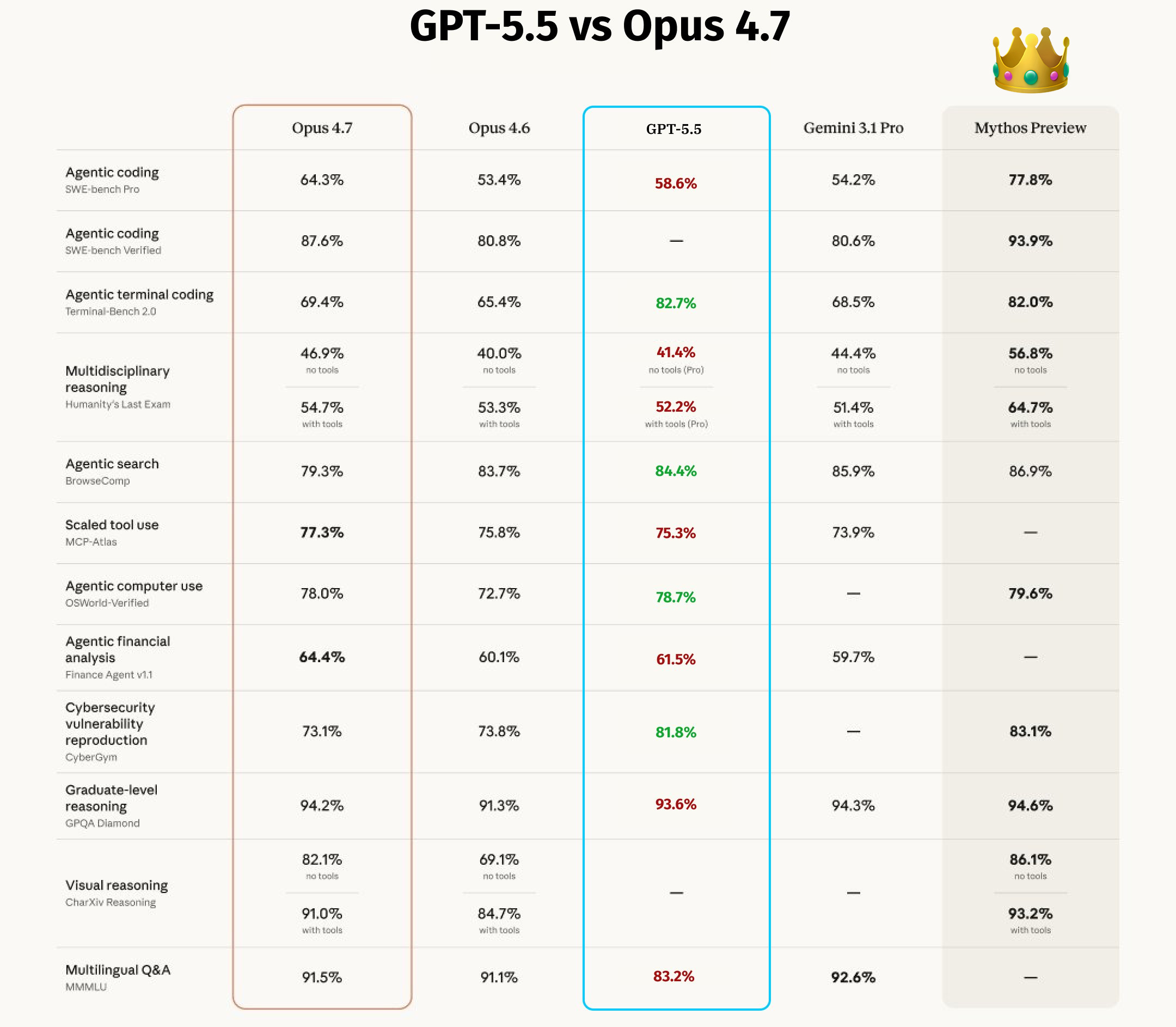
🤖 First Thoughts on GPT-5.5 (and Opus 4.7 Follow-Up)
You barely have time to get used to a new frontier model before a new one comes out, these days. I was starting to sour a little on Opus 4.7, preferring Opus 4.6 on the ‘flavor/vibes’ front when GPT-5.5 burst on the scene like the Kool-Aid Man.
It’s very smart on the benchmarks, taking the lead in many fields (though not all! Opus still mostly leads on coding/software-engineering/tool use, even if GPT is improving).

Clearly, they are targeting the same market as Anthropic now, with maybe a bit more scientific flavor, which reminds me of DeepMind:
The gains are especially strong in agentic coding, computer use, knowledge work, and early scientific research.
But, well, Mythos is still in the wings:
Nvidia has announced that 10,000 of its employees got early access to GPT-5.5:
Debugging cycles that once stretched across days are closing in hours. Experimentation that previously required weeks is turning into overnight progress in complex, multi-file codebases. Teams are shipping end-to-end features from natural-language prompts, with stronger reliability and fewer wasted cycles than earlier models.
So this model was trained on Nvidia Blackwells, is served on Blackwells, and is helping Nvidia produce and design the next generation of GPUs. 🔄
So far, my experience with GPT-5.5 is very positive.
I didn’t expect it to be this fast. I’m not sure if it’s because it’s being inferenced on a new fleet of Blackwells 🤔
OpenAI revealed that the model was trained on new Nvidia chips: “GPT‑5.5 was co-designed for, trained with, and served on NVIDIA GB200 and GB300 NVL72 systems” and that they used it to help optimize their inference infrastructure. Maybe that’s what I’m seeing!
But whatever the reason, I find 5.5 fast enough that I now always leave it in ‘extended thinking’ mode, while with GPT-5.4, I switched back and forth depending on the question. I could be getting responses faster, but I’d rather trade that time for even better responses.
The model doesn’t have much flavor, it’s a little bland, but at least it’s not annoying either. I’ll take it. ¯\_(ツ)_/¯
Pricing is higher than 5.4 per token (but as I wrote earlier, that only tells you so much).
In fact, the vanilla 5.5 is a little higher than Opus 4.7, and GPT-5.5 Pro is significantly higher (note that this is a log chart, because if I had kept it linear, Pro’s output pricing would be in its own zip code):
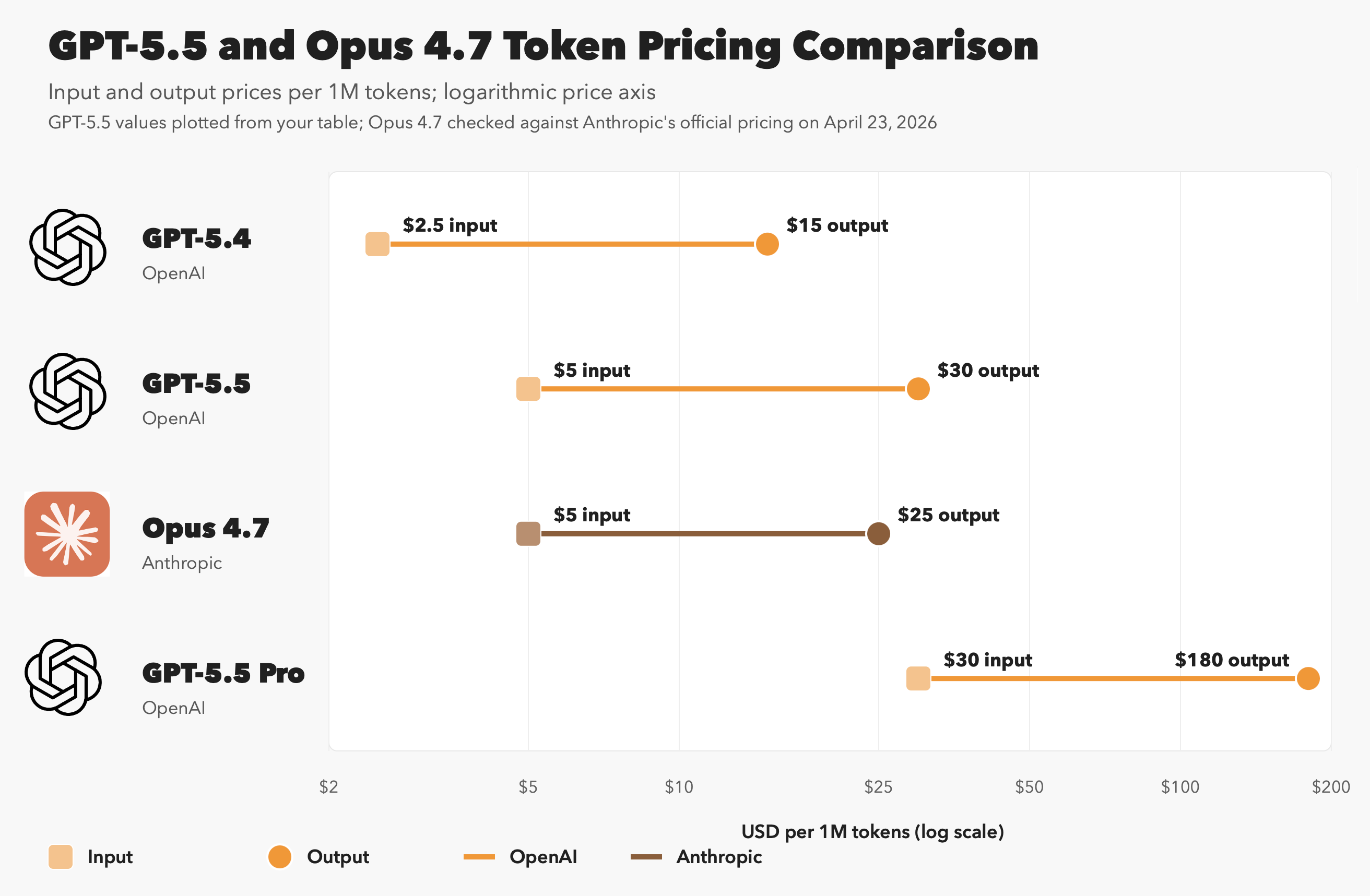
But as we mentioned earlier, token use for the same actions can vary a lot across models, and 5.5 generally seems more efficient than 5.4.
Pancreatic Cancer mRNA Vaccine Shows Promising Early Results 🧬👩🔬🧫
Pancreatic cancer is *terrible*. The survival rate is low, it kills people quickly, and is very resistant to immunotherapy.
Less than 13% of people diagnosed with pancreatic cancer live for more than five years, making it one of the deadliest cancers. There is no routine screening for pancreatic cancer, such as colonoscopy or mammogram, and symptoms typically don’t show up until the disease is advanced. Once detected, there are few options for treatment. Only about 20% of cases are operable, which is currently required for someone to be eligible to join a pancreatic cancer vaccine trial.
Every time I hear of it, I think about Steve Jobs 😢
(His was actually a neuroendocrine tumor, the rarer, slower-growing type)
There is a vaccine called autogene cevumeran (also BNT122). It’s developed by BioNTech and Genentech. It's a therapeutic vaccine, meaning it's given after surgery, not as prevention before diagnosis.
Each dose is custom-made for a single patient and based on their tumor DNA. The mRNA instructs the immune system to recognize up to 20 targets specific to that patient's cancer, so that your own body can fight it off and prevent recurrence after surgical removal of the tumor (it’s hard to get all of it).
So for that vaccine, the original phase 1 enrolled 34 patients; 28 underwent surgery, 19 received atezolizumab, 16 received the personalized vaccine, and 15 went on to receive mFOLFIRINOX. Of the 16 vaccinated patients, 8 generated vaccine-induced T-cell responses.
The latest six-year update, presented at AACR 2026, shows that among the 8 patients whose immune systems responded to the vaccine, 7 were still alive 4 to 6 years after surgery. Among the 8 non-responders, only 2 were still alive, with a median survival time of 3.4 years.
Now before we get too excited, this is still phase 1 evidence, small sample, etc. It’s not randomized vaccine vs no vaccine, it’s responders vs non-responders, so there’s selection bias.
BUT
It’s also not nothing. The mechanism is measurable, the T-cell response seems durable, and the survival rate diff isn’t marginal even if the sample is small.
And it was promising enough to trigger a phase 2:
The findings were promising enough to advance the vaccine to a larger randomized Phase II trial (NCT05968326), which is now underway at dozens of sites worldwide, enrolling people with newly diagnosed pancreatic cancer who have not yet received systemic therapy. After surgical removal of the tumor, they will be randomly assigned to receive autogene cevumeran, Tecentriq and mFOLFIRINOX chemotherapy or the chemo regimen alone.
I hope results with a larger sample are as promising 🤞
🎨 🎭 Liberty Studio 👩🎨 🎥
🎬 Where Did All the Interesting Faces Go? 🎞️
If you were an alien who could only look at films and TV shows from the past few years, you’d think that humanity’s not that varied. All kinds of interesting faces rarely make it to the screen anymore. 👽
Don’t get me wrong, pretty people have always had a big advantage, especially on the big screen (if someone’s face is going to be 30 feet tall, it makes sense). It’s part of our evolutionary wiring that we like looking at beautiful people.
But I think we’ve pushed it too far, and we’re losing something by flattening the world and only playing with a few notes in the scale 🎹 Some stories are about glamour or whatever, but others are better if not everyone looks like an actor.
The video essay above shows a lot of examples and makes a compelling case, IMO. The argument makes sense in the abstract, but when you SEE it, it has a lot more weight.
Who’s hiring the Steve Buscemis anymore? There must be lots of great actors out there that just aren’t being cast because they don’t look like underwear models.
any AI starting points\prompt for old photographs rebuild?