

79: Bumble & Tinder, Apple Podcast Subscription Service?, Figma CEO on Design, AWS, CTV, Apple’s Hidden Matrix Coprocessor in the M1, and the Unit is the Datacenter
"If I see you play that flute again I’ll ram it up your..."

Mistakes breed like rabbits. 🐇
Success breeds like turtles. 🐢
(Is it pretentious to quote myself here? Probably, but we all need to care less what others think, and do what we want, when it doesn’t harm anyone…
I was thinking about actions that self-perpetuate or have inertia (in various directions, positive and negative), and the formulation above is what I came up with to try to compress the idea…
Basically, mistakes tend to lead to a lot of other mistakes quickly unless actively stopped, while success can also reproduce fast, but it's a fragile, vulnerable process with lots of chances of failure and a long treacherous road to the sea… There’s more ways to die than to survive. Something like that ¯\_(ツ)_/¯ )
Those who accuse others of being unfair to something in a negative direction should be careful that they aren't being unfair to it in a positive direction. Both are miscalibrated.
Ω How unfortunate for us late-bloomers that we pick what we want to study as a career when we are stupid teenagers.
If I had to do it again, I’m pretty sure I’d have done things differently…
Not that we can’t always imagine how things could’ve been better, but it’s certainly a bigger hurdle for people who take a while to grow into themselves and get their stuff together than those who are basically fully-formed and mature at 15. Oh well ¯\_(ツ)_/¯
♭♯ I wonder what the impact would be if Apple Music came out with a free tier on the exact same model as Spotify's (ad-supported).
Investing & Business

Bumble Origin Story/Original Sin
In celebration of Bumble’s coming IPO, here’s the backstory of the company’s founding and, apparently, the original sin at Tinder that led to it:
"Bumble was founded by Whitney Wolfe Herd shortly after she left Tinder, a dating app she co-founded, due to growing tensions with other company executives... Wolfe sued Tinder for sexual discrimination and harassment and settled for just over $1 million in September 2014." (Source)
Looks like whatever happened, it’s costing Tinder a lot more than $1 million…
It could also be that all this is a lot more complicated than that (it usually is) and I’m lacking the extra context, so my confidence in this being the definitive interpretation isn’t very high.
Rumor: Apple Podcast Subscription Service
I’ve made my worries clear about Spotify’s push into podcasting (see edition #18). Now there’s a rumor that the podcasting gentle giant is waking up from its slumber and may be creating a subscription model.
The question is, will it be a counter-weight to the more walled-garden approach and help keep the ecosystem more open, or will it be another walled-garden approach?
Ideally they would create some way for big podcasts to partner into their service, and offer ad-free and/or bonus content to subscribers (maybe rolled into Apple Music subs or the Apple One subscription) and do a rev-share with them, splitting the money using some kind of formula that takes into account plays and time listened or whatever.
This would make Apple’s subscriptions stickier, because it’s a nice benefit to not have ads on many of the big podcasts and bonus content (you may not subscribe just for that, but once you’re in, it’s one more reason not to leave — similar to a lot of Amazon Prime’s side benefits). And it would leave the ecosystem open by being purely additive to it rather than subtractive (taking things away and putting them behind paywalls, making them work in only one proprietary app).
Or maybe on top of it a kind of Patreon-like way to support specific podcasts, with a rev-share to get access to that infrastructure and integration into the Podcast player and with Apple accounts.
Unfortunately the rumor has basically no details at all and is just an exercise in turning “Apple may do subscription service for podcasts” into a 500-word article, so we’ll have to wait and see.
Interview: Dylan Field, Figma CEO and Co-Founder
Patrick O’Shaugnessy has a good interview with Dylan Field (gotta love that @Zoink username).
What interested me most about it was how design is being democratized and made more accessible by these types of tools, and various forces pushing all kinds of companies and products to value more highly good design (or at least not horrible).
The whole consumerization of IT and Apple’s gigantic success over the past decade has no doubt played a role.
But I also think one of the side-effects of the internet is this Cambrian explosion of creators of all sorts, and the larger that part of the funnel is, the more people will also make their way to the “actually being good designers” on the production side, and “being good appreciators of good design” on the consumption side.
This thread on Twitter by Field is very interesting, with this important insight:
IMO a lot of companies misunderstand the role of [customer support]. Support isn’t a cost center, but rather a key partner to marketing, product and engineering.
Marketing: great Support experiences breed customer evangelism. A strong product education effort equips users to teach their friends / coworkers, building the [Figma] community. Meanwhile, past conversations help PMM’s find the right language to talk about product.
Product: How do you decide what to build? One of the key inputs should be a conversation with your product Support team. They are on the front lines every day and have their finger on the pulse of the customer.
When we think about building a new feature at Figma, we start by talking with Support and looking at tickets. As we go through the process of defining the feature, we often reach back out to customers that have written in to help us understand requirements / scope.
Finally, the relationships support creates with customers helps product validate that we have reached a solution that meets the customer’s needs.
Engineering: it’s popular to think of building software as a cold, logical process but sometimes it’s just plain messy. Whether it’s a weird, hard to reproduce bug or (G-d forbid) an outage, Support is our first line of defense.
They debug with customers and use judgement to decide when to escalate issues. When engineering is trying to get more data on a bug that only affects a small portion of our user population, support is a key partner.
h/t Paul Barnes for the Twitter thread
AWS: Looking Forward… From How It Looked Back Then
Good thread by MI Capital looking at how AWS was perceived by many market participants until Amazon broke it out in its financials and revealed how profitable it is, and the various bear case theses.
Would be interesting for those of you who have been keeping an investing journal and followed Amazon before 2015 to look at what you actually thought about AWS at the time, without the benefit of hindsight and how our memory tends to re-write the past to make things seem more obvious than they actually were.
Crowdstrike CFO on Recent Debt Raise, M&A
A few days ago I wondered out loud what Crowdstrike was planning with all the dry powder they had on their balance sheet and all the debt they were raising ($1bn of cash + expanded revolver to $750m+$250m + $750m in new bonds… That’s a lot of moolah).
Looks like the CFO recently answered my question (well, as much as possible without actually announcing an acquisition):
We really looked at how our balance sheet is looking today and are we leveraging our balance sheet appropriately, and we realized that we were wildly under leveraged on our balance sheet. And so we look at our balance sheet as a competitive advantage [...]
we looked at a variety of things. We looked at a high-yield bond, which is what we did. We looked at things like convertible offerings. We looked at equity. And at the end of the day, the high-yield bond offered us really, really low cost of capital, no dilution to our shareholders. And we were very, very happy with the results. The coupon rate that we were able to achieve, I believe, was the lowest coupon rate ever for a debut offering in the high-yield space. And we're going to obviously use it for the bigger picture of general corporate purposes. But within that, there's a probability that we would use it for M&A.
For reference, the 2029 notes have a coupon of 3%.
as someone who's been acquired a few times in my career, I can tell you that we look at the balance sheet of who's acquiring us and the wherewithal of who's acquiring us. And so as we go out there and we compete for valuable assets, we think it's a strategic advantage to be able to show our strength and be able to show the target that we can, a, afford you when we go after and try and acquire you, but then also support once we -- one you've been acquired. And so once you've been brought into our fold, you were able to -- we're going to take care of you. That's part A, and I think a lot of people get that. I think part B, equally as important to me as I look out into the future. This is the first step that gives us access to very, very deep pools of capital in the rated debt market, right?
So today was our first step. This is our first interaction with the rating agencies. They're getting to know us, the debt holders are getting to know us. So that in the out years, pick a year, I don't know, 2, 3, 4 years out, when there's a potential opportunity that is too good to be true but it's billions in the cost, well, then it's going to make it all the more easier to go out and raise a significant bond raise.
So not only are they stockpiling for the near future, but they’re looking farther out and preparing in case they ever need the elephant gun and want to pull the trigger with debt to keep dilution lower. Certainly a nice sign of long-term thinking…
h/t North Bluff Capital for getting to this transcript before I did and highlighting that section.
Programmatic CTV Ads
Programmatic connected TV advertising will continue to soar in the coming years -- expected to rise to $6.73 billion this year and $8.7 billion in 2021, according to eMarketer. (Source)
+54% vs 2019, and “a 29% gain expected for the coming year”.

☁☁☁
Science & Technology
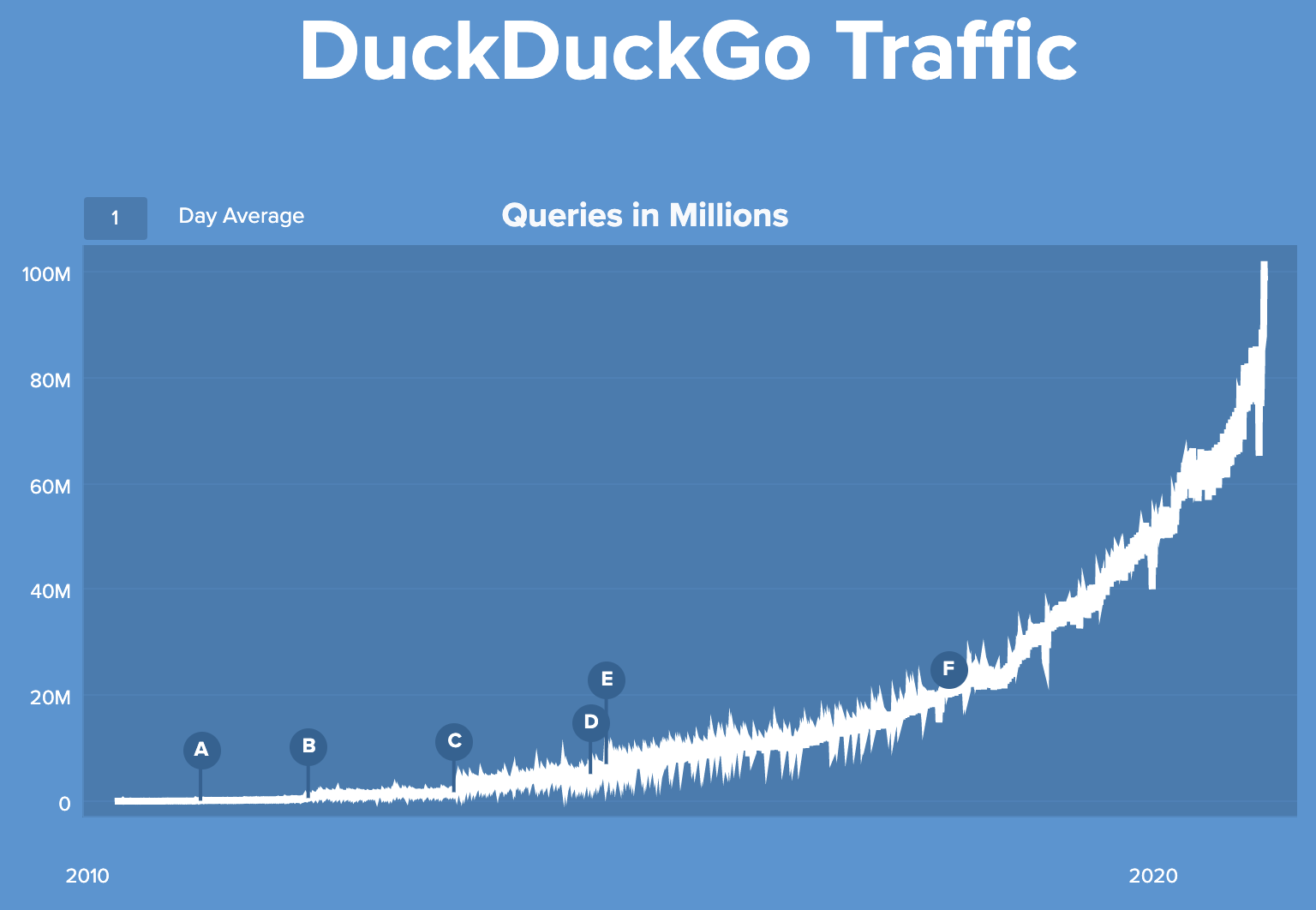
DuckDuckGo Hits 100 million queries in a Day
Not bad for a privacy-focused search engine with a weird name and 116 employees (yes, I’m aware that they use the Bing API as a major data source, but that’s not cheating, that’s smart).
It’s been my primary search engine for about 85% of my searches for a while now. For the past 10 years, I’ve given it a try periodically, but it never stuck long-term… It was always either too slow, or the results not quite good enough.
But the last time I tried, maybe a year-and-a-half ago (I’m no good with time), it was fast and good enough, and now when I want to search via Google, I write my query in DDG with the “!g” operator and it proxies me straight into Google.
One nice touch that I like is being able to change the default theme to a black background and highlight colors of my choice. I’m sure I could do that in Google too with a browser extension, but it’s nice that it’s built-in.
As I wrote in edition #11:
A while ago I realized that the majority of my searches were more navigational than actual research. I just want the search engine to give me some company’s website or an artist’s Wikipedia page or a film’s IMDB page or whatever. I know where I want to go, I just want a handy link to click on.
I think part of it is that I just like trying different things and not putting all my eggs in the same basket. I also bounce between 3-4 different web browsers and use 3 different apps for my writing and notes.
Interview: Kyle Kingsbury
Good interview by Peter Attia from 2019:
They talk about a bunch of stuff, but there’s a #ShroomBoom angle too:
Kyle talks about his battle with depression and a close call with suicide that lead to life-changing experiences with psilocybin and ayahuasca—which really became the turning point in his own journey towards being more emotionally healthy, finding inner peace, and being a better husband and father.
Apple’s Hidden Matrix Coprocessor in the M1
Matrix math, that is, not the ‘humans-as-batterie’ nonsense.
Apple has indeed extended their ARM CPU cores with AMX instructions. How do we know? Apple has kept this a secret. There is no manual publicly available describing these instructions. However developer Dougall Johnson has done a reverse engineering effort on the M1 to discover this coprocessor. His efforts are described here.
For matrix related math operations Apple has special libraries or frameworks such as Accelerate, which is made up of:
vImage — higher level image processing, such as converting between formats, image manipulation.
BLAS — a sort of industry standard for linear algebra (what we call the math dealing with matricies and vectors).
BNNS — is used for running neural networks and training.
vDSP —digital signal processing. Fourier transformations, convolution. These are mathematical operations important in image processing or any signal really including audio.
LAPACK
Why a coprocessor? What’s the difference with the other accelerators that sit on the chip die (GPU, neural engine)?
If you need to jump back and forth between CPU processing of data and Neural Engine or GPU processing of data, then you loose a lot of performance just in syncing up stuff.
This is where coprocessors are a benefit over accelerators. Coprocessors sit and spy on the stream of machine code instructions being fed from memory (or cache more specifically) into the CPU. Coprocessor are made to react to particular instructions they where made to process. The CPU meanwhile has been made to mostly ignore these instructions or help facilitate the handling of them by a coprocessor.
What we gain from this is that instructions carried out by the coprocessor can be placed inside your regular code. This is different from say a GPU. If you have done GPU programming you know that shader programs are placed into separate buffers of memory, and you have to explicitly transport these shader programs to the GPU. You cannot place GPU specific instruction inside your regular code. Thus for smaller workloads involving matrix processing AMX will be better than the Neural Engine.
What is the catch? You need to actually define the instructions in the instruction-set architecture (ISA) of your microprocessor. Thus you need much tighter integration with the CPU when using a coprocessor than when using an accelerator.
You can read Erik Engheim’s whole piece here.
The Unit That Matters Will Be The Datacenter
Interesting post by John Masters, mostly about Intel and its new CEO, but also about the future:
The next decade isn’t going to be “x86 vs Arm”, or “x86 vs Arm vs RISC-V”. It isn’t going to be some motherboard with a chip and a bunch of PCIe slots you plug whatever adapter widget into. Nobody cares any more. Compute is a boring commodity. It’s something I can license and build for myself if I’m large enough (and many are). The future is about carefully marrying all of the different possibilities together into a whole that includes both compute, as well as acceleration, and leveraging hw/sw co-design.
Similar to what Jensen Huang has been saying for a while, though he’d probably not call compute quite that commoditized… But I’m sure he’d agree that it’s the integration at the data-center level that will be the focus in the hyperscaler era.
h/t Gavin Baker

Remember March 2020?
Kinda crazy to imagine what this chart would look like if the whole planet hadn't taken all these measures. We'd probably have 10+ million deaths by now.
We recently passed 2 million deaths — that’s a population the size of the island of Montréal — could it have been 5x worse without masks, WFH, some lockdowns, hand-washing, closing restaurants & bars, etc? For an exponential process going on for 10+ months, for sure. Could it have been 10x or 20x worse? Who knows, maybe… At 20x that’s 40 million deaths, getting close to WWII civilian deaths.
There’s close to 8 billion people on Earth and only 93 million infections officially (more than that for sure, but not orders of magnitude), so from the virus’ point of view, it’s still greenfield out there, even if you only count the most vulnerable segment of the population.
…and we’re frozen in place.
The Arts & History
*Chef’s Kiss*
Yes, this is art.
Nick Cave Tells the Story of the Flute on ‘Breathless’
There’s a great track on the album ‘The Lyre of Orpheus’ by Nick Cave & the Bad Seeds that has very distinctive flute playing (in the intro, around 1:40min into it, and briefly at the end).
Conway introduced himself to Warren after the gig saying — “Good show, mate, but if I see you play that flute again I’ll ram it up your arse.”
So, Warren quietly put his flute away in its case and there it lay, untouched, for over a decade. [...]
So Warren does, like, another ten takes and they each sound progressively worse than the one before. Warren does the Walk of Shame back into the control booth.
“The flute sounds like shit,” I say to Warren.
“Right,” says Warren.
“How about we listen to them all back at the same time,” I say.
Warren says — “And let’s put some of them backwards.”
And I say — “And let’s detune some of them and stick them through a phaser, and drench the whole thing in reverb.”
For those who, like me, love these types of anecdotes about how music is created, here’s the story, as written by Cave (there’s a surprisingly touching ending to the story, that I won’t ruin by saying more):
You can read it while listening to the song here: (Spotify / Apple Music / Youtube)
Idagio: Classical Music Streaming, Paying by the Second
I haven’t been listening to as much classical music ever since I transitioned form CDs to streaming years ago. Spotify and Apple Music don’t do a great job with classical music, both in how the UI is constructed and the meta-data that they have.
It used to be easier to just look at the CDs I had on the shelf and pick what I wanted to listen to. Now, everything’s hard to find and scattered across my digital collection (I could do a lot more curation by hand, but just re-finding the recordings I want can be challenging). If you don’t have photographic memory for the name of conductors and performers and composers, it’s easy to forget about some recordings you like because they’re easier to lose in the digital haystack (especially if you have thousands of albums of other genres like me).
Martin Michel on Twitter recommended Idagio.
I think I had heard the name a few times before, but had never taken the time to check it out, in part because I didn’t want to pay for another streaming service on top of Apple Music just for when I feel like listening to classic. But Martin mentioned there’s a free tier, and that made me curious enough to give it a try.
So far, it’s very nice. Clean interface, the metadata seems very good, and since they focus on classical, everything in the UX is tailored to what you need to find what you want.
What I found most interesting, though, is one of the ads I heard. It explained that they pay artists by the second, not per track played, so even if you don’t listen to something fully, or if you listen to only one track that is 35 minutes long, artists and performers get a fair share of the time that you listened.
It made me wonder if this would be a good model for Spotify/Apple Music. Right now there’s kind of the opposite incentive, to have short tracks that can be replayed more often to get more listens, as opposed to longer, more complex works. I don’t know…
Maybe a hybrid of the two would be fairest and avoid distorting things too far in one direction or the other (ie. 50% of the money split by plays, 50% by duration).
Anyway, if you want to give it a try but don’t know what to listen to, I recommend George Lepauw’s performance of Bach’s Das Wohltemperierte Klavier (The Well-Tempered Clavier) from 2017.
"Ideally they would create some way for big podcasts to partner into their service, and offer ad-free and/or bonus content to subscribers"
I wrote a bit about this in a post on how Tencent Music generates revenue in China. While the whole post is good for setting context on how different Tencent Music's monetization is compared to Spotify, control+F for the "Spotify Social" section to see the section particularly relevant to your comment above.
TL/DR right now in the west, a lot of podcasts monetize a premium feed via Patreon, etc. That should be native to the podcast players.
https://eastmeetswest.substack.com/p/tencent-music