647: AI Labs Nationalized by Vibes, Nvidia's RAM Double-Dip, GPT-5.6, Codex's Taste Economy, OpenAI's Valuation Math, The Violent Inside of a CT Scanner, Modern Sunscreen, and Billy Corgan
"the inherent asymmetry between attack and defense"

To acquire immunity to eloquence is of the utmost importance to the citizens of a democracy.
—Bertrand Russell

🎶🎼😃 Here are two concrete tricks for getting unstuck musically, wrapped in a love letter to music. 💌
If you’ve been on this steamboat for any amount of time, you know I love music.
It’s one of the best things in life!
It’s a powerful drug without the downsides. It can change your brain state, perception of time, your mood, it can transport you back in time, take you on all kinds of journeys.
And it’s also a social network (in the same way that sports are a social network — but I just never signed up for an account there 😅).
You meet a music fan who loves the music you love and you have something to talk about and share. I’ve really enjoyed seeing both my boys get more and more into music, and I love listening to songs with them (and I’m surprised by how they independently discover older music and like it just as much as I did when I was their age).
Sometimes all it takes is sitting back with headphones and truly paying attention to discover a whole new layer to a song you’ve heard 100 times.
There are two things I’ve been experimenting with lately with music that I want to tell you about.
• Trick 1: Ask AI what to listen for 📋👂
The first is asking an AI for what you should pay attention to and context on a song or album. I think I got this idea from Tyler Cowen, who asked ChatGPT about a Sibelius symphony or something like that.
As I wrote last week, I’ve been getting back into Led Zeppelin lately, so I tried it on the first two albums and this is what I got. Here’s an excerpt:
The big thing to listen for: “light and shade”
Page’s central idea is contrast. Not just loud vs. quiet, but near vs. far, dry vs. roomy, acoustic vs. electric, precise vs. feral. […]
Bonham is the first hidden key. His drumming is not just “big.” He plays slightly behind the beat, with kick-drum figures and ghost notes that make the whole band feel like a giant animal turning around. On “Good Times Bad Times,” listen to the kick-drum triplet feel under the chorus. It sounds like overdubbed or double-kick flash, but it’s Bonham’s right foot doing something startlingly fluid.
John Paul Jones is the second hidden key. On casual listens, Page and Plant dominate. On deeper listens, Jones is often the adult in the room: bass countermelodies, organ, arrangement glue, harmonic sophistication. On “The Lemon Song” and “Ramble On,” he’s almost the lead melodic instrument.
It then went song-by-song over the two albums with a paragraph on each.
After my original try, I built a better prompt for you to play with (but don’t hesitate to customize it to your taste!):
I'm about to listen to **[album/song]** by **[artist]**.
Please make me a listening guide for me to read before/during listening. Do a web search first so you can use accurate context, release details, critical reception, artist quotes/interviews if available, and anything interesting that may not be in your general knowledge. Use the standard album edition unless I specify otherwise. Don’t use flowery prose, keep it conversational, clear, and to the point, like a music-loving nerd friend telling you about it. (If this is a single song rather than an album, skip section 3 and instead expand section 2 into a close listening of the track. If it’s just an artist, turn section 3 into an album-by-album guide, giving a quick overview of albums and which are considered to be the best and why)
Structure it like this:
1. **High-level context**: Give me the essential background on the artist, where this album/song fits in their career, when it came out, what was going on around its creation, and why people care about it. Keep this concise but rich. 2-3 paragraphs.
2. **What to listen for**: Give me 5-8 general things to listen for, depending on how much is genuinely interesting. These can include themes, lyrics, production, rhythm, arrangement, vocal performance, instrumentation, influences, genre context, sequencing, cultural impact, or easy-to-miss details. Prioritize things that will actually change how I hear the music. Also keep this concise but rich.
3. **Track-by-track guide**: For each song, give me a short paragraph that:
- Describes the song's mood, sound, and role on the album.
- Points out one or two specific things to notice while listening.
- Explains how to best appreciate it, especially if it is subtle, strange, repetitive, long, or easy to underestimate.
Please avoid generic praise. Be specific, concrete, and musically useful. Mention disagreements or mixed reception where relevant, but don’t hedge everything, I don’t need a Wikipedia page, just a concise tour guide. Cite sources for key factual claims, but don't let citations overwhelm the guide. Help me appreciate the music better while I'm listening.I've tried it with all kinds of stuff, from Leonard Cohen to Metallica to John Coltrane, and so far I really like what it gives me.
This kind of context really changes the listening experience. It’s a bit like having a fan of the band introduce you to them and give you pointers on what to listen for.
• Trick 2: Feed it your playlists and ask what's missing ☑︎☑︎☑︎
The second thing I’ve been doing is to export some of my playlists from Apple Music (but the same works in Spotify), upload them, and ask what it thinks and what I could add.
I first tried with a playlist that I shuffle while I read and write. It’s all instrumental music, stuff like Mammal Hands, GoGo Penguin, Tingvall Trio, Emil Brandqvist Trio, Portico Quartet…
I thought I had explored that sonic space pretty well, but it suggested about a dozen artists to check out, and I ended up adding about half of them to this playlist (or other playlists, if I liked them but they weren’t quite the right fit).
That’s a very high hit rate!
But this is what AI is good at: Pattern matching. If you give it a playlist with 87 hours of music (as I did), it has an *extremely* specific pattern to work from.
I’ll be doing the same with some of my other playlists.
This isn’t as fun as having music nerd friends to get recommendations from and listen to music with, but since there’s too little of that in my life anyway, this is the next best thing (and wouldn’t replace that anyway, it’d just give me more things to talk about with music nerds).
If you feel like you've been stuck musically, or going around in circles like many people do after their teens and early 20s, give this a try. It may help you discover new things or rediscover old faves.
Do you listen to instrumental music while working? What are your faves? What artists am I missing? Reply or leave a comment and tell me.
🇨🇦🫎🍁🇺🇸🦅🗽 Happy Canada Day to my fellow people of the North, and happy 4th of July to my American friends. 💚 🥃
Now is probably a good time to re-watch the excellent John Adams miniseries on HBO to be reminded of how the USA was founded.
🐦🦉🐦⬛☁️🐟🐠 Birds are the fish of the sky.
🔎📫💚 🥃 If you want Liberty’s Highlights to continue, this is the moment. Become a paid supporter.
Without your support, this steamboat sinks 🌊🚢⚓
🏦 💰 Business & Investing 💳 💴

🤖🤖🦅🇺🇸 De Facto Nationalization by Vibes: A Terrible Way to Regulate the AI Labs 🗽⛓️
Both Anthropic and OpenAI have new frontier models that are being blocked from public release by the U.S. government right now.
There doesn’t appear to be a real process, just whatever top officials or the president feel like at the moment (just like the supply-chain risk designation is just a vibe, it seems, and nobody quite knows what it means anymore).
Is ‘nationalization’ too strong? At this stage, probably. But functional control matters. The power to decide what a company can ship, when, and to whom is arguably the most important lever of all. Ownership without a say over output is no longer full ownership.
And if this is happening with these models, why wouldn’t it happen to the next ones, which will be more powerful and thus potentially more dangerous? Unless something changes, that is. Do we need a breakthrough in guardrail technology? A step up in mechanistic interpretability, classifiers, and general model security..? 🔐🔍
But if the gating isn’t based on security facts, what exactly would better interpretability and classifiers unblock? 🤔 (It’s like the old saying: You cannot reason a person out of a position they did not reason themselves into.)
That’s not to say that there can never be any reasons for blocking the release of models, but the lack of clarity and transparency seems worse than the kind of regulation that was feared not long ago.
Good regulation should at least try to be fair, legible, and predictable, so businesses can make plans and comply with the rules. Whatever this is, it doesn’t look like that.
In fact, because Mythos was only available to ‘defenders’ to harden software, blocking it (and Fable, the heavily locked-down version of Mythos that was briefly public) probably weakens the state of readiness for cyber attacks and cyber crime. Same with the new GPT-5.6 (more on that below), which is apparently in the same ballpark when it comes to finding (and fixing) security holes in software.
I’d certainly feel better if the engineers who maintain mission-critical code weren’t wasting a single day and still had access to the best models rather than being downgraded for an unknown period of time.
There’s also a slightly absurd recursive version of this: Anthropic itself got downgraded. The order reportedly applied to “any foreign national,” including Anthropic’s own foreign-national employees, and the company said it couldn’t reliably enforce that person-by-person, so it initially shut off Fable 5 and Mythos 5 for everyone. The company whose CFO says Claude Code writes 90%+ of its code spent weeks with its own internal AI stack kneecapped (reverted to Opus?) by a Friday-evening government letter (with 90 minutes to comply 😬).
Maybe if the attackers (🏴☠️) were all only using Anthropic and OpenAI models, restricting access would be a net positive because of the inherent asymmetry between attack and defense (you only need to get in once vs you need to stop all attacks), but because Chinese models keep improving rapidly in the meantime (eg. GLM-5.2), any lost time for defenders matters.
It reminds me a bit of the encryption wars in the 1990s, when the government tried to ban strong encryption from being “exported” outside the US (limiting it to weak 40-bit symmetric encryption and 512-bit RSA). In practice, strong encryption was available anyway, but the population of weak targets for black hats became much bigger.
Let’s do a thought experiment. 🤔💭
What if, a few years ago, the government had told Amazon that they couldn’t release a certain AWS feature because so much of the web’s critical infrastructure was hosted on AWS and there were large systemic risks from it? What if you screw it up and hospitals, banks, the power grid goes offline? What if outages or security flaws end up costing the economy billions of dollars in damages and downtime?
What if the government had told Meta that they couldn’t do XYZ on its apps because too much of the country’s communications was going through Facebook/WhatsApp/Insta and mistakes or successful attacks on the system could give adversaries access to personal, potentially sensitive information on hundreds of millions of people, millions of businesses, and cause disruptions to all kinds of things?
What about Google? How much of society relies on Google Search, Google Maps, Gmail, YouTube..? That’s a big risk if things go wrong! etc.
All these arguments are not crazy on their face.
Maybe it’s because the “old” Big Tech accumulated power slower than the AI Labs, so a bit like what they say about going bald (👴), we didn’t notice it that much from day to day until it was pretty far along. With OpenAI and Anthropic, similar magnitude of power was accumulated in just a few years, so their rise is way more visible. And how much more power will be accumulated in the coming years is unknown, and possibly very large (and humans love to extrapolate lines into infinity, both on the way up and down).
Civil/military dual-use is a bigger worry with AI than most other Big Tech platforms, that matters too.
There are plausible arguments for why the labs should be treated differently.
But I’d like to see it done transparently, based on logic and facts, rather than vibes and petty politics. With the current system, we get all the downsides of heavy-handed regulation with basically none of the upsides, because by doing it the stupid way, I don’t think we’re really reducing the risks much (on top of what is being done by the labs, I mean). 🤔
🚨📰 Update: Last night, after I wrote this, it was announced that the US gov’t was allowing Anthropic to bring back Fable 5.
I think that everything above still stands, because there’s still no clarity on how frontier models are regulated, and the process still mostly seems to be based on vibes and convincing some officials behind closed doors.
One of Anthropic’s arguments to convince the gov appears to have been that other models could do the same exploit that an Amazon researcher had uncovered for Fable 5:
The export control directive on June 12 came after the government became aware of a report in which Amazon researchers had found a method of bypassing Fable 5’s safeguards: prompting it so that it identified a number of software vulnerabilities. In one case, the model produced code demonstrating how the relevant vulnerability could be exploited. Over the past two weeks, we have worked closely with the government and other partners, including Amazon, to review the report and evidence.
Our testing confirmed that many less capable models—including Claude Opus 4.8, GPT-5.5, and Kimi K2.7—could identify the same vulnerabilities as Fable 5 did in the report. When it came to the demonstration of how to exploit the single vulnerability, every model we tested could produce the same demonstration as Fable 5 (including Claude Haiku 4.5, Sonnet 4.6, Opus 4.6, Opus 4.7, Opus 4.8, GPT-5.4, GPT-5.5, and Kimi K2.7).
The redeployed Fable 5 will have a new classifier/traffic cop in front of it that should be even better at refusing queries about the forbidden topic of cybersecurity. 👮♀️ But that classifier was always going to be updated and refined over time to block jailbreaks. I doubt that the ban really changed much there.
The real fix was Anthropic proving the banned capability was already everywhere, including in HAIKU 4.5 (an old, tiny model) and a free Chinese model. The ban blocked the model during its most profitable period, and likely changed nothing.
I wrote about the impact of this temporary ban, and for another angle, Dean W. Ball explains one of the other dynamics well:
Consider, in particular, some industry dynamics:
Frontier models are trained at an enormous cost, and a significant fraction of that cost is recouped in the few post-release months that they are broadly available. After that period elapses, the models become sub-frontier, competition emerges, and margins compress. Every week of delay is eating into the narrow window that labs have to make their accounting work.
The ongoing AI infrastructure buildout—the one that is, according to former US AI Czar David Sacks, essential to the US economy, assumes a functionally global total addressable market for US AI services. No one is building $100 billion dollar data centers to serve frontier models to whatever 100 companies the US government will allow access. The current US policy of restricting model releases so severely thus risks making what the AI bears have been saying (wrongly) for years suddenly become true: the US massively overbuilt AI infrastructure. In the bears’ minds, it would be because of demand that never materializes. In reality, this would happen because of demand that the US government renders unlawful.
Fable is back, but the rules of the road for frontier models are still incredibly uncertain and foggy.
Nvidia’s Memory Double-Dip Is a Pricing-Power Tell 😎🫳💰💰 (How Do You Like Them Apples Now? 🍎)
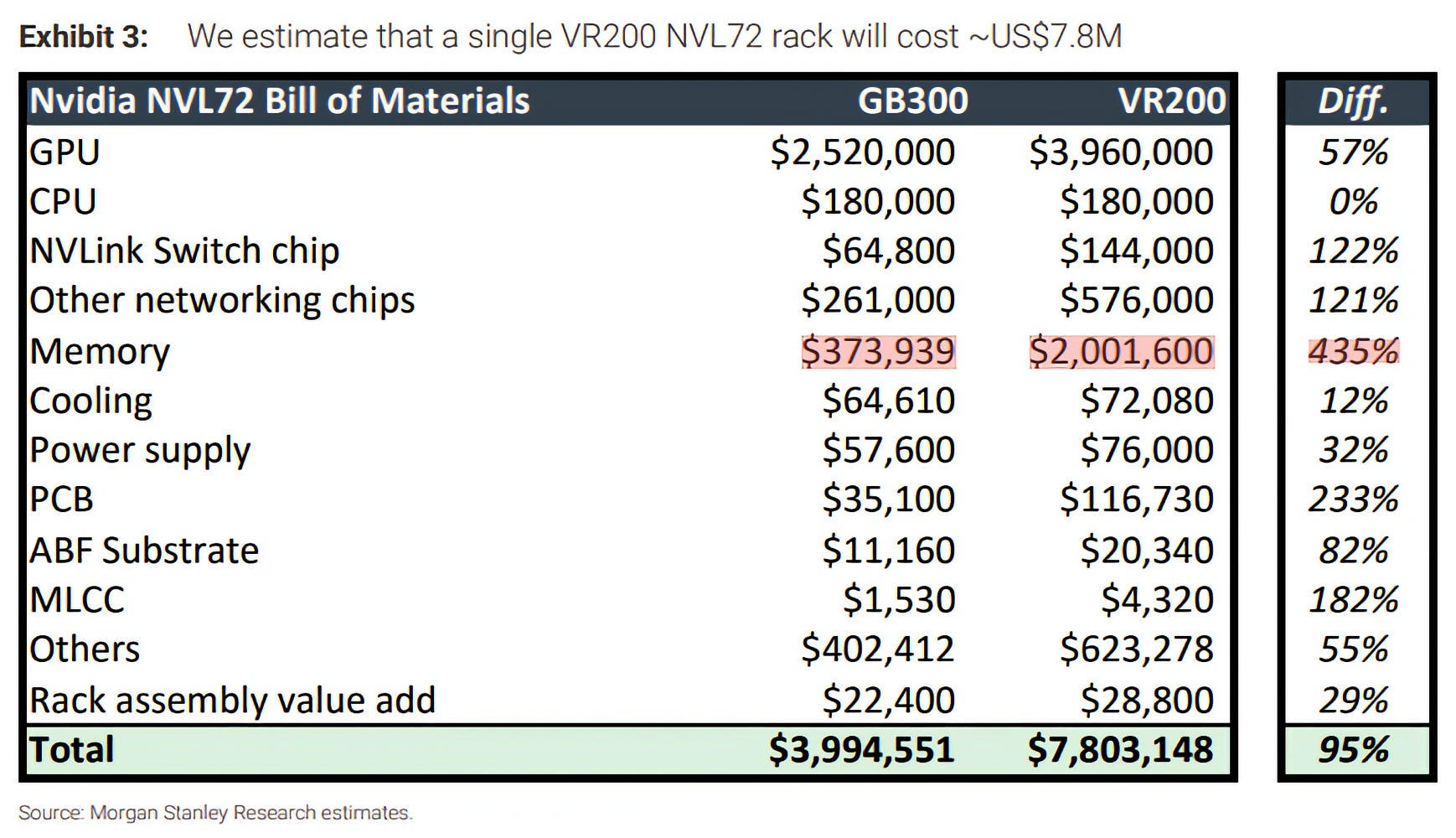
Jensen saw the memory crunch coming. He made very large deals before anyone else and locked down a ton of capacity.
And he’s been passing along price increases to Nvidia’s customers fully, charging Nvidia’s margins on top, which his competitors haven’t been able to pull off.
It’ll certainly be a canary-in-the-coalmine that competitive pressure is rising and their differentiation is fading if they ever have to stop putting their margins on top of memory 🤔
I don’t have visibility into the COGS for Blackwells and Rubins (other than estimates, like those above), but I can imagine that this move is very profitable, especially if they’re reselling memory that they bought at the price from some months ago at today’s prices with that margin on top (which can be multiples of input cost, since Nvidia’s company-wide gross margins are 75%).
How long can they do this?
Apple is the clear analog here: They’ve long been able to put a large extra margin on top of RAM and flash storage because they have market differentiation and people who want an Apple device aren’t very likely to switch to an Android just because the memory upgrade is cheaper. 🍎
But the current memory price spike is so extreme that even Apple is feeling it. They've guided margins down as memory costs ~4×'d and recently announced Mac and iPad price increases (and everyone knows the iPhone will also get a price increase in the Fall).
🗣️ Codex Lead: When Anyone Can Build Anything, Taste Is the Scarce Thing 💾 🎨🧑🎨
Andrew Ambrosino leads the Codex desktop app team at OpenAI. I really enjoyed what he had to say to Lenny here.
They discuss a bunch of interesting things, including where the Codex app is going and how the team has been developing it. But the part I want to highlight comes earlier in the conversation: how AI is changing the roles of product managers, engineers, and designers when building things.
The old process existed for a reason. Implementation was expensive in time, money, attention, and coordination, so teams spent a lot of time upfront designing, speccing, and de-risking before anything got built.
But if implementation gets cheap enough, you can move much faster from idea → prototype → reaction → iteration. You don’t just design, then build. You can increasingly design by building.
That changes the internal shape of companies. 🏢
There’s also a trap here: a prototype that looks finished can smuggle in false certainty. In the Old Way™, fidelity was a signal. If something looked production-ready, it probably meant a bunch of thinking, design, research, and approvals had happened. Now fidelity can be generated early. The thing may look like a product, but if you poke at it, it’s made of cardboard and bird feathers.
That creates a weird new managerial skill: labeling the status of artifacts 🏷️.
Is this a sketch? A toy? A demo? A production candidate? A direction? A discarded branch with one good interaction pattern?
Teams may need better “this looks real but isn’t real yet” filters.
Andrew Ambrosino: One of the hardest things to do right now as a leader building these products is the inversion of the process.
Anybody can build anything now. I generally believe that, starting from scratch, if you talk to these models — ours or anybody else’s, really — you can stand up whatever feature you want. That’s not necessarily the hard part of software anymore, but it’s really cool. [...]
If you look back at the product process we’ve all run for a long time, it was kind of the opposite. It was research, ideation, maybe some prototyping. Even when we got past waterfall, it was still flavored by the assumption that implementation is expensive, so you want to de-risk implementation up front through documents, research, prototypes, because prototypes and designs are cheaper.
That has changed. That has totally changed. [...]
So the short answer is: it’s backwards. It’s not that people are doing fundamentally different roles, or focusing on different things, or that skill sets have vanished, or that roles have disappeared. It’s that the process is backwards.
Implementation is not the expensive part anymore. It’s, dare I say, taste.
It’s the curation process. Of those 90 attempts, what’s good about them? What should we fold into other aspects of this? How should we frame this? Should it be part of some other feature? How many segments should be in the toggle? All of those things.
Look at this graph that OpenAI recently published for internal Codex use:
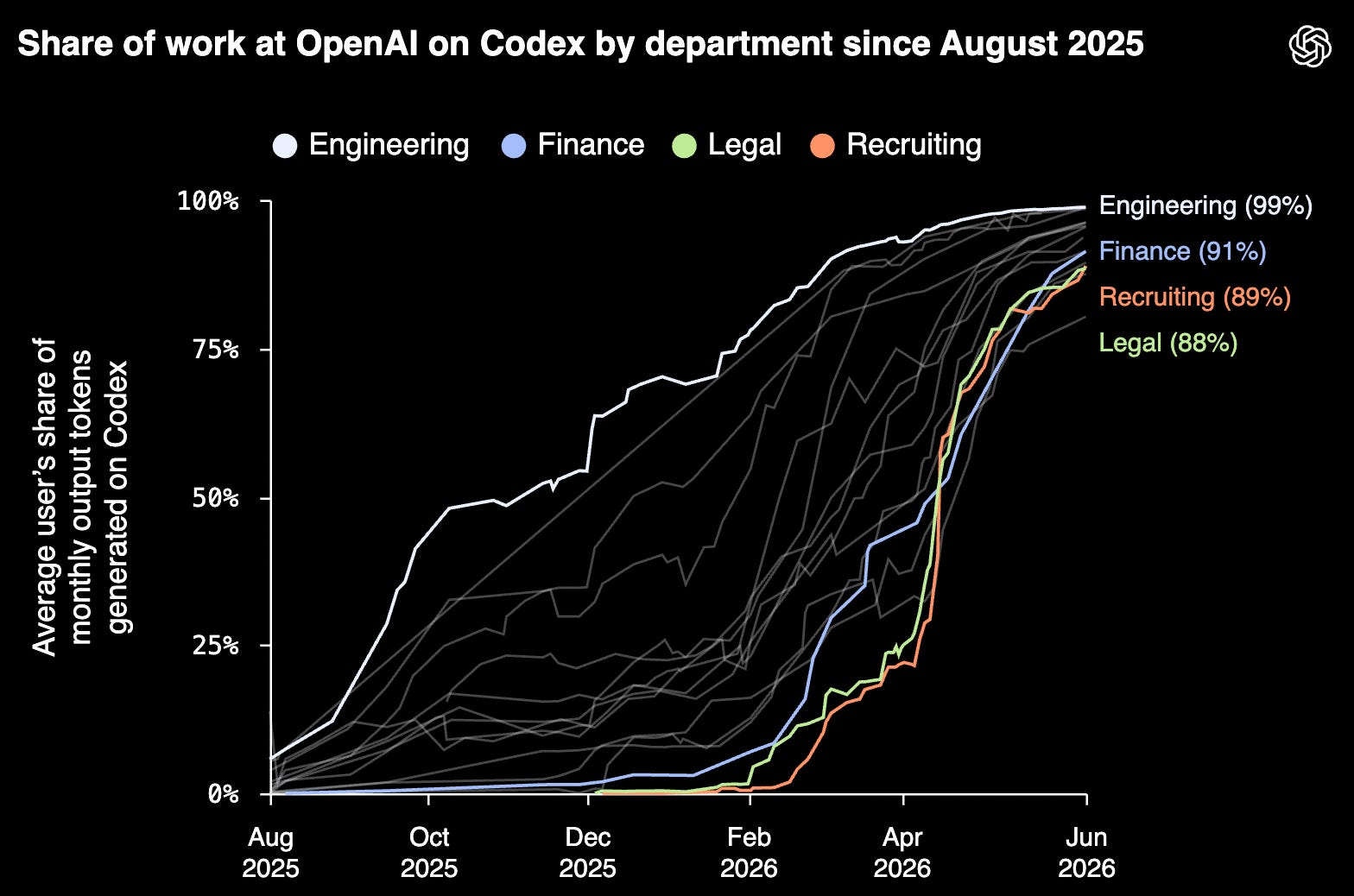
Codex isn’t just an engineering tool inside OpenAI anymore. The company says every department, including Legal and Recruiting, now uses Codex as its primary AI tool for work.
The usage is also compounding fast. Since August 2025, OpenAI says non-developer Codex users rose 137x among individual users, 189x among organizational users, and 12x inside OpenAI.
And over the past six months: “Research saw the biggest jump: by June 2026, median use was 56 times higher than in November 2025. Customer Support rose 32 times and Engineering rose 27 times, while Legal grew more gradually but still reached 13 times its November level.” 🚀
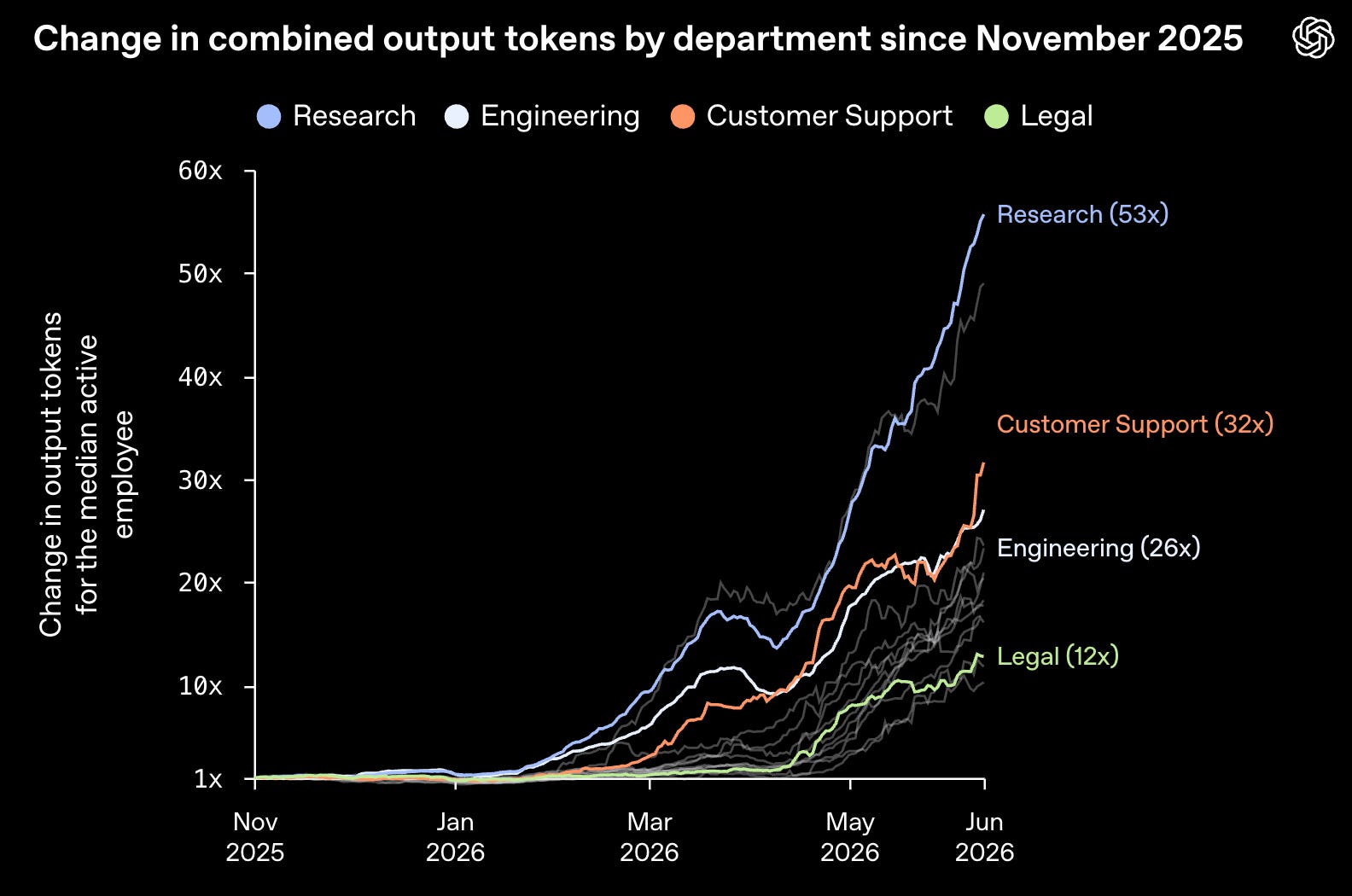
The scarce thing moves from execution to selection. If 90 people can make 90 plausible prototypes, the bottleneck is no longer “who can build?” It’s “who can tell which of these is actually good?” That makes taste less fluffy, not more. Taste becomes allocation: attention, integration, deletion, sequencing, framing.
Andrew Ambrosino: There’s a lot of this, and it’s not just happening here. You’ve seen many product leaders say, “PRDs are dead, prototypes are in,” and I actually don’t believe this at all.
I think one of the interesting things happening right now is that because implementation has gotten so cheap across every medium, it’s very tempting to jump straight to a prototype, especially if you’re not an engineer. Especially if you’ve never been able to write code, or never been interested, or never had the time.
It’s really tempting to say, “PRDs are dead. Let me just show you what I mean.”
What I’ve also noticed, though, is that for engineers, it’s really tempting to write a lot of documents — a lot of documents that are not worth reading. This is no shade on people writing documents. It’s just that if implementation is abundant, then it’s really important to pick the right format for the point you’re trying to make.
If the point is product clarity around a vague area, then it might actually be a document. If what you’re trying to do is get something in people’s hands to try out and stress-test an interaction pattern, it’s a prototype.
That’s the funny thing now: it’s really important to pick the medium.
Before we get carried away: these are OpenAI’s own numbers about OpenAI, and “output tokens” is not what you want to target. They're not necessarily correlated with value, especially if they become a known KPI target and get inflated unnecessarily (Goodhart’s law).
But even if we take all this with a lot of 🧂, the direction is pretty clear. Building products is changing rapidly and people’s roles are becoming a lot more fluid, rewarding high-agency and multidisciplinary skills.
And if there's one skill that will remain valuable and probably become more valuable, it's the ability to look at 90 different things and say that's the one. 🥇
This is probably a different piece, but it raises the question: Where does taste come from? How do you develop it? 🧑🎨🖼️
It's slow to build up and strengthen, hard to hire for, and usually, you develop it by doing reps. Does automation lead to more reps and faster feedback cycles, which helps? Or does the fact that builders don’t go into the details of the implementation anymore rob them of some important things they would be learning? 🤔
🗣️🗣️ MBI & Scuttleblurb on OpenAI Valuation Math and Specialty Insurance
Always a pleasure to listen to my friends MBI and David Kim (💚 🥃 x2). In this episode, they start with AI (what else?), but take a sharp left turn into specialty insurance and the state of the brokers (and how their talent sometimes gets poached).
All good stuff. The centerpiece is their attempt to use the leaked OpenAI financials to figure out what would have to happen from today’s valuation for shareholders to do well.
Let’s just say that if the math works, the units are in ‘multiples of Microsoft revenue’ 😅
🧪🔬 Science & Technology 🧬 🔭
🩻 The Surprisingly Violent Inside of a CT Scanner 😲
Maybe I’m the only one who had no idea that inside a CT scanner, the whole assembly with X-ray source and detectors is spinning. I expected some small sensor to be moving around, but seeing it without the cover made me realize that it’s a much cooler engineering challenge than I thought.
Because it's so cool, here's another one:
It looks straight out of a sci-fi film! Like an industrial washing machine designed by a spaceship engineer.
And here’s a different video of an even faster CT scanner spinning without a cover. It’s crazy. 🌀🔄
It looks less like a hospital machine than an inter-dimensional portal trying very hard to stay calibrated.
(In case you’re wondering: MRI scanners don’t spin like this. The big magnet just sits there. The brutal knocking sounds come from gradient coils carrying large, rapidly changing currents, which makes them vibrate.)
☀️ GPT-5.6: OpenAI Attacks Claude on Price, Not Just IQ 🌙

Okay, first, when the heck did OpenAI get good at naming things?
Maybe they asked GPT-5.6 to name itself? 🤔
Sol/Terra/Luna is Haiku/Sonnet/Opus level branding.
Kudos.
OpenAI isn’t just trying to beat Anthropic on raw intelligence here; it’s also attacking the framing, pricing, and token-efficiency story.
As mentioned earlier, we can't try this model because the U.S. government has asked OpenAI to only roll it out to a few approved organizations (in an internal memo, Sam Altman said the gov’t would literally approve “customer by customer” who could get access to GPT-5.6 😅), but we know a few things about it:
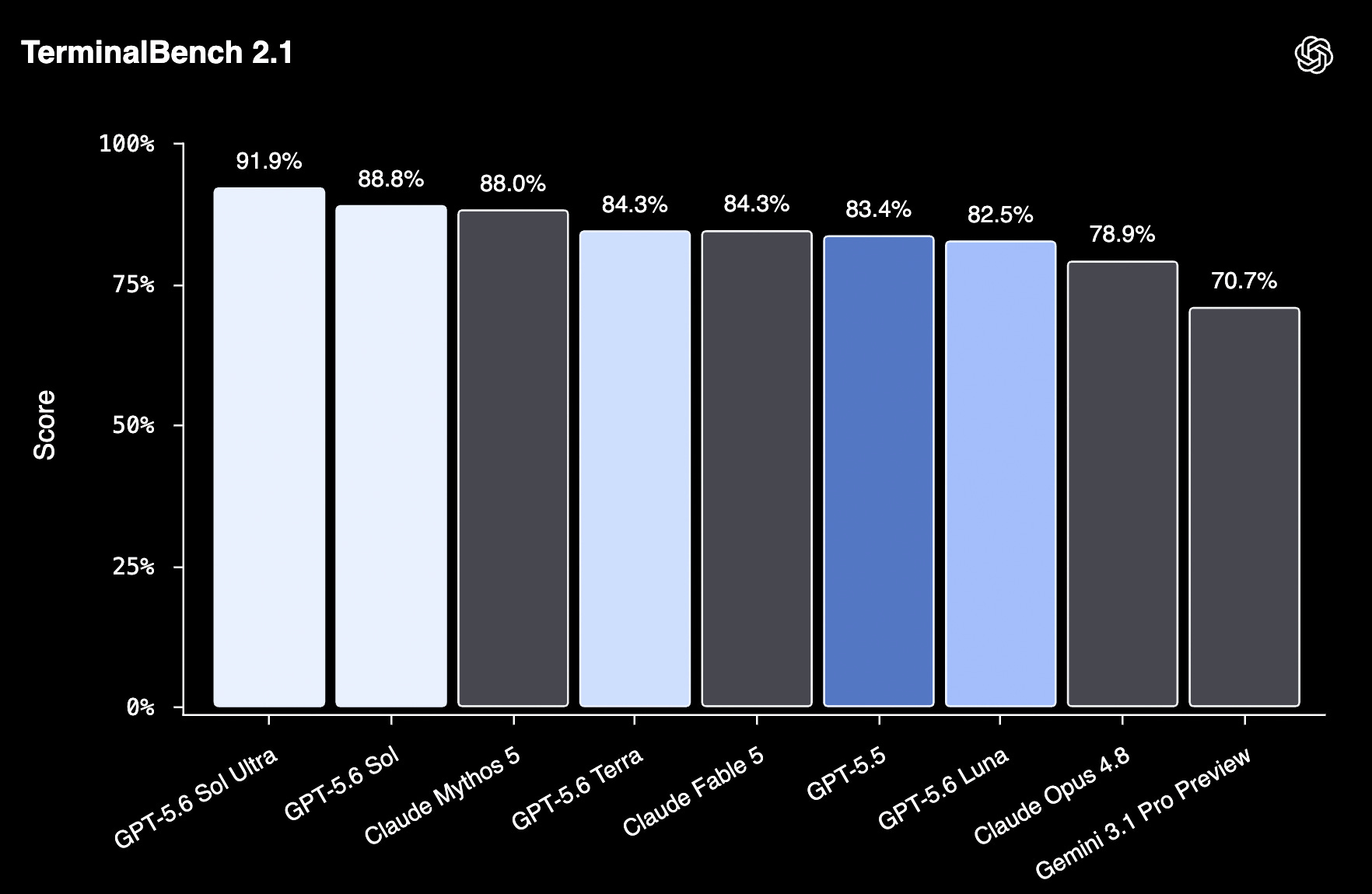
Both Sol and Sol Ultra (badass name) score higher than Mythos 5 on TerminalBench 2.1, but note that OpenAI is only providing a few bench scores, not the full panel that usually comes with a model release.
So let’s assume that they cherry-picked the best results. 🍒
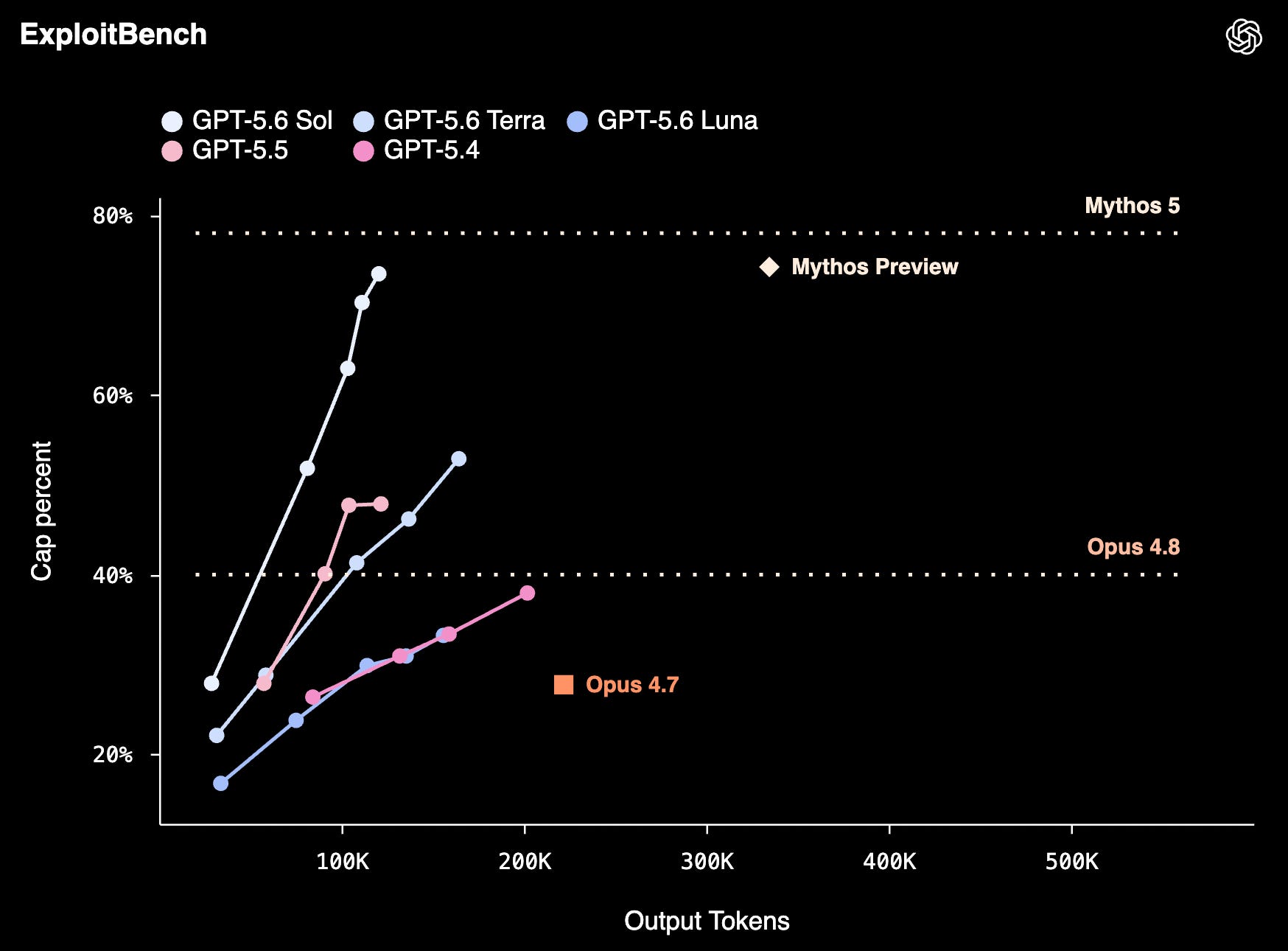
On ExploitBench, GPT‑5.6 Sol is competitive with Mythos Preview using only ~1/3 of the output tokens.
Note that they compare it to Mythos Preview, which I assume is not the latest version because I think Anthropic dropped the “Preview” from it.
One of the things that seems to be a strength of 5.6 is token efficiency. In other words, how much intelligence does it pack per token? Some models get there but need to use a lot more tokens than others. Claude has long been doing well on that metric, but it looks like OpenAI is improving.
Pricing is another lever being used:
Sol is $5 input / $30 output
Terra is $2.50 input / $15 output
Luna is $1 input / $6 output
For comparison, Anthropic announced these prices for Mythos and Fable (before they got pulled by the government):
Mythos/Fable 5: $10 input / $50 output
They claim that Terra provides GPT-5.5 level performance for half the cost, while Sol remains the same price as GPT-5.5 currently is. They haven’t yet said how much Sol Ultra will cost, but if it’s like GPT-5.5 Pro, it could be pretty expensive ($30/1M in, $180/1M tokens out).
So OpenAI is trying to make the story ‘similar frontier-ish capability, materially cheaper to run.’ Especially if the token-efficiency claims hold up in the real world.
I'm looking forward to trying it for myself and seeing the full benchmark card to see how it compares to other frontier models, at least on paper. The word on the street is that OpenAI's base model is not as big as Anthropic's latest, but that their RL is really good, which is how they are catching up to it in performance.
It’ll be interesting to see if Anthropic gets better at RL first, or if OpenAI catches up on pre-training 🤔
☀️🧴🇺🇸 The U.S. Finally Gets Modern Sunscreen (27 Years Later)
The FDA has approved bemotrizinol, also known as BEMT, Tinosorb S, or PARSOL Shield, as a sunscreen active ingredient in the US.
This is the first new sunscreen active ingredient added to the US OTC sunscreen monograph since the late 1990s. 🗓️
Why has the U.S. been frozen in time while Europeans have been putting this on their kids since 1999? One reason I could find is that the US regulates sunscreens as OTC drugs (requiring the long and complex GRASE approval), while the EU and Asia regulate them more like cosmetics.

Bemotrizinol is a chemical UV filter that protects against both UVA and UVB rays. Everybody focuses on SPF, but that’s mostly a sunburn/UVB number. It's UVA that penetrates deeper and drives most of the long-term skin aging (and likely contributes more to melanoma than people used to think). It’s also pretty photostable, meaning that it doesn’t degrade too fast when exposed to the sun (which is, y’know, nice for a sunscreen 😅).
I know that some people have been importing superior sunscreen from Europe or Asia for years. They get better protection, a nicer feel on the skin, and less of the eye-burning that many people get with the US formulations.
Personally, my family and I have been using mineral sunscreen for a few years (an Australian brand available here in Canada, Blue Lizard), but learning about this makes me curious to try the BEMT stuff (it was approved in Canada a few years back. I could have been using it all along).

🎨 🎭 The Arts & History 👩🎨 🎥
🎃🔨 Billy Corgan, Music Superfan 🎶
Something a bit lighter to leave you before the summer break.
I gotta say, I aspire to Billy Corgan’s musical knowledge and genuine appreciation for good music from all genres and eras. It’s a pleasure to listen to a real fan talk about something they love. The enthusiasm is contagious, and it’s making me want to listen to those bands.
To be honest, I hope that *my* enthusiasm is infectious to you too, sometimes.